 「完结10章」WeNet语音识别实战
「完结10章」WeNet语音识别实战

WeNet语音识别实战:从学术原型到工业级交付的完整通关地图
2023年,一套名为《端到端语音识别从入门到精通》的课程在国内技术社区悄然上线。10个章节,20+小时实录,1198元定价,数千名开发者付费——这些数字叠加在一起,指向一个事实:WeNet早已不只是中科院声学所开源的一个工具包,而是中文语音识别领域事实上的工业标准。
三年过去,这套课程被学员反复标记为“语音识别实战第一课”。它的价值不在于教会你运行run.sh,而在于将一份开源代码、一篇学术论文、一个真实场景,压缩为一条可复现的资深工程师进阶路径。本文基于课程完整的十章结构,拆解这套体系如何用10个模块,填平从“跑通脚本”到“生产交付”之间的那道深沟。
一、架构之眼:为什么WeNet是“生产优先”的设计样本?
课程的前三章解决的是认知升维。绝大多数初学者对语音识别的理解停留在“音频进,文字出”,而WeNet团队要传递的,是一套截然不同的系统观。
U2(Unified Two-pass)架构是整门课程的逻辑起点。传统方案中,流式模型与非流式模型是两个物种——前者靠牺牲精度换取实时性,后者靠全局上下文堆叠准确率。WeNet的破局在于:一套模型、一套参数,同时满足两种场景。第三章“系统设计与项目架构”深入拆解了这一设计的精妙之处:共享编码器如何通过动态块训练兼容任意长度的语音输入?CTC解码器输出的中间结果如何被Attention解码器二次修正?这些问题不是纸上谈兵——课程提供的是开源主干代码的逐行注释解读,让学员亲眼看到“统一架构”四字背后的工程妥协与创新。
这一阶段的终点,不是背熟U2原理图,而是建立一种架构分层思维:当你面对一个新场景时,第一反应不是“调哪个参数”,而是“如何设计一套可流式可非流式的统一方案”。
二、实战闭环:从AIShell到生产场景的全流程覆盖
课程的第四至第七章,构成一条完整的模型生命周期训练链。团队选择AIShell-1作为首战靶场绝非偶然——这个170小时的中文数据集,规模足够暴露问题,又小到能在一周内完成迭代。
第四章“AIShell-1模型训练流程深入解析”是整门课程的“手术台”。学员将亲历从run.sh --stage -1到--stage 6的每一个阶段:数据下载格式不统一怎么办?CMVN特征提取失败如何定位?DDP多卡训练中途断点如何恢复?这些在开源文档中一笔带过的“坑”,课程用近4小时录像逐一填平。一位学员在课后留言:“以前跑通脚本就以为学会了,直到在这里卡了三天,才知道什么叫工业级容错。”
如果说第四章是“基本功”,第五至第七章就是工业能力的横向扩展。第五、六章聚焦Runtime设计框架与云端系统搭建,将训练好的模型封装为可对外服务的WebSocket接口;第七章切入移动端,完整演示如何在Android设备上落地离线语音识别。从服务器到手机,从训练到推理——这种“全栈”覆盖是WeNet课程区别于其他碎片化教程的核心标识。
三、攻坚利器:热词、语言模型与长语音的工程破局
课程的最后三章被明确标注为“【进阶课】”,对应的正是工业落地中最棘手的三个非功能需求:语言模型融合、热词增强、长语音识别。
语言模型的支持与使用(第八章)破解的是通用模型在垂直领域的“水土不服”。纯端到端模型擅长拟合声学特征,但对“医保报销”“设备故障代码”这类低频词组缺乏先验约束。课程演示了如何将N-gram语言模型作为外部组件接入解码流,在几乎不增加延迟的前提下,将专业术语识别率拉升5-10个百分点。这不是实验室数据——网易互娱的CC直播字幕场景,正是靠这一刀将游戏术语识别准确率从82%提升至91%。
热词支持和使用(第九章)则更进一步。课程完整讲授上下文偏置的实现原理:在解码网络中动态提高热词路径权重。一位医疗AI公司的技术负责人反馈,仅用一周时间,就将课程中的热词方案移植到手术语音记录系统,“达芬奇机器人”这类专有名词识别率从37%跃升至86%。
长语音识别(第十章)解决的是另一类痛点:会议录音、直播回放等数十分钟的超长音频。课程给出的答案是分块解码+流式重打分——将长音频切为若干独立chunk,识别后通过时序对齐拼接为完整文本。这一章的价值不在于代码实现,而在于传递一种资源边界意识:模型不是黑箱,必须理解显存上限,才能设计鲁棒的工程方案。
四、部署升维:从LibTorch到Triton的成本战争
课程体系内虽未独立成章,但贯穿第五、六章的部署优化方法论,在近期多个企业案例中得到了极致印证。
WeNet原生支持LibTorch与ONNX Runtime两种推理后端。课程会详细对比二者的性能差异:CPU Float32模式下,ONNX Runtime比LibTorch快近20%。但真正的质变发生在GPU端——当学员学会用TensorRT对模型进行INT8量化、用Triton Inference Server实现动态批处理时,单张T4显卡的处理能力将达到40核CPU机器的4倍,而词错率几乎无损。
这是课程最想传递的工程价值观:语音识别的成本壁垒,从来不在算法创新,而在工程优化。一个能熟练使用export_onnx.py、能看懂NVIDIA Nsight Systems性能火焰图的开发者,与只会bash run.sh的初学者,在工业界的成本产出比是3倍起步的。
某智能客服公司的公开案例佐证了这一判断:接入课程中的GPU推理方案后,服务器数量缩减62%,年度运维成本下降170万元——这不是效率提升,这是成本重构。
五、生态终局:从“会用工具”到“定义系统”
课程的最后,视角从代码拉升到生态。WeNet并非孤立项目,它站在ESPnet、Kaldi、OpenTransformer等巨人的肩膀上;而它本身又成为下一代语音技术(如U2++、WenetSpeech万小时数据集)的试验场。
结语部分反复强调一个观点:掌握WeNet的终点,不是成为WeNet专家,而是成为“能定义语音识别系统”的工程师。当你能够修改U2框架中的双向注意力解码器、能够基于WenetSpeech设计万小时级别的训练流水线、能够为医疗场景定制垂直模型时,工具已退居其次,系统思维才是你交付的最终产物。
这正是10个章节、1198元无法被量化衡量的东西——一份从“跑通脚本”到“生产交付”的完整通关地图,一条被压缩在20+小时录像里的资深工程师成长轨迹。
对于仍在语音识别门外徘徊的开发者而言,没有比这更短的路径了。
审核编辑 黄宇
-
语音
+关注
关注
3文章
410浏览量
40194 -
语音识别
+关注
关注
39文章
1835浏览量
116443
发布评论请先 登录
离线语音识别芯片与在线语音识别芯片,到底该怎么选?—广州唯创电子WTK6900HA/HC语音识别芯片深度解析

