 净利暴涨156%!英特尔释出Q1财报“王炸”,CPU迎史诗级“价值回归”?
净利暴涨156%!英特尔释出Q1财报“王炸”,CPU迎史诗级“价值回归”?

电子发烧友网报道(文/席安帝)在AI大模型“一路狂奔”的时代,凭借GPU持续统治AI算力“江湖”的英伟达,曾一路将英特尔远远甩在身后。
但随着AI推理应用的爆发,英伟达也面临传统AI训练用GPU业务被逐步稀释,推理侧业务被越来越多客户以ASIC“抢夺”的局面。而英特尔反而借助AI Agent应用对并发调度能力需求的暴增开始“逆风翻盘”,作为Agentic AI性能提升最大瓶颈的CPU,也由此迎来了史诗级的“价值重构”。
英特尔最新公布的业绩也充分印证了这一点。当地时间2026年4月23日,英特尔交出了一份亮眼的财报,2026财年第一季度营收为136亿美元,同比增长7%,连续第6个季度超预期;数据中心与AI业务收入高达51亿美元,同比飙升22%,代工业务收入高达54亿美元,大涨16%;在Non-GAAP(非通用会计准则)口径下,归属于英特尔的净利润达15亿美元,较上年同期的6亿美元增长156%。
同时,英特尔也给出了第二季度的业绩指引,英特尔预测2026年第二季度营收为138亿美元至148亿美元,这一指引也超出了市场预期,充分说明英特尔整体正逐步走出低谷期,实现真正意义上的“价值回归”。
从训练、推理到Agent:CPU重返AI计算时代“主线”?
如果说AI训练和推理时代的主线是“GPU+ASIC”,那么Agentic AI时代CPU或将比GPU和ASIC更加重要,大有抢占核心主位的趋势。
毕竟,AI Agent运行在沙盒化的通用计算机环境中,这一执行形态决定了其工作负载天然呈现高度分支化与强控制流特征。以全球首个真正意义上的AI Agent——Manus为例,Manus会为每个Agent任务分配一个完全隔离的云端虚拟机,其中包含网络、文件系统、浏览器和开发工具,不同任务在逻辑上高度异构(如网页浏览、代码修改、环境部署等),任务之间可并行但控制流完全不同。
AI Agent常见的分支类任务并不适合由GPU执行,控制流发散容易导致算力利用率急剧下降。英伟达在其CUDA官方文档中就明确指出,GPU采用的是SIMT执行模型,即线程以32个为一组(warp),在同一周期内执行同一条指令。一旦同一 warp 内线程进入不同分支路径(Warp Divergence), GPU 会将不同分支串行执行,不属于当前分支的线程被 mask 掉,直接导致吞吐下降。
Science Direct收录的并行计算/GPU架构期刊(Parallel Computing 、Journal of Parallel and Distributed Computing 等)中关于 warp divergence(分支发散)的实验结果显示,即便是有限程度的分支发散(2–16 路分支),也会显著拉长执行时间,比如4路分支发散执行时间会增加3-6倍(数据摘自IEEE论文——IEEE TPDS, 2020)。在32路极端发散(完全发散)的情况下,执行时间增加 30–130 倍,算力利用率降至 1%–5%(源自Parallel Computing (2022)、JPDC (2023) 中的极端场景测试),等效算力利用率仅剩个位数百分比。因此,AI Agent这类高度分支类的任务实际上并不适合由GPU执行,反而是GPU编程中需要避免的情形。
相比GPU来说,CPU为复杂控制流而生,天然适配Agent的执行特征。东吴证券研究所的研报显示,现代主流服务器CPU(如 AMD EPYC、Intel Xeon)均属于典型 MIMD架构——每个核心拥有独立的程序计数器、指令缓存与解码逻辑,不同核心可完全独立执行不同控制流。微架构层面,CPU 专门为复杂逻辑分支进行了长期演进,在真实的通用程序中,平均每 5–7 条指令就包含一次条件分支,若要维持性能,分支预测准确率需达到“95%+”。现代 CPU 通过复杂分支预测器(如 TAGE、感知器)、乱序执行、重排序缓冲区(ROB)等机制,在通用代码中可实现1–2.5 IPC 的稳定吞吐。因此,Agent 的“行动”阶段本质是大量 if/else 判断、系统调用与串行决策,这些正是 CPU 微架构长期优化的主战场。
除此之外,在Agent场景下,长上下文推理会产生巨大的KV cache(键值缓存),其占用随对话轮次与上下文长度线性增长,会快速耗尽GPU HBM容量。业界论文如HiFC等指出KV cache已成为长上下文LLM推理的首要内存瓶颈,并探索通过CPU DRAM等来承载KV cache。从成本上来讲,完全依靠GPU HBM来承载KV cache带来的成本增加越来越显著。因此,Agent 场景应用当下的最优解似乎正在收敛为“GPU 负责计算、CPU 以大容量 DDR5/LPDDR5(并可通过CXL扩展)承载上下文与参数”的混合架构。
显而易见,CPU正在成为Agentic AI实际应用中的真实瓶颈。在Agentic AI场景下,CPU侧工作负载呈现爆发式增长,并已成为系统性能的核心约束。美国佐治亚理工学院和 Intel 在去年底共同发布的一篇论文——《A CPU-Centric Perspective on Agentic AI》中,对 Haystack RAG、Toolformer、ChemCrow、LangChain、SWE-Agent 等 Agentic AI的工作流进行了系统级测试。
