 各种知识图谱精化方法,为国内同行介绍本领域的最新研究成果
各种知识图谱精化方法,为国内同行介绍本领域的最新研究成果

摘要:
知识图谱是一种在移动互联网大时代下产生的新型知识表示方法,而精化是知识图谱应用研究的主要内容之一,其主要任务是知识图谱补全和错误检测等,在信息检索、机器人、智能问答等领域有着重要的应用前景。因此,对知识图谱精化进行研究具有十分重要的意义。对当前知识图谱精化方法进行了较为全面、深入的总结,并对知识图谱未来的主要研究方向进行了展望。
❖
0 引言
随着链接开放数据源(如DBpedia)的出现以及谷歌在2012年提出知识图谱的概念,全球掀起了研究知识图谱的热潮,涌现出了大量的知识图谱构建技术[1-5],并构建了各种知识图谱,这些知识图谱要么是开放的,要么是公司私有的,如Freebase[2]、维基数据(Wikidata)[3]、DBpedia[4]、YAGO[5]等,但无论采用哪种技术,构造出来的知识图谱都不完美[6]。随着研究的深入,越来越多的研究者开始关注知识图谱的覆盖率和正确率。而提高知识图谱的覆盖率和正确率是知识图谱精化的主要目的,对知识图谱进行精化具有十分重要的意义。
近年来,该领域的研究进展非常迅速,涌现出了一大批研究成果,已经研发出了多种知识图谱精化方法,这些方法主要集中在讨论知识图谱补全[7-28]和知识图谱错误探测[29-34]两个方面,这也是本文从这两个方面进行综述的原因。
本文的贡献是:(1)讨论各种知识图谱精化方法;(2)为国内同行介绍本领域的最新研究成果,了解该领域的研究进展,从而推动我国在该领域的发展。
1 知识图谱精化相关概念
1.1 知识图谱的概念
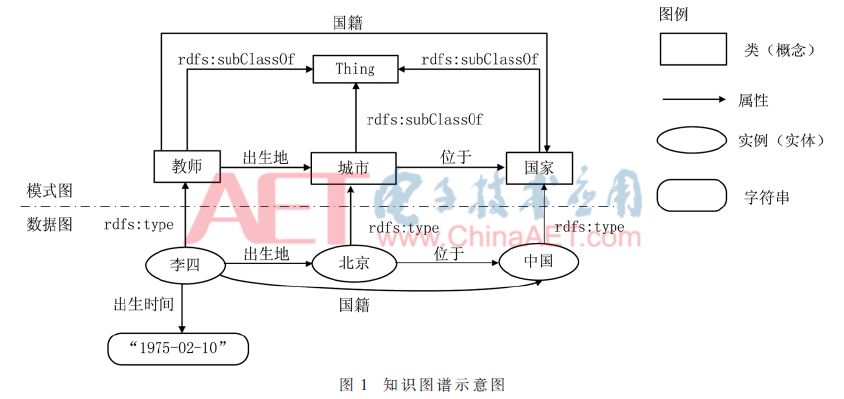
“知识图谱”是一种描述真实世界客观存在的实体、概念及它们之间关联关系的语义网络。可以利用知识图谱开发语义检索和自动问答等应用[1]。知识图谱的结构如图1所示。可见,知识图谱是一个有向图,由模式(schema)图和数据图构成。其中,模式图描述类之间的关系;数据图描述实体之间的关系。图1描述的知识(事实)如下:
(1)李四是一个教师
(2)北京是一个城市
(3)中国是一个国家
(4)李四的出生地为北京
(5)北京位于中国
(6)李四的国籍是中国
1.2 知识图谱构建与知识图谱精化
知识图谱构建是使用各种技术从无到有构造知识图谱,而知识图谱精化是使用各种技术对知识图谱进行完善。可见,要构建一个完美的知识图谱,需要经过多个精化步骤。因此,知识图谱构建和知识图谱精化是相辅相成、不可分割的。另外,本文将关系、文字和类型称为精化目标。
2 常用的知识图谱补全方法
知识图谱补全的目的是利用已有信息,预测丢失的实体、类型和实体间的关系,从而提高知识图谱的覆盖率。它是知识图谱精化的主要任务之一,其对应的精化目标包括实体、类型和实体间的关系。但根据已有文献,发现目前该方面的研究主要集中在对类型和实体间的关系进行精化。
本节根据知识图谱补全使用的数据源,将知识图谱补全方法分为知识图谱内部补全和知识图谱外部补全两大类。其中,知识图谱内部补全方法是指仅使用知识图谱本身预测丢失信息的方法总称,知识图谱外部补全方法是指除使用知识图谱本身以外,还使用其他数据源(如文本语料)来预测丢失信息的方法总称。下面将从这两个方面对知识图谱错误探测进行综述。
2.1 知识图谱内部补全方法
为了揭示内部补全方法因精化目标的不同而不同,本小节将根据精化目标的不同,把内部补全方法分成实体类型内部补全和关系内部预测两类进行综述。
2.1.1 实体类型内部补全
实体类型内部补全就是利用知识图谱本身已有的实体、实体类型和实体关系预测丢失的实体类型。
