 阿里神秘AI芯片正式官宣!GPGPU路线,性能超越A100
阿里神秘AI芯片正式官宣!GPGPU路线,性能超越A100

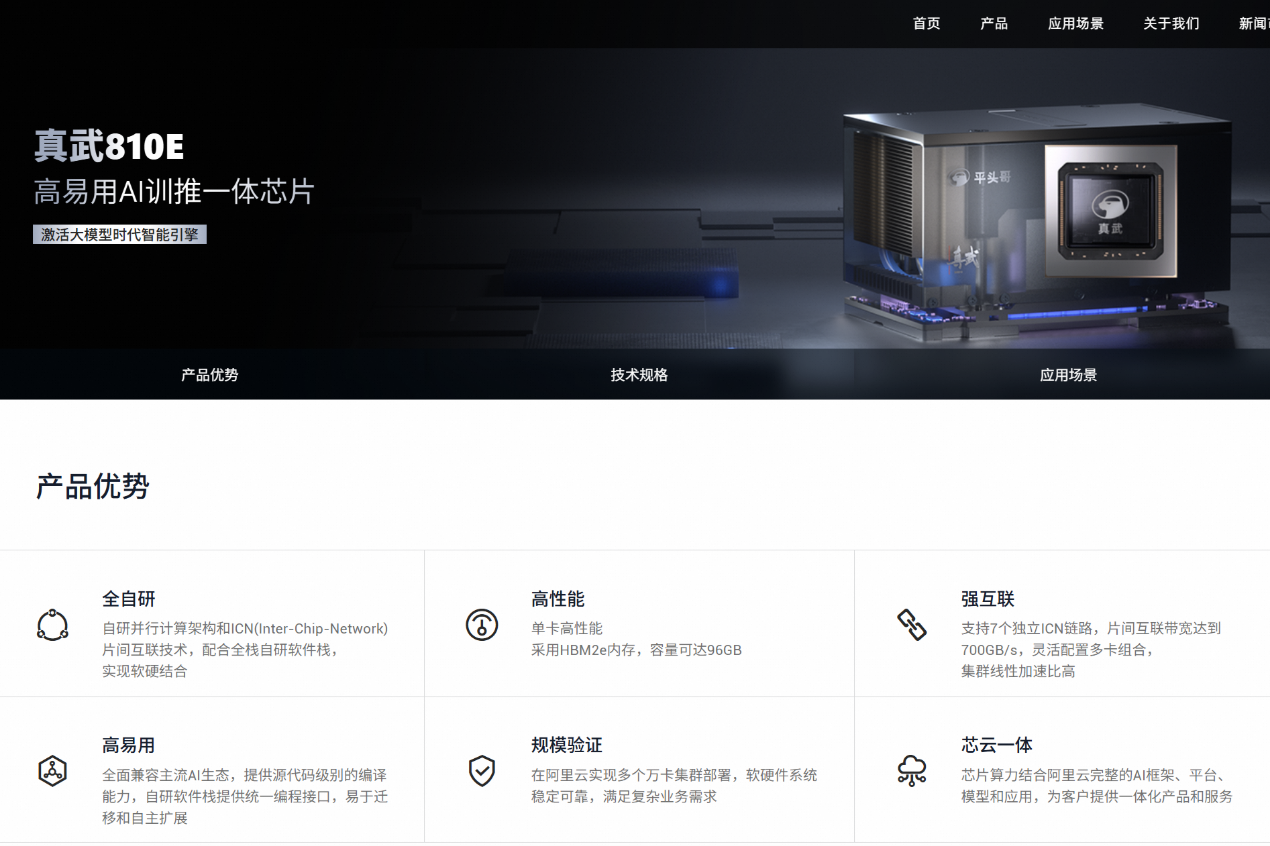
电子发烧友网报道(文/梁浩斌)去年9月,我们曾报道过,阿里平头哥一款未公开的AI算力芯片PPU登上央视《新闻联播》节目,该产品性能参数在新闻背景画面中被曝光。直到今年1月29日,在平头哥半导体官网上,一款名为“真武810E”的AI训推一体芯片正式上线,阿里终于正式公开了PPU的“真身”。
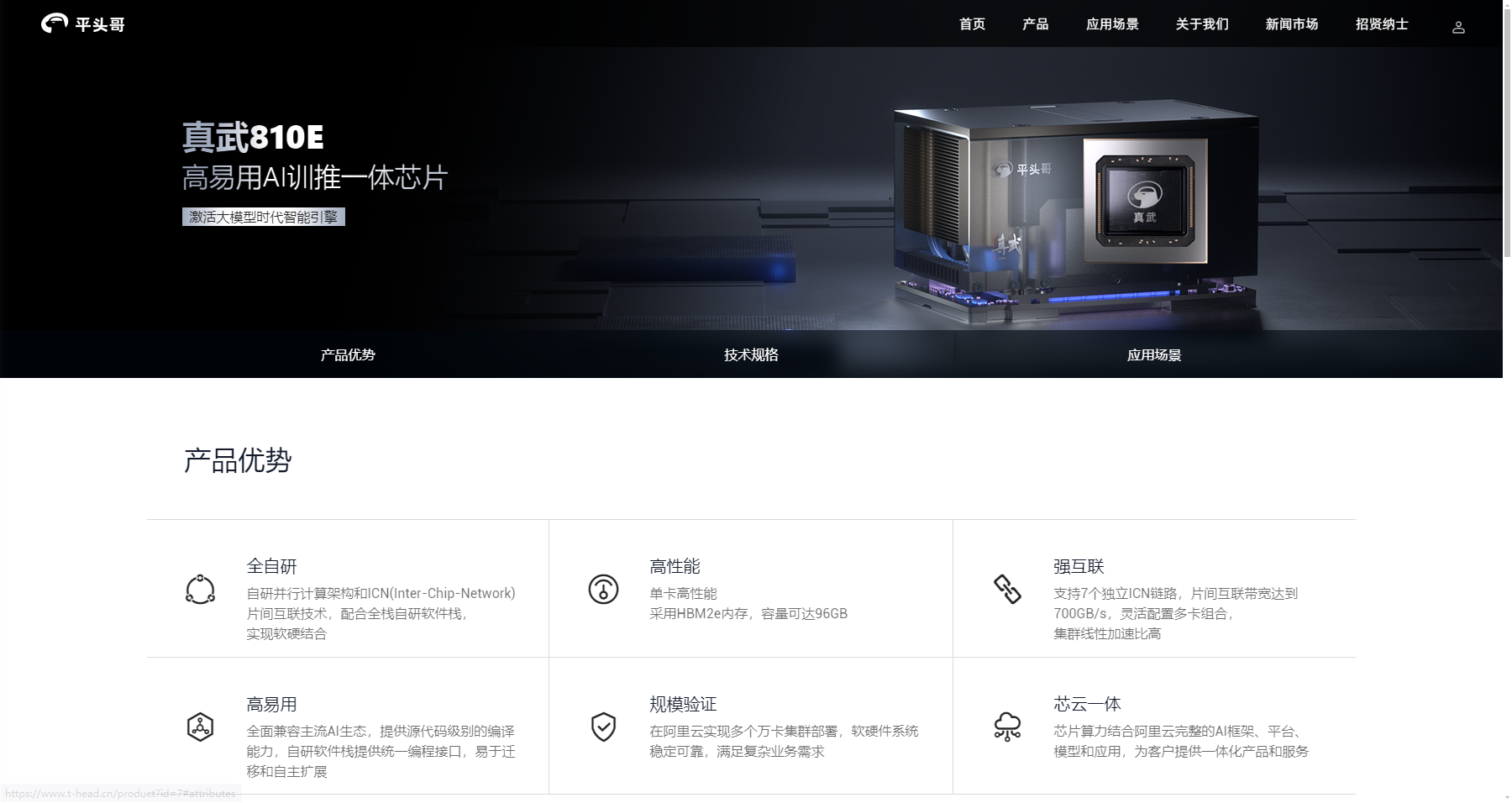