研究显示,在完整的Agent执行链路中,工具处理相关环节(检索、Python/Bash 执行、Web 请求等)在 CPU 上消耗的时间占端到端延迟的比例最高可达 90.6%。在高并发场景下(Batch Size 提升至 128), CPU 端到端延迟从 2.9 秒跃升至 6.3 秒以上,增幅超过2倍。其根本原因是并发负载超出 CPU 物理核心上限后,上下文切换与线程同步带来的巨额开销,会造成处理器资源严重过载。
因此,Agentic AI的性能提升瓶颈正集中转向 CPU 的并发调度能力方面。东吴证券研究所认为,佐治亚理工大学和英特尔共同的研究结果揭示了在大量Agentic 场景中,系统吞吐受限的并非GPU计算能力,而是CPU的核心数并发调度问题。由此便可以判断,进入Agent时代后,CPU 侧的工具执行与调度能力将从 GPU 的附属角色,演化为需要被单独规划与优化的核心资源池。CPU 不再只是推理调度器,而是决定 Agent 系统并发上限与服务能力的关键基础设施,其配置与规模将直接约束Agentic AI 的实际落地效率与商业化能力。
CPU重返AI计算时代主线,英特尔官方也颇为认可这一演变,英特尔2026年第一季度的强劲业绩便反映了CPU在AI时代日益重要且不可或缺的作用,就连英特尔首席执行官陈立武都指出:“新一轮的人工智能浪潮将推动智能更贴近终端用户,其演进路径从基础模型走向推理,再迈向智能体阶段。这一转变正显著增加市场对英特尔CPU、晶圆及先进封装产品的需求。”
CPU地位“大反转”,英伟达都坐不住了?
在过去,传统的互联网应用(如抖音/快手短视频以及各类抢票软件等)大多都更加看重CPU处理器的单核响应速度,强调“高并发和短连接”。但随着AI大模型技术的飞速发展,用户需求逐步从传统的AIGC单线功能转向Agent甚至Agentic AI类应用,负责执行这类应用的工作负载呈现出高并发、长任务以及注重隔离的特征,为能够同时承载成千上万的虚拟机/沙箱系统,AI服务器往往更注重并行吞吐与单位任务的执行成本,并非单核的频率,这种需求的结构性变化也使得CPU架构的重心不得不从强调单核性能转向“超多核+能效核”的技术路线。
这一变化已经在全球的CPU头部大厂的产品规划路线中得到了充分的验证。2024年10月9日,AMD 在美国旧金山举行的 Advancing AI 活动期间便发布了第 5 代 EPYC CPU(代号为 Turin),最高可多达192核,主打高密度计算与并行吞吐特性;Intel甚至更为激进,其 Sierra Forest 处理器的核心数甚至可达 144 甚至 288 核,堪称“能效巨兽”。
在满足固有特性的基础上,为了进一步适应Agent应用场景中对低成本、低功耗和高任务响应与执行速度的需求。CPU也在向“超多核+能效核”持续纵深发展,这也将彻底改变CPU在AI Agent时代的命运,使其以更高的并行度、更低的单位功耗,全方位支撑大规模、长期运行的Agent执行环境。
CPU地位的“升华”,也让一直以来以高算力GPU“打天下”的AI芯片巨头英伟达做出了让步。英伟达在GB200 NVL72这一新架构中,就维持了“CPU:GPU”为“1:2”的策略。根据英伟达官方技术文档显示,GB200 Grace Blackwell Superchip 标准配置为 “1颗 Grace CPU + 2 颗 Blackwell GPU”,单个NVL72 整机柜共 36 个 Superchip,总计 “36个 CPU : 72个 GPU”,严格遵循 1:2的比例配置在统一的内存体系之下。在GB200架构中,Grace CPU侧最高可配置480GB LPDDR5X,并通过NVLinkC2C 与GPU 侧HBM3e组成统一地址空间,使GPU能够直接访问CPU内存。根据英伟达技术文档披露,该设计目标正是让GPU可以oversubscribe 本地显存,将超出HBM容量的工作集放置于CPU 内存中继续执行。
相比之下,传统GPU服务器架构通常采用“2颗x86 CPU + 8 颗 GPU的配置”,比如DGX H100 标配“2 颗 Intel Xeon 8480C CPU + 8 颗 H100 GPU”,配比 1:4。其中,CPU 仅负责调度、存储与外围 I/O,不参与核心 AI 计算,对应约“1:4”的“CPU:GPU” 配比,CPU角色更多限于调度与外围支撑。
从“1:4”的配比到“1:2”的转变,也足以说明英伟达开始重点关注CPU在Agent应用中所能发挥的关键能力。这一调整也直指Agent场景的核心痛点——上下文持续拉长,KV Cache规模快速膨胀,在该模式下,Grace CPU 所搭载的大容量、高带宽内存实际承担了Agent的“短期记忆”角色。NVIDIA通过主动提升CPU权重,似乎也是在对外界释放一个信号,即在长上下文与高并发 Agent 场景中,大内存CPU是承载海量KV Cache的最优容器,而 GPU更适合专注于计算本身。由此可见,AI Agent时代,地位正全面反转的CPU,将成为接下来AI算力中心的核心控制与记忆管理中枢。
业绩或迎史诗级爆发:2026成CPU厂商“关键年”?
