 Kubernetes Pod启动失败的各种场景及其排障方法
Kubernetes Pod启动失败的各种场景及其排障方法

背景
在 Kubernetes 日常运维中,Pod 起不来是最常见的故障形态之一。很多运维工程师看到 Pod 状态不是Running时,第一反应是盯着kubectl get pod的STATUS列反复查看,或者反复执行kubectl describe pod期待找到答案。殊不知,Pod 的非 Running 状态有几十种,每种状态的根因和处理方法完全不同。
本文以 Kubernetes 1.32(2026 年主流版本)为基础,系统讲解 Pod 启动失败的各种场景及其排障方法。内容覆盖 Pod 生命周期的完整解析、容器镜像相关问题、资源不足导致的调度失败、存储挂载异常、网络配置问题、以及使用 kubectl 和 crictl 工具进行深度排障的技巧。
前置知识要求:了解 Kubernetes 基本概念(Pod、Deployment、Service、Namespace)、熟悉 kubectl 基础命令、了解 Docker/容器基础知识。
1. Pod 生命周期与状态解析
1.1 Pod 生命周期阶段
Pod 的生命周期分为多个阶段(phase),通过status.phase字段表示:
# kubectl get pod -o yaml 中的 Pod 状态 status: phase:Running# Pending | Running | Succeeded | Failed | Unknown conditions: -type:Initialized # 初始化容器是否完成 status:"True" -type:Ready # Pod 是否可以接收流量 status:"True" -type:ContainersReady # 所有容器是否就绪 status:"True" -type:PodScheduled # 是否已调度到节点 status:"True"
Phase 与 Conditions 的关系:
Pending+PodScheduled=False→ 调度失败
Pending+Initialized=False→ 初始化容器失败
Pending+ContainersReady=False→ 容器启动失败
Running+Ready=False→ 存活探针失败
Failed→ 容器进程退出且未配置 restartPolicy
1.2 Pod 状态快速诊断
#!/bin/bash
# k8s_pod_status_diag.sh
# Pod 状态快速诊断脚本
POD_NAME="${1:-}"
NAMESPACE="${2:-default}"
if[ -z"$POD_NAME"];then
echo"用法:$0 [命名空间]"
exit1
fi
echo"========================================"
echo"Pod 状态诊断"
echo"Pod:$POD_NAME"
echo"命名空间:$NAMESPACE"
echo"时间:$(date '+%Y-%m-%d %H:%M:%S')"
echo"========================================"
echo""
# 获取 Pod 概要信息
echo"【Pod 概要】"
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o wide
echo""
# 获取 Pod 详细信息
echo"【Pod 详细状态】"
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o yaml | grep -A 20"status:"
echo""
# 获取最近事件
echo"【相关事件】"
kubectl get events -n"$NAMESPACE"
--field-selector involvedObject.name="$POD_NAME"
--sort-by='.lastTimestamp'| tail -20
echo""
# 获取容器状态
echo"【容器状态】"
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.status.containerStatuses[*]}'| python3 -m json.tool 2>/dev/null ||
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.status.containerStatuses}'
echo""
# 检查容器重启次数
echo"【容器重启统计】"
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.status.containerStatuses[*].restartCount}'
echo""
1.3 常见 Pod 状态速查
| STATUS | 含义 | 常见根因 |
|---|---|---|
| Pending | Pod 已创建但未调度到节点 | 资源不足、节点选择器不匹配、调度器故障 |
| ContainerCreating | 容器正在创建中 | 镜像拉取中、存储挂载中 |
| Running | 容器已启动 | 但需检查Ready状态和探针 |
| CrashLoopBackOff | 容器反复崩溃重启 | 应用启动失败、配置错误、资源不足 |
| ImagePullBackOff | 镜像拉取失败 | 镜像不存在、认证失败、网络不通 |
| ErrImagePull | 镜像拉取错误 | 同上,但处于早期阶段 |
| Evicted | Pod 被驱逐 | 资源压力、节点 drain |
| Terminating | 正在删除 | finalizers 未完成、force kill 失败 |
| Unknown | 无法获取 Pod 状态 | 节点网络问题、API Server 连接问题 |
2. 镜像相关问题
2.1 镜像拉取失败的常见原因
镜像相关问题是 Pod 启动失败最常见的原因之一。ImagePullBackOff和ErrImagePull是两个典型的镜像拉取失败状态。
# 查看 Pod 事件中的镜像相关错误 kubectl describe pod myapp-abc123 -n mynamespace | grep -A 5"ImagePull" # 示例输出: # Warning Failed 45s (x4 over 2m) kubelet Error: ImagePullBackOff # Warning Failed 45s kubelet Failed to pull image "myregistry.com/myapp:v1": # rpc error: code = Unknown desc = failed to pull and unpack image # 查看详细的拉取错误 kubectl describe pod myapp-abc123 -n mynamespace | grep -A 10"Warning"
镜像名称拼写错误:
# 错误示例:镜像名拼写错误 # kubectl run myapp --image=myap:v1 # 拼写错误,应该是 myapp # 正确做法:使用完整的镜像路径 kubectl run myapp --image=registry.example.com/myorg/myapp:v1.0.0
私有镜像认证问题:
# 创建 Secret 保存仓库认证信息
kubectl create secret docker-registry myregistry-secret
--docker-server=registry.example.com
--docker-username=admin
--docker-password=StrongPassword2026!