在机器学习领域,常用多分类方法对实体类型进行补全。其中,PAULHEIM H等人[7-8]提出了一种基于条件概率的补全算法SDType,这种算法的思想是通过实体所具有的关系预测实体类型。SDType算法的评价矩阵是正确率(precision)、召回率和新增类型数目。但这种算法的缺点是假设关系之间是相互独立的,而现实世界中这种假设在很多情况下是不成立的,并且该算法没有用类型的层次结构。利用SDType算法,已经为知识图谱DBpedia新增了3.4亿条类型语句。KROMPA?覻 D等人[9]利用张量分解预测实体类型,这种方法的思想是把知识图谱表示成一个实体-实体-关系的三维张量,然后通过张量分解的方法实现类型补全。该方法的评价矩阵是正确率、召回率和正确率-召回率曲线。张香玲等人[10]提出了一种由谓词和谓词及谓词和类型的相互作用补全实体类型的模型,在该模型中,为了解决类型语义漂移,使用PMI技术设计一个有效的谓词-类型推理图及基于图上的随机游走算法。该模型的评价矩阵是正确率和召回率。SLEEMAN J等人[11]将主题模型用在关系预测中,这种方法的思想是首先将实体表示成文档,应用LDA抽取文档的主题,然后通过分析主题和实体类型的共现关系,根据分析结果,将实体类型指派给主题对应的实体。该方法的评价矩阵是正确率和召回率。
在数据挖掘领域,利用关联规则预测知识图谱丢失的信息。PAULHEIM H等人[12]基于数据冗余信息使用关联规则来预测DBpedia中丢失的类型。这种方法的评价矩阵为正确率和增加的类型数。
2.1.2 关系内部预测
按照相同的思路,在机器学习领域,也把预测关系的存在与否看成是一个二分类问题。其中,SOCHER R等人[13]提出一种通过训练张量神经网络预测新关系的方法。例如:如果一个人出生在德国,那么该方法就能根据这个关系预测他的国籍是德国。这种方法的评价矩阵是精确率(accuracy),已被用于Freebase和WordNet中。BAIER S等人[14]也提出了类似的方法,但他们在预测过程增加了模式知识,以提高关系预测的性能。不同的是该方法的评价矩阵是正确率-召回率曲线面积和ROC曲线面积。类似地,ZHAO Y等人[15]通过将关系嵌入到一个低维空间中来预测Freebase中关系的存在,这种方法的评价矩阵是正确率。
同样地,在数据挖掘领域,将关联规则挖掘也用于预测关系。其中,KIM J等人[16]提出了一种利用关联规则预测DBpdia中实体关系的方法。这种方法只能预测来自于维基百科分类中的实体关系,其评价矩阵是正确率和增加的关系数目。KOLTHOFF C等人[17]利用关联规则挖掘思想查找意义丰富的关系链来预测关系,该方法的评价矩阵是正确率和召回率。
2.2 知识图谱外部补全方法
与知识图谱外部补全方法类似,为了揭示外部补全方法因精化目标的不同而不同,本小节将根据精化目标的不同,把外部补全方法分成实体类型外部补全和关系外部预测两类进行综述。
2.2.1 实体类型外部补全
实体类型外部补全就是利用知识图谱本身和外部数据来预测丢失的实体类型。根据已有文献分析,实体类型外部补全方法的研究主要集中在机器学习和自然语言处理领域。