从英特尔公布的Q1财报中可以发现,英特尔数据中心和人工智能事业部(DCAI)在2026年Q1营收高达51亿美元,相比2025年Q1增长了22%。且从英特尔给出的第二季度的业绩指引,预测2026年第二季度营收为138亿美元至148亿美元,也足见英特尔对接下来的业绩增长充满信心。
作为国际CPU巨头,英特尔的业绩表现以及做出的业绩指引,对于越来越多深耕国产CPU赛道的本土芯片厂商也颇具参考性。随着AI Agent时代CPU地位的提升,加之算力产业的高速发展,一众国产芯片厂商也将有望借助这一周期性的“大势”在业绩层面实现大幅增长,为国产AI算力赋能。
现阶段,国内CPU市场呈现“多指令集路线并行”的格局,华为、飞腾、海光、兆芯、龙芯、阿里等企业分别基于X86、ARM、RISC-V、LoongArch展开激烈竞争,在自主可控与生态建设方面不断取得新突破。
也正是得益于国内AI算力市场的飞速发展,多家国产CPU在2025年的业绩表现良好:
1.海光信息作为国内CPU领域的“带头大哥”,近年来公司技术和业绩双双呈现高速发展态势。目前,海光信息旗下的产品包括海光通用处理器(CPU)和海光协处理器(DCU)。CPU系列产品兼容x86指令集以及国际上主流操作系统和应用软件,已经广泛应用于电信、金融、互联网、教育、交通等重要行业或领域。DCU系列产品以GPGPU架构为基础,可广泛应用于大数据处理、人工智能、大模型训练及推理、商业计算等应用领域。
得益于AI算力的爆发及数字基建的升级,海光信息在2025年也斩获了丰硕的业绩。根据海光信息2025年年报,海光信息2025年营收高达143.77亿元,同比增长56.92%,高端处理器是公司主要营收来源,其毛利率为57.78%。归母净利润方面2025年高达25.45亿元,同比增长31.79%。
2.龙芯中科作为国内唯一坚持基于自主指令系统构建独立于x86体系和ARM体系的开放性信息技术体系产业生态的CPU企业,旗下产品线丰富,主要分为龙芯1号MCU系列、龙芯2号SoC系列、龙芯3号CPU系列和和处理器配套使用的桥片等。
2025年龙芯中科整体业务展现出稳步回升的良好态势,根据龙芯中科2025年年度业绩预告披露的信息显示,预计2025年年度公司实现营业收入6.35亿元左右,比上年同期增长26%左右。龙芯中科2025年收入增量来源于以下几个方面:一是服务器业务2025年下半年已经开始有典型场景应用场景,2026年会加速落地;第二,凭借龙架构自主化的优势,龙芯中科去年成功开展对外授权,在不同细分领域的IP授权业务也会成为龙芯的增量;第三,工控领域正持续发挥新产品的性价比优势,也在逐步走向开放市场。
3.上海兆芯是目前国内领先的可同时面向桌面 PC、服务器、工作站以及嵌入式等多领域并持续兼容x86指令集的CPU设计企业。截至招股书签署日,上海兆芯已成功设计研发并量产六代、多系列通用处理器,并形成“开先”系列桌面PC/嵌入式处理器、“开胜”系列服务器处理器两大产品系列。目前,联想、软通计算机、公司D、紫光、升腾、视源、长城、海尔、东海信息、宝德等国内知名桌面PC、服务器厂商均已推出搭载兆芯CPU芯片的整机产品。
根据上海兆芯招股说明书信息显示,2025年公司实现营业收入超11.11亿元,同比增长约35.37%。2025年,“开先”系列桌面PC/嵌入式处理器出货量超235万颗,同比增长约28.86%;“开胜”系列服务器处理器出货量约2.2万颗。
除此之外,国内还有天津飞腾信息、电科申泰、阿里、华为等多家企业在CPU技术领域开疆拓土。比如华为计算产业采用硬件开放、软件开源策略,自2019年开放鲲鹏服务器主板以来,已发展6800家伙伴;飞腾确立“通算+智算”双轮驱动战略,加速构建“CPU(中央处理器)+XPU(异构融合处理器)”自主算力体系;阿里巴巴达摩院则借助RISC-V之力不断深耕CPU领域。