--docker-email=admin@example.com
-n mynamespace
# 在 Pod 中引用 Secret
kubectl get pod myapp-abc123 -o yaml | kubectl replace --force -f - <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: myapp-abc123
spec:
imagePullSecrets:
- name: myregistry-secret
containers:
- name: myapp
image: registry.example.com/myorg/myapp:v1.0.0
EOF
# 或在 ServiceAccount 中关联(影响该 SA 下所有 Pod)
kubectl patch serviceaccount default
-p '{"imagePullSecrets":[{"name":"myregistry-secret"}]}'
-n mynamespace
镜像 tag 指向错误:
# 使用 latest tag 的风险 # latest 指向的镜像可能随时变化,导致部署不确定性 # 正确做法:使用不可变的 tag(版本号、commit hash、时间戳) # good: myapp:v1.2.3 # good: myappabc123... # good: myapp:2026-04-10 # bad: myapp:latest
2.2 镜像预热与拉取策略
#!/bin/bash
# preload_images.sh
# 节点镜像预热脚本(减少 Pod 启动时间)
set-euo pipefail
IMAGES=(
"registry.example.com/myorg/base:v1.0"
"registry.example.com/myorg/app:v2.1"
"registry.example.com/myorg/nginx:alpine"
)
log() {
echo"[$(date '+%Y-%m-%d %H:%M:%S')]$1"
}
forimagein"${IMAGES[@]}";do
log"预热镜像:$image"
docker pull"$image"
done
log"镜像预热完成"
imagePullPolicy 配置:
# 镜像拉取策略 spec: containers: -name:myapp image:myapp:v1.0 imagePullPolicy:Always# Always | IfNotPresent | Never # 策略说明: # Always: 每次启动都拉取镜像(默认用于 :latest tag) # IfNotPresent: 本地存在则使用本地,不存在则拉取(默认用于指定 tag) # Never: 从不拉取,仅使用本地镜像
2.3 镜像健康检查脚本
#!/bin/bash
# check_images.sh
# 检查集群中所有节点使用的镜像
set-euo pipefail
NAMESPACE="${1:-}"
log() {
echo"[$(date '+%Y-%m-%d %H:%M:%S')]$1"
}
get_images_from_nodes() {
kubectl get nodes -o jsonpath='{.items[*].status.nodeInfo.containerRuntimeVersion}'
}
get_pod_images() {
if[ -n"$NAMESPACE"];then
kubectl get pods -n"$NAMESPACE"-o jsonpath='{range .items[*]}{.spec.containers[*].image}{"
"}{end}'| sort | uniq
else
kubectl get pods -A -o jsonpath='{range .items[*]}{.spec.containers[*].image}{"
"}{end}'| sort | uniq
fi
}
log"===== 所有 Pod 使用的镜像 ====="
get_pod_images
log"===== 节点信息 ====="
kubectl get nodes -o wide
log"===== 镜像 Pod 分布 ====="
forimagein$(get_pod_images);do
count=$(kubectl get pods -A -o jsonpath='{range .items[*]}{.spec.containers[*].image}{"
"}{end}'| grep -c"$image"||echo"0")
log"$image:$count个 Pod"
done
3. 资源不足与调度失败
3.1 调度失败的表现
Pod 处于Pending状态且PodScheduled=False,通常是调度失败或资源不足。
# 查看调度失败的原因 kubectl describe pod myapp-abc123 -n mynamespace | grep -A 20"Events:" # 典型输出: # Events: # Type Reason Age From Message # ---- ------ ---- ---- ------- # Warning FailedScheduling 32s default-scheduler 0/5 nodes are available: # 3 Insufficient memory, 2 node(s) had taints that the pod didn't tolerate. # 查看节点资源状态 kubectl describe nodes | grep -A 5"Allocated resources" # Allocated resources: # Resource Requests Limits # cpu 2500m (62%) 6 (150%) # memory 4Gi (80%) 8Gi (160%)
3.2 资源请求与限制
# 查看 Pod 的资源请求和限制
kubectl get pod myapp-abc123 -n mynamespace -o jsonpath='{.spec.containers[*].resources}'
# {"limits":{"cpu":"500m","memory":"256Mi"},"requests":{"cpu":"250m","memory":"128Mi"}}
资源请求(requests)vs 资源限制(limits):