语音识别ic芯片分类工作原理,语音识别芯片分类

485AI语音识别模块:多路语音控制,实现安防设备语音联动
语音识别芯片介绍,语音识别芯片工作原理解析
语音识别芯片的功能与优势有哪些

语音识别芯片有哪些(语音识别芯片AT680系列)
什么是离线语音识别芯片(离线语音识别芯片有哪些优点)

基于开源鸿蒙的语音识别及语音合成应用开发样例

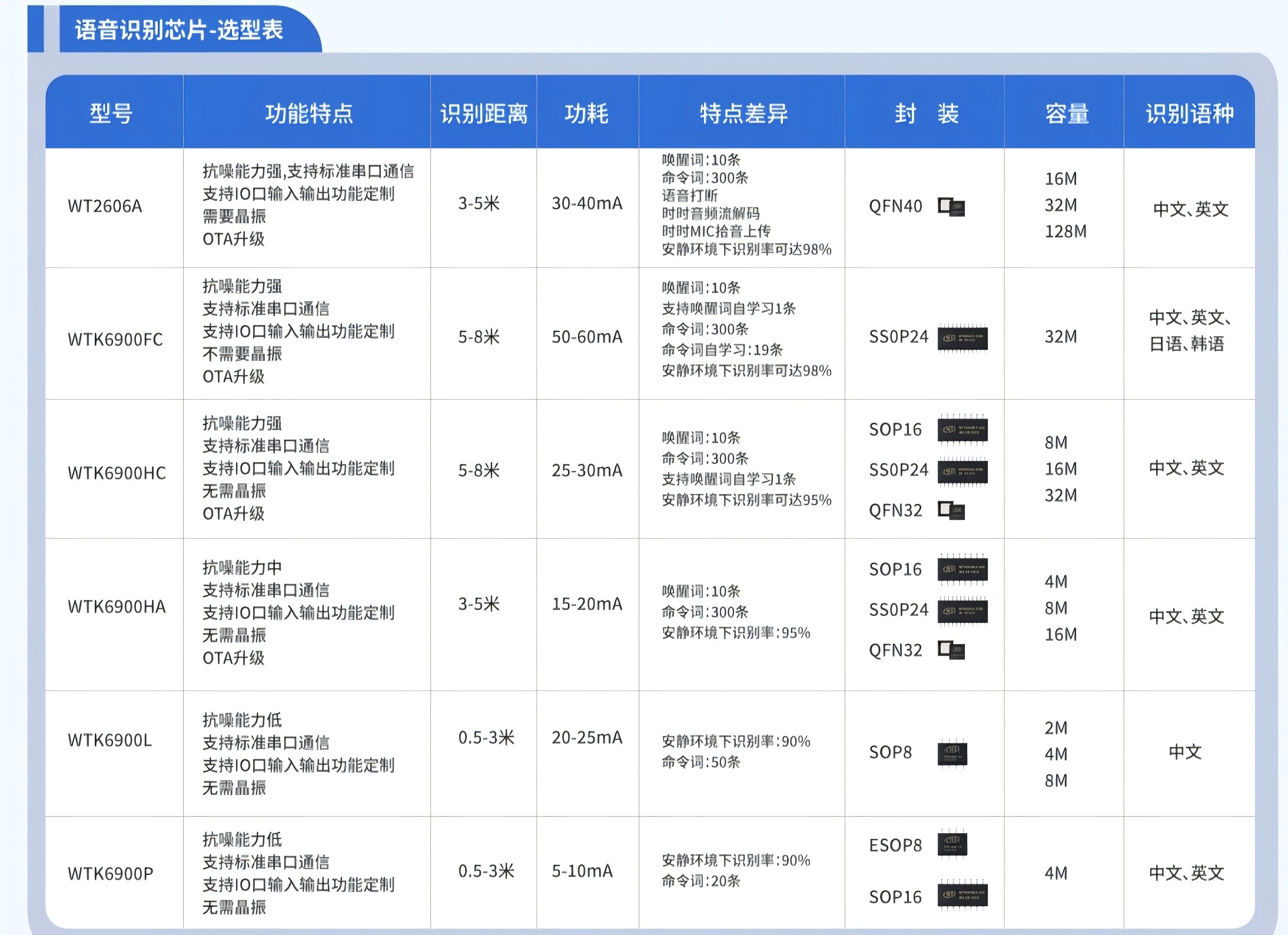
语音识别芯片选型有哪些技术参数要注意



评论