总结
伴随着AI Agent时代的来临,传统GPU的地位或将被削弱,而沉寂已久的CPU则将顺势“上位”,承担起AI算力中心的核心控制与记忆管理中枢的重要任务。英特尔2026年Q1的业绩表现,无疑为CPU今年在全球AI数据中心领域的增长释放了重磅利好,也为更多CPU国产企业的业绩增长指明了方向。随着越来越多国家单位以及AI科技巨头加速算力领域的扩张,CPU的需求和价格接下来有望“水涨船高”,从而带动全球CPU企业在2026年实现业绩与出货量的双“丰收”。
但随着AI推理应用的爆发,英伟达也面临传统AI训练用GPU业务被逐步稀释,推理侧业务被越来越多客户以ASIC“抢夺”的局面。而英特尔反而借助AI Agent应用对并发调度能力需求的暴增开始“逆风翻盘”,作为Agentic AI性能提升最大瓶颈的CPU,也由此迎来了史诗级的“价值重构”。
英特尔最新公布的业绩也充分印证了这一点。当地时间2026年4月23日,英特尔交出了一份亮眼的财报,2026财年第一季度营收为136亿美元,同比增长7%,连续第6个季度超预期;数据中心与AI业务收入高达51亿美元,同比飙升22%,代工业务收入高达54亿美元,大涨16%;在Non-GAAP(非通用会计准则)口径下,归属于英特尔的净利润达15亿美元,较上年同期的6亿美元增长156%。
同时,英特尔也给出了第二季度的业绩指引,英特尔预测2026年第二季度营收为138亿美元至148亿美元,这一指引也超出了市场预期,充分说明英特尔整体正逐步走出低谷期,实现真正意义上的“价值回归”。
从训练、推理到Agent:CPU重返AI计算时代“主线”?
如果说AI训练和推理时代的主线是“GPU+ASIC”,那么Agentic AI时代CPU或将比GPU和ASIC更加重要,大有抢占核心主位的趋势。
毕竟,AI Agent运行在沙盒化的通用计算机环境中,这一执行形态决定了其工作负载天然呈现高度分支化与强控制流特征。以全球首个真正意义上的AI Agent——Manus为例,Manus会为每个Agent任务分配一个完全隔离的云端虚拟机,其中包含网络、文件系统、浏览器和开发工具,不同任务在逻辑上高度异构(如网页浏览、代码修改、环境部署等),任务之间可并行但控制流完全不同。
AI Agent常见的分支类任务并不适合由GPU执行,控制流发散容易导致算力利用率急剧下降。英伟达在其CUDA官方文档中就明确指出,GPU采用的是SIMT执行模型,即线程以32个为一组(warp),在同一周期内执行同一条指令。一旦同一 warp 内线程进入不同分支路径(Warp Divergence), GPU 会将不同分支串行执行,不属于当前分支的线程被 mask 掉,直接导致吞吐下降。
Science Direct收录的并行计算/GPU架构期刊(Parallel Computing 、Journal of Parallel and Distributed Computing 等)中关于 warp divergence(分支发散)的实验结果显示,即便是有限程度的分支发散(2–16 路分支),也会显著拉长执行时间,比如4路分支发散执行时间会增加3-6倍(数据摘自IEEE论文——IEEE TPDS, 2020)。在32路极端发散(完全发散)的情况下,执行时间增加 30–130 倍,算力利用率降至 1%–5%(源自Parallel Computing (2022)、JPDC (2023) 中的极端场景测试),等效算力利用率仅剩个位数百分比。因此,AI Agent这类高度分支类的任务实际上并不适合由GPU执行,反而是GPU编程中需要避免的情形。