requests:调度时使用的资源量,节点必须满足 requests 才能调度
limits:容器运行时的资源上限,超出 limits 会被限制(CPU)或 OOM Kill(内存)
# 典型的资源配置 apiVersion:v1 kind:Pod metadata: name:myapp spec: containers: -name:myapp image:myapp:v1 resources: requests: cpu:"250m" # 0.25 核 CPU memory:"128Mi" # 128 MB 内存 limits: cpu:"1000m" # 最多 1 核 CPU memory:"512Mi" # 最多 512 MB 内存
3.3 调度失败排查脚本
#!/bin/bash
# k8s_scheduler_diag.sh
# Kubernetes 调度失败诊断脚本
set-euo pipefail
NAMESPACE="${1:-default}"
log() {
echo"[$(date '+%Y-%m-%d %H:%M:%S')]$1"
}
echo"===== 调度失败的 Pod ====="
kubectl get pods -n"$NAMESPACE"--field-selector=status.phase=Pending -o wide
echo""
echo"===== 节点资源概览 ====="
kubectl top nodes 2>/dev/null ||echo"metrics-server 未安装或不可用"
echo""
echo"===== 各节点已分配资源 ====="
kubectl describe nodes | grep -A 10"Allocated resources"
echo""
echo"===== 存在资源不足的 Pod 事件 ====="
forpodin$(kubectl get pods -n"$NAMESPACE"--field-selector=status.phase=Pending -o name);do
echo"---$pod---"
kubectl describe"$pod"-n"$NAMESPACE"| grep -E"(Insufficient|FailedScheduling|tolerations)"| head -5
done
echo""
echo"===== 节点污点情况 ====="
kubectl get nodes -o custom-columns=NODE:.metadata.name,TAINTS:.spec.taints
echo""
echo"===== 未调度的 Pod 及原因 ====="
kubectl get pods -n"$NAMESPACE"--field-selector=status.phase=Pending -o jsonpath='{range .items[*]}{.metadata.name}{" "}{.status.conditions[?(@.type=="PodScheduled")].reason}{"
"}{end}'
3.4 资源不足的解决方案
# 方案1: 扩容节点
kubectl scale deployment myapp --replicas=3
# 方案2: 降低 Pod 资源请求
kubectl patch deployment myapp -p'{
"spec": {
"template": {
"spec": {
"containers":[{
"name": "myapp",
"resources": {
"requests": {
"cpu": "100m",
"memory": "64Mi"
}
}
}]
}
}
}
}'
# 方案3: 驱逐低优先级 Pod(为高优先级 Pod 腾出空间)
kubectl get pods --sort-by='.spec.priority'-n"$NAMESPACE"
# 方案4: 添加新节点(配合集群自动扩缩容)
kubectl apply -f - <<'EOF'
apiVersion: v1
kind: Node
metadata:
name: new-node
spec:
providerID: aws:///i-xxxxx
EOF
# 方案5: 调整 Pod 优先级
kubectl patch deployment myapp -p '{
"spec": {
"template": {
"spec": {
"priorityClassName": "high-priority"
}
}
}
}'
3.5 污点与容忍诊断
#!/bin/bash
# k8s_taint_diag.sh
# 污点与容忍诊断脚本
set-euo pipefail
log() {
echo"[$(date '+%Y-%m-%d %H:%M:%S')]$1"
}
log"===== 节点污点 ====="
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"
"}{range .spec.taints[*]} - {.key}={.effect} (Added by {.addedBy}){"
"}{end}{"
"}{end}'
echo""
log"===== Pod 容忍 ====="
kubectl get pods -A -o custom-columns=
NAMESPACE:.metadata.namespace,
NAME:.metadata.name,
TOLERATIONS:.spec.tolerations
echo""
log"===== 无法调度的 Pod(污点原因)====="
forpodin$(kubectl get pods -A --field-selector=status.phase=Pending -o name);do
reason=$(kubectl get"$pod"-o jsonpath='{.status.conditions[?(@.type=="PodScheduled")].reason}')
msg=$(kubectl get"$pod"-o jsonpath='{.status.conditions[?(@.type=="PodScheduled")].message}')
ifecho"$msg"| grep -qi"taint";then
echo"$pod:$reason-$msg"
fi
done
4. 存储挂载异常
4.1 存储相关问题