在机器学习领域,主要将外部数据表示成实体特征进行分类。因为维基百科页之间的链接没有约束,所以维基百科网页之间的链接比知识图谱中相应实体的链接要多。因此,NUZZOLESE A G等人[18]利用维基百科链接图和KNN分类算法来预测知识图谱中的实体类型。如果一个知识图谱包含到维基百科的链接,那么就以相关页的分类为基础,将维基百科网页之间的链接表示成特征向量,这种方法的评价矩阵是正确率和召回率。APRIOSIO A P等人[19]将DBpedia各种语言版本中的实体类型作为特征来预测丢失的类型,该方法使用不同距离公式的K-NN分类器,综合应用这些不同的距离公式,得到了最好的结果。这种方法的评价矩阵是正确率和召回率。SLEEMAN J等人[20]将支持向量机用于DBpedia和Freebase中的实体类型预测。为了提高覆盖率和正确率,作者利用知识图谱间的内部链接和其他知识图谱的属性对知识图谱实例进行分类,这种方法的评价矩阵为正确率和召回率。
在自然语言处理领域,KLIEGR T[21]等人使用了不同语言的摘要来进行实体类型预测,从而大大提高知识图谱的覆盖率和正确率,这种方法的评价矩阵是正确率和召回率。
2.2.2 关系外部预测
关系外部预测就是利用知识图谱本身和外部数据来预测丢失的实体关系。
一部分研究者利用远程监督法和自然语言处理方法对大规模文本语料库进行处理以预测实体关系,其思路为:首先,通过命名实体识别将知识图谱中的实体链接到语料库(如维基百科)中;然后,以知识图谱已有的关系为基础,找到与关系对应的文本模式,例如,“author”关系对应的文本模式为“Y’s book X”;最后,利用已找到的文本模式去发现语料库中的新关系。其中,APROSIO A P等人[22]将远程监督法用于预测DBpedia中的关系,该方法将维基百科作为语料库,并且将正确率和召回率作为评价矩阵。GERBER D等人[23]也提出了类似的方法,并开发了一个RdfLiveNews原型。在该原型中,利用新闻的RSS来解决DBpedia的时效性,即判断预测到的新关系在DBpedia中属于过时的关系还是丢失的关系。这种方法使用的评价矩阵是正确率、召回率和精确率。
一部分研究者利用Web搜索引擎填充知识图谱[24]。和上述研究类似,这种方法首先找到关系对应的词汇,然后使用这些词汇形成搜索语句以填充丢失的关系值。显然,该方法使用整个网络作为语料库,并使用信息提取和抽取技术进行知识图谱的补全。这种方法使用的评价矩阵是正确率、召回率和排名。
一部分研究者直接从网站的表格中抽取关系[25-26]。其中,HOGAN A等人[25]提出一种从维基百科表格中抽取关系的方法。他们认为维基百科表格中共存的两个实体共享知识图谱中的一条边,为了补全这些边,首先使用已有关系从表格中抽取出候选实体集,然后对候选实体子集进行标注,最后基于已标注的候选实体子集,使用分类算法来识别知识图谱中真正成立的关系,这种方法使用的评价矩阵是正确率和召回率。RITZE D等人[26]将上述方法扩展到任意的HTML表格中,该方法的不足是不仅要求表的列必须与DBpdedia本体中的属性匹配,而且要求行也要与DBpdedia中的实体匹配。这种方法使用的评价矩阵是正确率和召回率。
一些研究者认为许多自动构建的知识图谱包含很多到其他知识图谱的链接,可以利用这些链接对知识图谱进行融合。其中, DUTTA A等人[27]提出一种在知识图谱之间建立概率映射的方法。这种方法首先以类型和属性的分布概率为基础,创建知识图谱之间的映射,然后利用该映射得到知识图谱中丢失的事实,最后,在两个知识图谱使用的类型系统之间建立映射。这样就可以用一个知识图谱的类型去预测另一个知识图谱的类型。该方法利用黄金标准进行评估,其评价矩阵是正确率和召回率。
另外,WANG Q等人[28]利用耦合的路径排序算法补全知识图谱。这种方法首先设计了一个聚类算法自动发现彼此高度相关的关系,然后采用多任务学习策略对这些关系的预测进行耦合,这样是为了能够利用关系之间的联系和共享隐式数据。该方法使用的评价矩阵是平均正确率和平均倒数排名(Mean Reciprocal Rank)。