相比GPU来说,CPU为复杂控制流而生,天然适配Agent的执行特征。东吴证券研究所的研报显示,现代主流服务器CPU(如 AMD EPYC、Intel Xeon)均属于典型 MIMD架构——每个核心拥有独立的程序计数器、指令缓存与解码逻辑,不同核心可完全独立执行不同控制流。微架构层面,CPU 专门为复杂逻辑分支进行了长期演进,在真实的通用程序中,平均每 5–7 条指令就包含一次条件分支,若要维持性能,分支预测准确率需达到“95%+”。现代 CPU 通过复杂分支预测器(如 TAGE、感知器)、乱序执行、重排序缓冲区(ROB)等机制,在通用代码中可实现1–2.5 IPC 的稳定吞吐。因此,Agent 的“行动”阶段本质是大量 if/else 判断、系统调用与串行决策,这些正是 CPU 微架构长期优化的主战场。
除此之外,在Agent场景下,长上下文推理会产生巨大的KV cache(键值缓存),其占用随对话轮次与上下文长度线性增长,会快速耗尽GPU HBM容量。业界论文如HiFC等指出KV cache已成为长上下文LLM推理的首要内存瓶颈,并探索通过CPU DRAM等来承载KV cache。从成本上来讲,完全依靠GPU HBM来承载KV cache带来的成本增加越来越显著。因此,Agent 场景应用当下的最优解似乎正在收敛为“GPU 负责计算、CPU 以大容量 DDR5/LPDDR5(并可通过CXL扩展)承载上下文与参数”的混合架构。
显而易见,CPU正在成为Agentic AI实际应用中的真实瓶颈。在Agentic AI场景下,CPU侧工作负载呈现爆发式增长,并已成为系统性能的核心约束。美国佐治亚理工学院和 Intel 在去年底共同发布的一篇论文——《A CPU-Centric Perspective on Agentic AI》中,对 Haystack RAG、Toolformer、ChemCrow、LangChain、SWE-Agent 等 Agentic AI的工作流进行了系统级测试。
研究显示,在完整的Agent执行链路中,工具处理相关环节(检索、Python/Bash 执行、Web 请求等)在 CPU 上消耗的时间占端到端延迟的比例最高可达 90.6%。在高并发场景下(Batch Size 提升至 128), CPU 端到端延迟从 2.9 秒跃升至 6.3 秒以上,增幅超过2倍。其根本原因是并发负载超出 CPU 物理核心上限后,上下文切换与线程同步带来的巨额开销,会造成处理器资源严重过载。
因此,Agentic AI的性能提升瓶颈正集中转向 CPU 的并发调度能力方面。东吴证券研究所认为,佐治亚理工大学和英特尔共同的研究结果揭示了在大量Agentic 场景中,系统吞吐受限的并非GPU计算能力,而是CPU的核心数并发调度问题。由此便可以判断,进入Agent时代后,CPU 侧的工具执行与调度能力将从 GPU 的附属角色,演化为需要被单独规划与优化的核心资源池。CPU 不再只是推理调度器,而是决定 Agent 系统并发上限与服务能力的关键基础设施,其配置与规模将直接约束Agentic AI 的实际落地效率与商业化能力。
CPU重返AI计算时代主线,英特尔官方也颇为认可这一演变,英特尔2026年第一季度的强劲业绩便反映了CPU在AI时代日益重要且不可或缺的作用,就连英特尔首席执行官陈立武都指出:“新一轮的人工智能浪潮将推动智能更贴近终端用户,其演进路径从基础模型走向推理,再迈向智能体阶段。这一转变正显著增加市场对英特尔CPU、晶圆及先进封装产品的需求。”
CPU地位“大反转”,英伟达都坐不住了?