Pod 启动时需要挂载 PersistentVolume(PV)或配置映射(ConfigMap)、密钥(Secret)。存储问题会导致 Pod 停留在ContainerCreating状态。
# 查看存储挂载相关错误 kubectl describe pod myapp-abc123 -n mynamespace | grep -A 10"MountPropagation" kubectl describe pod myapp-abc123 -n mynamespace | grep -A 5"VolumeMount" kubectl describe pod myapp-abc123 -n mynamespace | grep -A 10"Volumes:" # 常见错误: # "MountVolume.SetUp failed" - 卷挂载失败 # "Unable to attach or mount volumes" - 无法挂载卷 # "multi-attach error" - 卷被多个 Pod 同时挂载
4.2 PVC 状态诊断
#!/bin/bash
# k8s_pvc_diag.sh
# PVC 状态诊断脚本
set-euo pipefail
NAMESPACE="${1:-default}"
log() {
echo"[$(date '+%Y-%m-%d %H:%M:%S')]$1"
}
log"===== PVC 状态 ====="
kubectl get pvc -n"$NAMESPACE"
echo""
log"===== PVC 详细信息 ====="
kubectl describe pvc -n"$NAMESPACE"
echo""
log"===== PVC 绑定状态为 Pending 的 Pod ====="
kubectl get pods -n"$NAMESPACE"-o jsonpath='{range .items[*]}
Pod: {.metadata.name}
Status: {.status.phase}
Conditions: {.status.conditions[?(@.type=="PodScheduled")].reason}
Volumes: {.spec.volumes[*].name}
{"
"}{end}'| grep -A 3"Status: Pending"
echo""
log"===== StorageClass 信息 ====="
kubectl get storageclass
kubectl describe storageclass
echo""
log"===== 检查 PV 状态 ====="
kubectl get pv
kubectl describe pv
4.3 ConfigMap 和 Secret 问题
# 查看 ConfigMap 相关错误
kubectl describe pod myapp-abc123 | grep -A 5"ConfigMap"
# 查看 Secret 相关错误
kubectl describe pod myapp-abc123 | grep -A 5"Secret"
# 检查 ConfigMap 是否存在
kubectl get configmap myconfig -n mynamespace
# 检查 Secret 是否存在
kubectl get secret mysecret -n mynamespace
# 检查引用的 ConfigMap/Secret 版本
kubectl get pod myapp-abc123 -o jsonpath='{.spec.volumes[*].configMap.name}'
kubectl get pod myapp-abc123 -o jsonpath='{.spec.volumes[*].secret.secretName}'
# ConfigMap 更新后强制 Pod 重新加载(通常需要重启 Pod)
kubectl rollout restart deployment myapp -n mynamespace
# 或手动删除 Pod 触发重建
kubectl delete pod myapp-abc123 -n mynamespace
4.4 HostPath 问题
# HostPath 卷问题排查
kubectl describe pod myapp-abc123 | grep -A 10"HostPath"
# 检查宿主机路径是否存在
kubectl get pod myapp-abc123 -o jsonpath='{.spec.volumes[*].hostPath.path}'
# 例如:/data/logs
# 在节点上检查
# kubectl exec -it myapp-abc123 -n mynamespace -- sh
# 在节点上检查:
# ls -la /data/logs
# 常见 HostPath 问题:
# 1. 路径不存在
# 2. 路径存在但权限不足
# 3. 路径是文件而非目录
5. 网络配置问题
5.1 网络相关问题表现
Pod 处于ContainerCreating状态但不是网络插件( CNI)问题,就是 Service/NetworkPolicy 配置问题。
# 查看 CNI 相关错误
kubectl describe pod myapp-abc123 -n mynamespace | grep -A 5"NetworkPlugin"
kubectl describe pod myapp-abc123 -n mynamespace | grep -i"cni|network"
# 查看 Pod IP 分配情况
kubectl get pod myapp-abc123 -n mynamespace -o jsonpath='{.status.podIP}'
kubectl get pod myapp-abc123 -n mynamespace -o jsonpath='{.status.podIPs}'
5.2 DNS 问题排查
DNS 是 Kubernetes 网络中最容易出问题的环节之一。
#!/bin/bash
# k8s_dns_diag.sh
# DNS 问题诊断脚本
set-euo pipefail
POD_NAME="${1:-}"
NAMESPACE="${2:-default}"
if[ -z"$POD_NAME"];then
echo"用法:$0 [命名空间]"
exit1
fi
log() {
echo"[$(date '+%Y-%m-%d %H:%M:%S')]$1"
}
log"===== 检查 Pod DNS 配置 ====="