3 常用的知识图谱错误探测方法
与知识图谱补全方法不同,知识图谱错误探测的目的是利用已有信息,识别图中的错误信息, 同样,本节也将错误探测分成内部和外部两类。
3.1 知识图谱错误内部探测方法
目前错误内部探测方法主要集中在文字值错误和链接错误上,因此本部分只对这两类方法进行综述。
3.1.1 文字值错误内部检测
异常检测(Outlier detection)的目的是识别一个数据集中与大多数数据偏离的实例,即特征显著的数据。由于异常检测在许多情况下仅处理数值型数据,因此数值型文字自然成为这些方法处理的对象。其中,WIENAND D等人[29]将不同的单变量异常值检测方法(如四分位范围或核密度估计)用于DBpedia中,该方法使用正确率和新增文字数作为评价矩阵。
为了降低自然异常的影响,FLEISCHHACKER D等人[30]对文献[29]的方法进行了扩展,将实例集分成更小的子集,从而提高识别的正确率。这种方法还能使用其他知识图谱预测交叉检测异常,是内部检测和外部检测方法的混合。
3.1.2 知识图谱链接错误内部检测
PAULHEIM H[31]指出异常检测不仅可用于数值型数据,还可用于知识图谱的内部链接。他首先将链接表示成多维特征向量,然后利用标准的异常检测技术(如局部异常因素检测、基于簇的异常检测)指派异常分数,基于这些异常分数和所有链接的整体分布情况,能够识别出不合理的链接。LI H等人[32]使用概率模型学习属性之间的数学关系(如小于、大于),例如,一个人的出生日期必须在死亡日期之前。如果知识图谱中有关系与这些关系不符,那么就说明该关系是错误的。
3.2 知识图谱错误外部探测
知识图谱错误外部探测就是除了利用知识图谱本身外,还利用外部的资源来检测错误。外部探测方法主要集中在错误关系探测和错误文字值探测两方面。所以,本小节将从这两个方面进行综述。
3.2.1 错误关系外部检测
错误关系外部检测就是除了利用知识图谱本身外,还利用外部的资源来检测错误的实体间关系。其中, PAULHEIM H等人认为在知识图谱构造过程中大量的错误都是由一个共同的原因(如错误的映射或程序错误)造成的,因此,只需检测少量的样本,就会发现大量错误的语句。于是他们提出了一种识别不一致性的自动化聚类方法[33],该方法只需要给人提供代表性的样本即可,从而解决了上述的规模问题。
3.2.2 错误文字值外部检测
文献[34]提出了一种使用知识图谱链接探测错误数字值的自动方法,作者利用相同资源的链接和单个资源中属性之间的不同匹配函数来识别错误。他们认为如果多个外部资源与知识图谱中的一个事实发生冲突,那么就认为该事实是错的。
4 讨论
通过文献发现,将知识图谱精化方法分成知识图谱补全和知识图谱错误探测两大类是严谨的。因为目前基本不存在一个方法同时解决知识图谱补全和知识图谱错误探测。唯一的例外是文献[8],该文献既能进行知识图谱补全又能进行知识图谱错误探测。但它实际上是两个方法,分别是SDType和SDValidate,因为这两个方法不是一个整体,而是独立存在的。其中SDType负责进行补全,SDValidate负责进行错误探测。在知识图谱精化方面,为什么大量的研究成果都只用在一个方面,这个原因还不太明确。但在客观世界中,知识图谱补全和知识图谱错误探测这两个过程是相辅相成的。除了将补全和错误检测严格区别以外,还发现多数方法只能处理一种精化目标,同时处理多种精化目标的方法相当少。因此,将每类精化任务按照精化目标进行分类这也是严谨的。