在过去,传统的互联网应用(如抖音/快手短视频以及各类抢票软件等)大多都更加看重CPU处理器的单核响应速度,强调“高并发和短连接”。但随着AI大模型技术的飞速发展,用户需求逐步从传统的AIGC单线功能转向Agent甚至Agentic AI类应用,负责执行这类应用的工作负载呈现出高并发、长任务以及注重隔离的特征,为能够同时承载成千上万的虚拟机/沙箱系统,AI服务器往往更注重并行吞吐与单位任务的执行成本,并非单核的频率,这种需求的结构性变化也使得CPU架构的重心不得不从强调单核性能转向“超多核+能效核”的技术路线。
这一变化已经在全球的CPU头部大厂的产品规划路线中得到了充分的验证。2024年10月9日,AMD 在美国旧金山举行的 Advancing AI 活动期间便发布了第 5 代 EPYC CPU(代号为 Turin),最高可多达192核,主打高密度计算与并行吞吐特性;Intel甚至更为激进,其 Sierra Forest 处理器的核心数甚至可达 144 甚至 288 核,堪称“能效巨兽”。
在满足固有特性的基础上,为了进一步适应Agent应用场景中对低成本、低功耗和高任务响应与执行速度的需求。CPU也在向“超多核+能效核”持续纵深发展,这也将彻底改变CPU在AI Agent时代的命运,使其以更高的并行度、更低的单位功耗,全方位支撑大规模、长期运行的Agent执行环境。
CPU地位的“升华”,也让一直以来以高算力GPU“打天下”的AI芯片巨头英伟达做出了让步。英伟达在GB200 NVL72这一新架构中,就维持了“CPU:GPU”为“1:2”的策略。根据英伟达官方技术文档显示,GB200 Grace Blackwell Superchip 标准配置为 “1颗 Grace CPU + 2 颗 Blackwell GPU”,单个NVL72 整机柜共 36 个 Superchip,总计 “36个 CPU : 72个 GPU”,严格遵循 1:2的比例配置在统一的内存体系之下。在GB200架构中,Grace CPU侧最高可配置480GB LPDDR5X,并通过NVLinkC2C 与GPU 侧HBM3e组成统一地址空间,使GPU能够直接访问CPU内存。根据英伟达技术文档披露,该设计目标正是让GPU可以oversubscribe 本地显存,将超出HBM容量的工作集放置于CPU 内存中继续执行。
相比之下,传统GPU服务器架构通常采用“2颗x86 CPU + 8 颗 GPU的配置”,比如DGX H100 标配“2 颗 Intel Xeon 8480C CPU + 8 颗 H100 GPU”,配比 1:4。其中,CPU 仅负责调度、存储与外围 I/O,不参与核心 AI 计算,对应约“1:4”的“CPU:GPU” 配比,CPU角色更多限于调度与外围支撑。
从“1:4”的配比到“1:2”的转变,也足以说明英伟达开始重点关注CPU在Agent应用中所能发挥的关键能力。这一调整也直指Agent场景的核心痛点——上下文持续拉长,KV Cache规模快速膨胀,在该模式下,Grace CPU 所搭载的大容量、高带宽内存实际承担了Agent的“短期记忆”角色。NVIDIA通过主动提升CPU权重,似乎也是在对外界释放一个信号,即在长上下文与高并发 Agent 场景中,大内存CPU是承载海量KV Cache的最优容器,而 GPU更适合专注于计算本身。由此可见,AI Agent时代,地位正全面反转的CPU,将成为接下来AI算力中心的核心控制与记忆管理中枢。
业绩或迎史诗级爆发:2026成CPU厂商“关键年”?
从英特尔公布的Q1财报中可以发现,英特尔数据中心和人工智能事业部(DCAI)在2026年Q1营收高达51亿美元,相比2025年Q1增长了22%。且从英特尔给出的第二季度的业绩指引,预测2026年第二季度营收为138亿美元至148亿美元,也足见英特尔对接下来的业绩增长充满信心。
作为国际CPU巨头,英特尔的业绩表现以及做出的业绩指引,对于越来越多深耕国产CPU赛道的本土芯片厂商也颇具参考性。随着AI Agent时代CPU地位的提升,加之算力产业的高速发展,一众国产芯片厂商也将有望借助这一周期性的“大势”在业绩层面实现大幅增长,为国产AI算力赋能。