kubectlexec-it"$POD_NAME"-n"$NAMESPACE"-- cat /etc/resolv.conf
echo""
log"===== 测试 DNS 解析 ====="
kubectlexec-it"$POD_NAME"-n"$NAMESPACE"-- nslookup kubernetes.default 2>&1 | head -5
kubectlexec-it"$POD_NAME"-n"$NAMESPACE"-- nslookup google.com 2>&1 | head -5
echo""
log"===== 测试网络连通性 ====="
kubectlexec-it"$POD_NAME"-n"$NAMESPACE"-- ping -c 3 8.8.8.8
echo""
log"===== 查看 CoreDNS Pod 状态 ====="
kubectl get pods -n kube-system -l k8s-app=kube-dns -o wide
kubectl logs -n kube-system -l k8s-app=kube-dns --tail=20
echo""
log"===== CoreDNS 配置 ====="
kubectl get configmap coredns -n kube-system -o yaml
5.3 Service 和 Endpoint 问题
# 查看 Service 关联的 Endpoints kubectl get endpoints myapp-service -n mynamespace # 如果 Endpoints 为空,说明没有 Pod 匹配 Service 的 selector kubectl describe service myapp-service -n mynamespace | grep -A 5"Selector" # 检查 Pod 是否匹配 Service Selector kubectl get pods -n mynamespace -l app=myapp --show-labels # 端到端连通性测试 kubectlexec-ittest-pod -n mynamespace -- wget -qO- http://myapp-service.mynamespace.svc.cluster.local:8080/health
5.4 网络策略问题
# 查看 Pod 的网络策略 kubectl get networkpolicy -A # 检查特定 Pod 是否被 NetworkPolicy 限制 kubectl describe pod myapp-abc123 -n mynamespace | grep -i"policy" # 测试 Pod 间网络(从测试 Pod 访问目标 Pod) kubectl runtest-pod --image=busybox:1.36 -n mynamespace --restart=Never --rm -it -- wget -qO- http://myapp-service.mynamespace.svc.cluster.local:8080/
6. 深度排障工具
6.1 kubectl debug 高级用法
Kubernetes 1.20+ 提供了kubectl debug命令,可以在不修改 Pod 的情况下进行调试。
# 在 Pod 所在节点上启动调试容器 kubectl debug myapp-abc123 -n mynamespace -it --image=busybox:1.36 --share-processes --copy-to=myapp-debug # 查看调试容器的 Shell kubectlexec-it myapp-debug -n mynamespace -- sh # 复制 Pod 的网络命名空间进行调试 kubectl debug myapp-abc123 -n mynamespace --image=busybox:1.36 -it --container=myapp --copy-to=myapp-netdebug # 检查节点级别问题(节点调试) kubectl debug node/my-node -it --image=busybox:1.36 # 在节点 shell 中执行: # ls /var/log/pods/ # crictl ps # crictl logs
6.2 crictl 工具
crictl 是 container runtime interface(CRI)的 CLI 工具,用于直接与 containerd 或 CRI-O 交互。当 kubectl 无法访问时(如节点网络故障),crictl 是最后一道排障手段。
# 查看容器列表 crictl ps -a # 查看镜像列表 crictl images # 查看容器日志 crictl logs# 查看容器详细信息 crictl inspect # 进入容器(如果支持 exec) crictlexec-it sh # 查看容器挂载 crictl inspect | grep -A 20"mounts" # 重启容器(相当于 kubelet 重建) crictl stop crictl rm # 然后删除 Pod,kubelet 会重新创建 # 查看沙箱/pause 容器 crictl pods # 资源统计 crictl stats
6.3 kubelet 日志分析
# 查看 kubelet 日志(systemd 环境) journalctl -u kubelet -n 100 --no-pager # 查看特定 Pod 的 kubelet 日志(按 pod UID 过滤) journalctl --no-pager | grep -E"podUID|myapp-abc123" # kubelet 日志中的常见信息 # "Container runtime network not ready" - CNI 未就绪 # "Image garbage collection failed" - 镜像垃圾回收失败 # "Failed to start container" - 容器启动失败 # "Failed to kill pod" - 删除 Pod 失败 # 检查 kubelet 配置 kubectl get cm kubelet-config -n kube-system -o yaml # 查看 kubelet 服务状态 systemctl status kubelet systemctl restart kubelet
6.4 完整排障脚本
