 视美泰多模态融合+姿态感知技术,让机器真正 “读懂” 世界
视美泰多模态融合+姿态感知技术,让机器真正 “读懂” 世界

如果说传统监控是记录世界的"眼睛",那么融合了多模态融合算法与姿态估计算法的视美泰解决方案,则是一颗能理解物理世界的"大脑"。它不再局限于单一的视觉识别,而是通过多维感知与逻辑判断,让冰冷的机器拥有了近乎人类的场景洞察与行为解析能力。
超越视觉,多模态融合让决策更"聪明"
在复杂的实际场景中,仅靠图像识别往往会产生误报。视美泰在AI算法架构中引入了多模态融合算法思想,将视觉流(RGB/红外)、音频流、甚至毫米波传感数据在特征层进行融合。例如在智能监护场景中,系统会结合人体姿态估计与语音识别来判断异常——当监测到人员跌倒姿态的同时捕捉到求救声纹,才会触发紧急告警。在AI智能美妆镜等交互产品中,方案融合了人脸关键点检测(视觉)与语音指令(听觉),通过多模态交互实现"指哪化哪"的无感体验。这种融合机制极大提升了在复杂光照、遮挡环境下的识别鲁棒性,让AI服务从被动响应升级为主动感知。
读懂肢体语言,姿态估计重塑行为分析边界
姿态估计算法是视美泰行为分析技术的核心基座。通过实时追踪人体关键点(如头、肩、肘、膝),视美泰算法库不仅能识别人体位置,更能精准定义"行为逻辑"。
在智慧工地场景,系统不仅能识别"是否戴安全帽",更能通过姿态估计判断"是否处于安全操作姿态";在智慧校园,算法能毫秒级区分"正常行走"、"快速奔跑"与"攀爬围墙";在零售场景,结合肢体动作与驻留时长,算法能过滤掉店员误识别,精准捕捉消费者的购物意向。

视美泰的姿态估计算法针对边缘端算力做了深度剪枝,即使运行在低功耗主板上也能实现毫秒级响应,让行为监测兼具实时性与准确性。
视美泰AI算法产品矩阵
| 算法类型 | 代表产品 |
| 人脸识别 | 人脸识别-商显、人脸识别-人证 |
| 行为分析 | 动作识别、跌倒检测、求救检测、攀爬检测 |
| 安全生产 | 安全帽检测、工服检测、烟火检测 |
| 车辆管理 | 车牌识别、车辆检测 |
| 零售创新 | 商品识别 |
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
人工智能
+关注
关注
1820文章
50360浏览量
267015 -
计算机视觉
+关注
关注
9文章
1716浏览量
47724 -
行为分析
+关注
关注
0文章
38浏览量
2192 -
视美泰
+关注
关注
0文章
20浏览量
128
发布评论请先 登录
相关推荐
热点推荐
海康威视推出森林防火多模态智能研判大模型产品
海康威视公共服务行业软件特推出森林防火多模态智能研判大模型产品,依托海康威视观澜大模型能力,对不同等级的火情分类处理,减少90%的无效告警² ,让
智能机器人从0到1系统入门课程 带源码课件 百度网盘下载
的深度理解。然而,未来的机器人交互必然是多模态融合的——即“听觉”与“视觉”的深度协同。通过结合语音识别与视觉识别技术,我们不仅能赋予
发表于 04-11 16:41
【置顶公告】视美泰开源鸿蒙系列产品业务咨询与商务合作通道正式开启!
优势技术背书:视美泰是OpenHarmony生态核心合作伙伴,拥有多款认证产品及行业解决方案。
快速响应:专属商务团队提供一对一需求对接,72小时内反馈
发表于 10-20 16:23
机器人竞技幕后:磁传感器芯片激活 “精准感知力”
2025 世界人形机器人运动会于 8 月 17 日圆满收官,赛场上机器人在跑步、跳跃、抓取等项目中的精彩表现,背后是运动控制、环境感知等技术
发表于 08-26 10:02

360环视技术推荐的硬件平台:支持多摄像头与三屏异显的理想选择
实现物体检测、避障判断、自动路径规划等功能。如今,这项技术已经广泛应用于自动泊车系统、智能座舱显示、无人配送机器人、物流AGV小车等多个领域,成为“让设备更聪明”的关键感知环节。
发表于 07-30 17:32
飞凌嵌入式RK3576多模态大模型图像理解助手,让嵌入式设备“看懂”世界
(LLM)+视觉语言模型(VLM)多模态架构,推出多模态大模型图像理解助手,为嵌入式设备打造 “智能视觉中枢”,让终端设备能够

NVIDIA助力图灵新讯美推出企业级多模态视觉大模型融合解决方案
中国推出企业级多模态视觉大模型融合解决方案,推动先进 AI 模型在交通治理、工业质检、金融风控等领域实现高效识别、精准预警和稳定交付。
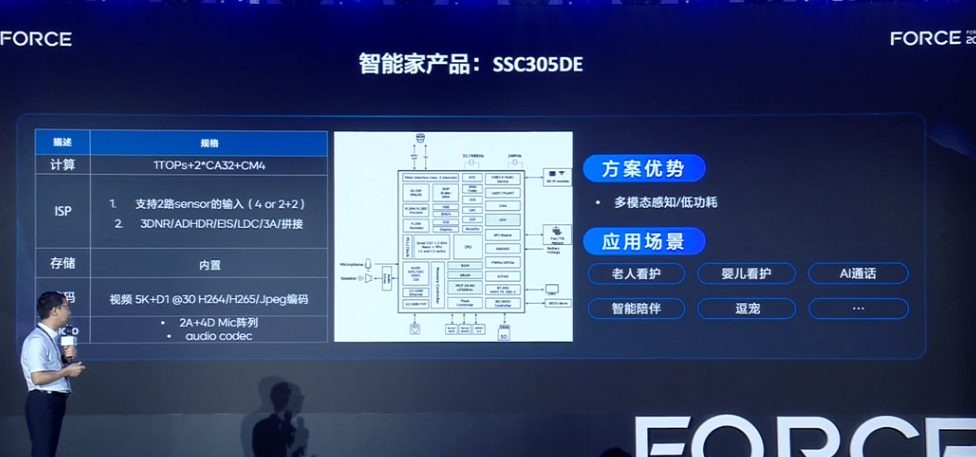
多模态感知+豆包大模型!家居端侧智能升级
电子发烧友网报道(文/李弯弯)日前,在火山引擎2025春季FORCE原动力大会上,星宸科技股份有限公司董事副总经理陈立敬谈到,在人工智能技术飞速发展的时代,多模态感知与大模型的
新品 | 视美泰发布高性价比四核工控主板GK-68A,开启智能工业新时代!
在工业智能化浪潮汹涌澎湃的当下,视美泰凭借深厚的技术积累与敏锐的市场洞察力,再度发力,正式推出全新力作——GK-68A工控主板,为工业自动化、智能终端、电力能源管理以及物联网通信等多个

新品 | 视美泰发布高性价比4K超高清数字标牌主板DS-660A
4K超高清数字标牌主板,为智能终端产品的开发注入全新活力!·关于视美泰·深圳市视美泰




评论