现阶段,国内CPU市场呈现“多指令集路线并行”的格局,华为、飞腾、海光、兆芯、龙芯、阿里等企业分别基于X86、ARM、RISC-V、LoongArch展开激烈竞争,在自主可控与生态建设方面不断取得新突破。
也正是得益于国内AI算力市场的飞速发展,多家国产CPU在2025年的业绩表现良好:
1.海光信息作为国内CPU领域的“带头大哥”,近年来公司技术和业绩双双呈现高速发展态势。目前,海光信息旗下的产品包括海光通用处理器(CPU)和海光协处理器(DCU)。CPU系列产品兼容x86指令集以及国际上主流操作系统和应用软件,已经广泛应用于电信、金融、互联网、教育、交通等重要行业或领域。DCU系列产品以GPGPU架构为基础,可广泛应用于大数据处理、人工智能、大模型训练及推理、商业计算等应用领域。
得益于AI算力的爆发及数字基建的升级,海光信息在2025年也斩获了丰硕的业绩。根据海光信息2025年年报,海光信息2025年营收高达143.77亿元,同比增长56.92%,高端处理器是公司主要营收来源,其毛利率为57.78%。归母净利润方面2025年高达25.45亿元,同比增长31.79%。
2.龙芯中科作为国内唯一坚持基于自主指令系统构建独立于x86体系和ARM体系的开放性信息技术体系产业生态的CPU企业,旗下产品线丰富,主要分为龙芯1号MCU系列、龙芯2号SoC系列、龙芯3号CPU系列和和处理器配套使用的桥片等。
2025年龙芯中科整体业务展现出稳步回升的良好态势,根据龙芯中科2025年年度业绩预告披露的信息显示,预计2025年年度公司实现营业收入6.35亿元左右,比上年同期增长26%左右。龙芯中科2025年收入增量来源于以下几个方面:一是服务器业务2025年下半年已经开始有典型场景应用场景,2026年会加速落地;第二,凭借龙架构自主化的优势,龙芯中科去年成功开展对外授权,在不同细分领域的IP授权业务也会成为龙芯的增量;第三,工控领域正持续发挥新产品的性价比优势,也在逐步走向开放市场。
3.上海兆芯是目前国内领先的可同时面向桌面 PC、服务器、工作站以及嵌入式等多领域并持续兼容x86指令集的CPU设计企业。截至招股书签署日,上海兆芯已成功设计研发并量产六代、多系列通用处理器,并形成“开先”系列桌面PC/嵌入式处理器、“开胜”系列服务器处理器两大产品系列。目前,联想、软通计算机、公司D、紫光、升腾、视源、长城、海尔、东海信息、宝德等国内知名桌面PC、服务器厂商均已推出搭载兆芯CPU芯片的整机产品。
根据上海兆芯招股说明书信息显示,2025年公司实现营业收入超11.11亿元,同比增长约35.37%。2025年,“开先”系列桌面PC/嵌入式处理器出货量超235万颗,同比增长约28.86%;“开胜”系列服务器处理器出货量约2.2万颗。
除此之外,国内还有天津飞腾信息、电科申泰、阿里、华为等多家企业在CPU技术领域开疆拓土。比如华为计算产业采用硬件开放、软件开源策略,自2019年开放鲲鹏服务器主板以来,已发展6800家伙伴;飞腾确立“通算+智算”双轮驱动战略,加速构建“CPU(中央处理器)+XPU(异构融合处理器)”自主算力体系;阿里巴巴达摩院则借助RISC-V之力不断深耕CPU领域。
总结
伴随着AI Agent时代的来临,传统GPU的地位或将被削弱,而沉寂已久的CPU则将顺势“上位”,承担起AI算力中心的核心控制与记忆管理中枢的重要任务。英特尔2026年Q1的业绩表现,无疑为CPU今年在全球AI数据中心领域的增长释放了重磅利好,也为更多CPU国产企业的业绩增长指明了方向。随着越来越多国家单位以及AI科技巨头加速算力领域的扩张,CPU的需求和价格接下来有望“水涨船高”,从而带动全球CPU企业在2026年实现业绩与出货量的双“丰收”。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
英特尔
+关注
关注
61文章
10324浏览量
181094 -
cpu
+关注
关注
68文章
11331浏览量
225904 -
AI
+关注
关注
91文章
41156浏览量
302612 -
英特尔处理器
+关注
关注
3文章
46浏览量
11296
发布评论请先 登录
相关推荐
热点推荐
英特尔计划裁员21000人,可能跳过18A工艺