#!/bin/bash
# k8s_deep_diag.sh
# Kubernetes Pod 深度排障脚本
set-euo pipefail
POD_NAME="${1:-}"
NAMESPACE="${2:-default}"
if[ -z"$POD_NAME"];then
echo"用法:$0 [命名空间]"
exit1
fi
RED='�33[0;31m'
GREEN='�33[0;32m'
YELLOW='�33[1;33m'
NC='�33[0m'
log_ok() {echo-e"${GREEN}[OK]${NC}$1"; }
log_warn() {echo-e"${YELLOW}[WARN]${NC}$1"; }
log_error() {echo-e"${RED}[ERROR]${NC}$1"; }
echo"========================================"
echo"Kubernetes Pod 深度排障"
echo"Pod:$POD_NAME"
echo"命名空间:$NAMESPACE"
echo"========================================"
# 1. 基本状态
echo""
echo"【1. Pod 基本状态】"
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o wide
STATUS=$(kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.status.phase}')
log_ok"Pod Phase:$STATUS"
# 2. 事件分析
echo""
echo"【2. Pod 事件】"
EVENTS=$(kubectl get events -n"$NAMESPACE"
--field-selector involvedObject.name="$POD_NAME"
--sort-by='.lastTimestamp'| tail -10)
ifecho"$EVENTS"| grep -qi"error|fail|backoff";then
log_error"发现错误/失败事件"
fi
echo"$EVENTS"
# 3. 容器状态
echo""
echo"【3. 容器状态】"
CONTAINERS=$(kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{range .status.containerStatuses[*]}
名称: {.name}
状态: {.state}
重启: {.restartCount}
{"
"}{end}')
echo"$CONTAINERS"
# 4. 镜像检查
echo""
echo"【4. 镜像状态】"
IMAGES=$(kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{range .spec.containers[*]}Container: {.name}, Image: {.image}{"
"}{end}')
echo"$IMAGES"
# 5. 资源配置
echo""
echo"【5. 资源请求与限制】"
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.spec.containers[*].resources}'| python3 -m json.tool
# 6. 节点状态
echo""
echo"【6. 调度的节点】"
NODE=$(kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.spec.nodeName}')
if[ -n"$NODE"];then
log_ok"节点:$NODE"
kubectl describe node"$NODE"| grep -A 5"Allocated resources"
kubectl top node"$NODE"2>/dev/null || log_warn"metrics-server 不可用"
else
log_error"Pod 未调度到任何节点"
fi
# 7. PVC 挂载
echo""
echo"【7. PVC 挂载】"
PVS=$(kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{range .spec.volumes[*]}{if .persistentVolumeClaim}PVC: {.persistentVolumeClaim.claimName}{"
"}{end}{end}')
if[ -n"$PVS"];then
echo"$PVS"
forpvcin$(echo"$PVS"| grep PVC | awk'{print $2}');do
kubectl get pvc"$pvc"-n"$NAMESPACE"
done
else
log_ok"无 PVC 挂载"
fi
# 8. ConfigMap/Secret
echo""
echo"【8. ConfigMap/Secret】"
CM_COUNT=$(kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{len .spec.volumes}'2>/dev/null ||echo"0")
if["$CM_COUNT"-gt 0 ];then
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{range .spec.volumes[*]}{.name}: {.configMap.name}{.secret.secretName}{"
"}{end}'
fi
# 9. 网络状态
echo""
echo"【9. 网络状态】"
POD_IP=$(kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.status.podIP}')
log_ok"Pod IP:$POD_IP"
# 10. 存活探针
echo""
echo"【10. 探针配置】"
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.spec.containers[*].livenessProbe}'| python3 -m json.tool 2>/dev/null ||
kubectl get pod"$POD_NAME"-n"$NAMESPACE"-o jsonpath='{.spec.containers[*].readinessProbe}'| python3 -m json.tool