在知识图谱补全方面,本文所介绍的方法都是对已有实体的类型或关系进行补全。经文献分析,目前没有方法能够增加新的实体,这种实体集扩展方法属于NLP领域,但这种方法对于进一步提高知识图谱覆盖率非常有用,尤其可以减少长尾实体。可见,研究增加新实体的方法也将是知识图谱精化的一个新方向。
在知识图谱错误探测方面,所有方法都输出一个潜在错误的语句列表。但据笔者所知,只有文献[33]能从错误列表中发现知识图谱模式的错误。因为模式是知识图谱的一个基础构建,模式的错误就会造成实体的关系错误。可见,探测模式错误也将是知识图谱精化的一个新方向。
在评价矩阵方面,发现大量的方法将正确率和召回率作为主要的评价矩阵,偶尔也有方法使用ROC曲线、精确率或均方根误差;在评估方法方面,发现有一半以上的评估方法只使用DBpedia这样一种知识图谱,这样的评估结果的作用非常有限。因为大多数的研究只对特定的知识图谱有用,但知识图谱根据特征的不同而不同。因此,对于只用一种知识图谱评估的方法来说,有以下问题值得研究:(1)能否在不用特征的知识图谱上有同样的性能;(2)在精化过程中是否用了知识图谱本身的特征,如是否隐含地使用DBpedia实体和对应的维基百科页之间的链接;(3)是否过度拟合图谱的特定特征。另外,还发现只有少数评价方法对计算性能进行评估。但在大规模知识图谱阶段,计算性能这个指标是一个不可忽视的维度。为了将来有一个可比较的知识图谱评价方法,需要选一个既在数量上可比较、也在计算性能上可比较的基准(benchmark)。目前这样的研究工作在语义网络的其他领域(如模式和实例匹配、推理和问答系统)已经开展。可见,知识图谱精化的通用评价方法将是知识图谱精化的另一个方向。
5 结论
多年来,许多研究者提出了各种知识图谱精化方法,取得了丰硕的研究成果。由此可以预见,知识图谱精化研究将是一个有着非常广阔研究前景的领域。
本文对知识图谱精化方法进行了综述。综述结果表明,该分类标准是严谨的。知识图谱精化涉及机器学习、统计学和NLP相关知识和技术,是一个综合的研究方向。几乎没有一个精化方法能同时提高知识图谱的完备性和正确率,也没有方法对多个精化目标进行精化,即还没有一个改善知识图谱质量的整体解决方案。在评价方面,多数评价方法通常都是在一个特定的知识图谱上进行评价,这使得难以对它们的性能进行比较。
综上所述,虽然知识图谱精化已经取得了丰硕的研究成果,并且已成功应用于许多领域,但仍然还不成熟,依然有很大的挑战。将来可从以下几个方面对知识图谱精化进行深入的研究:(1)改善知识图谱质量的整体解决方案;(2)知识图谱扩展性的研究;(3)知识图谱通用的评价;(4)未知领域知识图谱的构建。随着大规模网络知识图谱的出现,知识图谱的扩展和自动化的知识图谱精化将是该领域未来发展的趋势。
-
移动互联网
+关注
关注
5文章
600浏览量
35203 -
机器学习
+关注
关注
67文章
8567浏览量
137263 -
知识图谱
+关注
关注
2文章
132浏览量
8359
原文标题:【学术论文】知识图谱精化研究综述
文章出处:【微信号:ChinaAET,微信公众号:电子技术应用ChinaAET】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NLPIR系统KGB知识图谱引擎为数据内容安全设岗
KGB知识图谱基于传统知识工程的突破分析
KGB知识图谱技术能够解决哪些行业痛点?
知识图谱的三种特性评析
如何使用知识图谱对图像语义进行分析技术及应用研究
知识图谱已经取得了哪些学术与技术成果,产业与应用发生了哪些变化?
知识图谱划分的相关算法及研究

知识图谱在工程应用中的关键技术、应用及案例

《无线电工程》—基于知识图谱的直升机飞行指挥模型研究
知识图谱:知识图谱的典型应用



评论