电子发烧友网报道(文/李弯弯)7月24日,英特尔公司正式发布2025年第二季度财报。数据显示,公司营收达128.6亿美元,同比增长0.2%,超出市场预期的118.8亿美元。然而,净利润
英特尔Q1业绩飙升:营收增7%股价暴涨58% 市值狂增1200亿
全球半导体巨头英特尔2026年第一季度财报表现亮眼,实现营收136亿美元,同比增长7%,创近三年同期最佳增速。更引人注目的是其股价连续9个交易日上涨,累计涨幅达58%,推动市值暴增超1200亿美元,凸显市场对英特尔复苏态势的强烈
英特尔 18A 良率跃升,普迪飞成核心攻坚力量|助力实现月度 7%-8% 稳定增长
合作回顾英特尔携手普迪飞,以数据协同重构半导体行业效率新标杆普迪飞&英特尔:数据驱动下的半导体良率优化实践深度合作落地:技术驱动半导体制造效率质量双提升英特尔召开2025年第四季度及全年财

英特尔CEO陈立武:18A 良率月增 7%-8% 成增长引擎,量产突破赋能 AI 全域扩张
英特尔Q4业绩超预期,但Q1指引疲软导致股价大跌。CEO陈立武坦言,“很失望无法完全满足市场需求”。尽管AI需求强劲,尤其是CPU在AI推理和编排中的关键作用正在推动超大规模云厂商的订
研报:英飞凌2026财年Q1财报透视与BASiC基本半导体国产化进阶之路
研报:英飞凌2026财年Q1财报透视与BASiC基本半导体国产化进阶之路 BASiC Semiconductor基本半导体一级代理商倾佳电子

18A良率承压!英特尔Q4营收超预期,下一季增长预期疲软
1月23日凌晨,英特尔披露的最新财报显示,2025年第四季度实现营收136.7亿美元,同比减少4.1%,略高于市场预估的134.3亿美元;第四季度调整后每股收益0.15美元,上年同期为
汽车级多路复用器TMUX13xxA - Q1:特性、应用与设计要点
汽车级多路复用器TMUX13xxA - Q1:特性、应用与设计要点 在汽车电子和工业自动化等领域,对于高性能、高可靠性的信号切换和复用解决方案的需求日益增长。德州仪器(TI)的TMUX13xxA
锐宝智联入选英特尔首批尊享级合作伙伴
近日,英特尔全球战略级生态计划---英特尔合作伙伴联盟完成里程碑式战略升级,原最高等级 “钛金级” 正式迭代为 “尊享级”,标志着

科通技术获评英特尔首批尊享级合作伙伴
近日,科通科技获评为英特尔首批“尊享级合作联盟成员”,即英特尔合作伙伴联盟体系中的最高级别会员。这一身份认证不仅是对双方十五年深度协同的认可,也是双方在技术协同、产业赋能道路上的又一次深度绑定。

吉方工控获评英特尔首批尊享级合作伙伴
近日,英特尔公司正式宣布对英特尔合作伙伴联盟(Intel Partner Alliance, IPA)进行战略升级,原最高等级“钛金级”全面焕新为更具全球视野与生态协同意义的“尊享级”
英特尔的“变”与“稳”:在代工战局中寻找自己的节奏
重振英特尔的厚望。因此,这份财报也不仅是一组财务数字,也代表着战略调整的初次落地。 而在经营层面,英特尔交出的也称得上是一份“止血中的企稳”:Q
英特尔2025财年Q2业绩优于预期,CEO宣布大幅削减代工厂投资
7月24日,国际芯片大厂英特尔发布2025财年第二季度财报,公司单季营收超越预期,但是公司仍然面临亏损,新任CEO陈立武通过致员工信,表示英特尔正积极实施一系列策略调整,目的在恢复其市

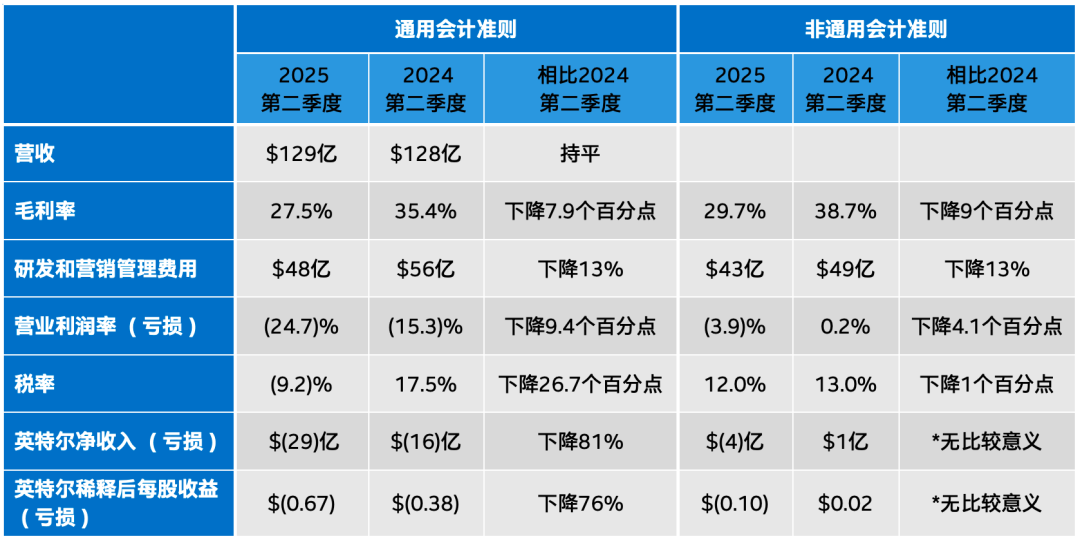
英特尔2025年第二季度财报表现稳健,战略调整初见成效
美国当地时间7月24日,英特尔发布了第二季度财报,营收达129亿美元,超出预期指引区间上限,与去年同期持平。尽管面临挑战,公司通过精简组织、优化资本配置和聚焦核心业务,展现出强大的执行力。 英
主控CPU全能选手,英特尔至强6助力AI系统高效运转
2025年3月,英伟达发布了DGX B300 AI加速计算平台。2025年5月,英特尔发布了三款全新英特尔至强6性能核处理器,其中一款6776P被用作是DGX B300的主控CPU,这款处理器究竟

英特尔发布全新GPU,AI和工作站迎来新选择
英特尔推出面向准专业用户和AI开发者的英特尔锐炫Pro GPU系列,发布英特尔® Gaudi 3 AI加速器机架级和PCIe部署方案 2025 年 5 月 19 日,北京 ——今日
发表于 05-20 11:03
•1917次阅读



评论