echo""
echo"========================================"
echo"排障完成"
echo"========================================"
7. 常见故障场景与处理
7.1 CrashLoopBackOff
CrashLoopBackOff 表示容器启动后立即崩溃,kubelet 反复尝试重启。
# 查看容器退出原因
kubectl logs myapp-abc123 -n mynamespace --previous
# 查看容器退出码
kubectl get pod myapp-abc123 -n mynamespace -o jsonpath='{.status.containerStatuses[*].lastState.terminated.exitCode}'
# 常见退出码:
# 0: 正常退出(可能是 main 进程提前退出)
# 1: 一般错误(应用崩溃)
# 137: 被 SIGKILL(内存不足或 OOM)
# 139: 段错误(SIGSEGV)
# 143: 优雅退出(SIGTERM)
# 典型原因分析
# 1. 应用启动失败(配置错误、依赖不可用)
# 2. 内存不足被 OOM Kill
# 3. 健康检查失败
# 4. 权限问题
OOM Kill 处理:
# 检查节点是否存在 OOM
dmesg | grep -i"oom"| tail -20
# 检查 Pod 的内存限制
kubectl get pod myapp-abc123 -o jsonpath='{.spec.containers[*].resources.limits.memory}'
# 增加内存限制
kubectl patch deployment myapp -n mynamespace -p'{
"spec": {
"template": {
"spec": {
"containers":[{
"name": "myapp",
"resources": {
"limits": {"memory": "1Gi"}
}
}]
}
}
}
}'
7.2 Init 容器失败
# Init 容器失败会导致主容器永远无法启动
kubectl get pod myapp-abc123 -o jsonpath='{.status.initContainerStatuses}'
# 查看 Init 容器日志
kubectl logs myapp-abc123 -n mynamespace -c my-init-container --previous
# 常见 Init 容器问题:
# 1. Init 容器镜像拉取失败
# 2. Init 容器执行失败(exit code != 0)
# 3. Init 容器超时
# 解决方案
# 1. 检查 Init 容器配置
kubectl get pod myapp-abc123 -o yaml | grep -A 10"initContainers"
# 2. 延长 Init 容器超时时间
kubectl patch deployment myapp -n mynamespace -p'{
"spec": {
"template": {
"spec": {
"initContainers":[{
"name": "my-init",
"resources": {},
"imagePullPolicy": "IfNotPresent"
}]
}
}
}
}'
7.3 存活探针失败
# 存活探针失败会导致 Pod 被重启 kubectl describe pod myapp-abc123 | grep -A 5"Liveness" # 临时禁用探针进行测试 kubectl run myapp-test --image=myapp:v1 --restart=Never -- /bin/sh -c"sleep 3600" # 常见探针问题: # 1. 探针路径错误(应用未提供 /health 端点) # 2. 探针端口错误 # 3. 应用启动过慢(需要 initialDelaySeconds) # 4. 探针超时时间过短 # 调整探针配置 kubectl patch deployment myapp -n mynamespace -p'{ "spec": { "template": { "spec": { "containers":[{ "name": "myapp", "livenessProbe": { "httpGet": {"path": "/health", "port": 8080}, "initialDelaySeconds": 30, "periodSeconds": 10, "failureThreshold": 3 } }] } } } }'
7.4 Evicted(被驱逐)
Pod 被驱逐通常是因为节点资源压力或运维操作。
# 查看被驱逐的 Pod kubectl get pods -n mynamespace --field-selector=status.phase=Failed | grep Evicted # 驱逐原因 kubectl describe pod myapp-abc123 | grep -A 3"Reason: Evicted" # 常见驱逐原因: # 1. 节点内存压力 (MemoryPressure) # 2. 节点磁盘压力 (DiskPressure) # 3. 节点 PID 压力 (PIDPressure) # 4. 运维主动驱逐 (kubectl drain) # 处理:删除被驱逐的 Pod,Deployment 会创建新的 kubectl delete pod myapp-abc123 -n mynamespace --grace-period=0 --force # 检查节点资源状态 kubectl describe node | grep -E"MemoryPressure|DiskPressure|PIDPressure|Conditions"
7.5 Terminating 状态卡住
Pod 删除后一直处于Terminating状态。
# 查看 Terminating 原因
kubectl describe pod myapp-abc123 | grep -A 10"Conditions"
# 常见原因:
# 1. Finalizers 未完成
# 2. 存储卷未卸载
# 3. 网络插件问题
# 4. 容器未响应 SIGTERM
# 强制删除(谨慎使用)
kubectl delete pod myapp-abc123 -n mynamespace --grace-period=0 --force
# 检查 finalizers
kubectl get pod myapp-abc123 -o jsonpath='{.spec.finalizers}'
# 如果是 finalizers 问题,移除 finalizers
kubectl patch pod myapp-abc123 -n mynamespace -p'{"metadata":{"finalizers":[]}}'--type=merge
# 检查 NFS 等存储挂载是否卡住
mount | grep nfs
8. 排障流程图与总结
8.1 Pod 排障决策树
Pod 状态不是 Running? │ ├── Pending │ ├── 检查 kubectl describe pod Events │ │ ├──"FailedScheduling"→ 资源不足/调度失败 → 参见调度诊断 │ │ ├──"Unschedulable"→ 资源不足 → 增加节点或减少请求 │ │ └──"didn't have free ports"→ 端口冲突 │ └── kubectl get events --field-selector involvedObject.name=│ ├── ContainerCreating │ ├── 检查 kubectl describe pod │ │ ├──"ImagePullBackOff"→ 镜像拉取失败 → 检查镜像地址/认证 │ │ ├──"ErrImagePull"→ 同上,早期阶段 │ │ ├──"MountVolume.SetUp failed"→ 存储问题 → 检查 PVC/PV │ │ └──"NetworkPlugin"→ CNI 问题 → 检查网络插件 │ └── crictl ps -a 查看容器状态 │ ├── CrashLoopBackOff │ ├── kubectl logs --previous 查看崩溃日志 │ ├── 检查退出码 │ │ ├── 137 → 内存不足 OOM │ │ ├── 1 → 应用错误 │ │ └── 0 → 进程正常退出但不应该退出 │ └── 检查资源限制和实际使用 │ ├── ImagePullBackOff │ ├── 检查镜像名称是否正确 │ ├── 检查 imagePullSecrets 是否配置 │ ├── 手动测试 docker pull 镜像 │ └── 检查私有仓库认证 │ ├── Running 但 Ready=False │ ├── 检查存活探针和就绪探针 │ ├── kubectl logs 查看探针路径 │ └── 检查应用 /health 端点 │ ├── Evicted │ ├── 检查节点资源状态 │ └── 重新调度 Pod │ └── Terminating 卡住 ├── 检查 finalizers ├── 检查存储挂载 └── 强制删除
8.2 核心排障命令速查
# Pod 基本信息 kubectl get pod-o wide kubectl describe pod kubectl get pod -o yaml # 日志 kubectl logs --tail=100 kubectl logs --previous # 上一次运行的日志 # 事件 kubectl get events -n --field-selector involvedObject.name= --sort-by='.lastTimestamp' # 资源使用 kubectl top pod kubectl top node # 调度 kubectl get pods -n --field-selector=status.phase=Pending # 存储 kubectl get pvc -n kubectl describe pvc # 网络 kubectl get svc -n kubectl get endpoints -n # 节点级调试 kubectl debug -it --image=busybox -- sh crictl ps -a crictl logs journalctl -u kubelet -n 50 --no-pager
8.3 预防措施
资源配置合理:requests 和 limits 根据实际负载设置,避免资源耗尽和 OOM
镜像预热:在 Pod 调度前预先拉取镜像,减少启动时间
健康检查合理:探针路径、端口、超时时间需与应用实际情况匹配
监控告警:对 Pod 非 Running 状态设置告警,及时发现问题
定期演练:模拟各类故障,验证排障流程的有效性
9. 总结
Pod 启动失败是 Kubernetes 运维中最常见的故障形态,但并非所有非 Running 状态都需要紧急处理。运维工程师需要建立系统的排障思路:
首先确认状态:通过kubectl get pod确认 Pod 的实际状态和所属阶段
其次查看事件:通过kubectl describe pod的 Events 部分获取第一手错误信息
然后定位根因:根据事件中的 Reason 和 Message 判断问题类别(镜像、资源、存储、网络、探针)
最后实施修复:根据根因选择对应的修复方案,并验证结果
本文覆盖了从基础状态诊断到深度节点级排障的完整工具链。在实际工作中,建议运维团队将这些脚本整理成工具库,配合监控告警形成完整的故障响应体系。
本文基于 Kubernetes 1.32、containerd 2.0、crictl 1.32 环境编写,测试于 Ubuntu 24.04 LTS 和 CentOS Stream 9。
-
容器
+关注
关注
0文章
546浏览量
23082 -
Docker
+关注
关注
0文章
542浏览量
14541 -
kubernetes
+关注
关注
0文章
282浏览量
9569
原文标题:Pod 一直起不来,运维排障别只会盯着 Running
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Kubernetes的Device Plugin设计解读
阿里云容器Kubernetes监控(二) - 使用Grafana展现Pod监控数据
从零开始入门 K8s| 详解 Pod 及容器设计模式
iPod排障秘技!
Kubernetes组件pod核心原理
Kubernetes中的Pod简易理解
Kubernetes Pod如何独立工作
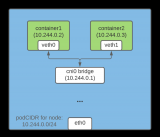
Kubernetes Pod如何获取IP地址呢?




评论