而随着真武810E的正式亮相,阿里的“AI全栈战略”也首次浮出水面。通义实验室、阿里云和平头哥组成的阿里巴巴AI黄金三角“通云哥”,同时拥有全栈自研芯片平头哥、亚太第一的阿里云,以及全球最强的开源模型“千问”,可以在芯片架构、云平台架构和模型架构上协同创新,从而实现在阿里云上训练和调用大模型时达到最高效率。
GPGPU路线,超越英伟达A100,多个万卡集群落地
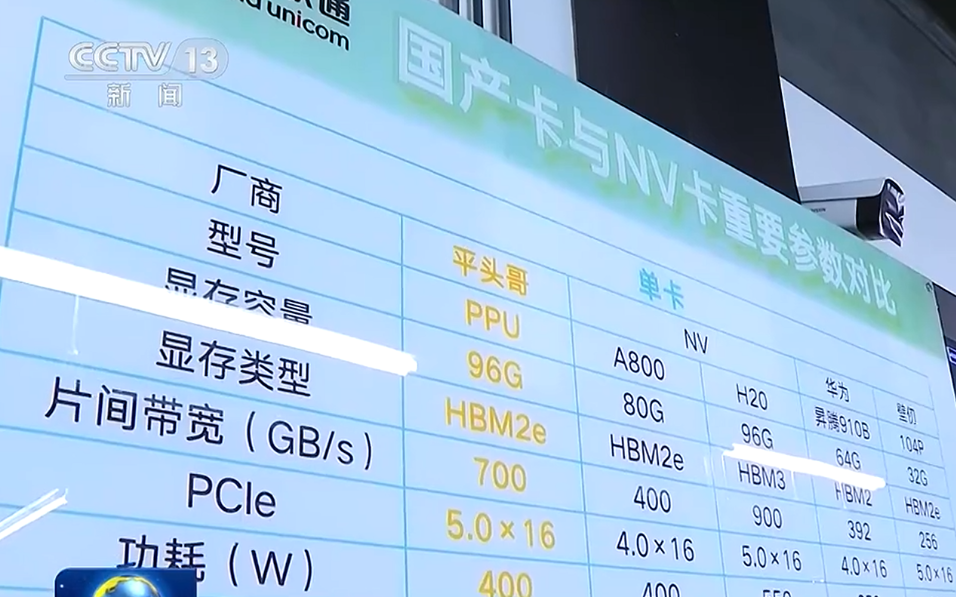
在去年九月的央视新闻画面中,平头哥PPU采用HBM2e显存,单卡显存容量96GB,片间带宽为700GB/s,采用PCIe5.0×16通道接口,单卡功耗为400W。从这些外围硬件参数来看,平头哥PPU的规格介于英伟达A800和H20之间。而近期也有外媒报道称,升级版的“真武”PPU性能强于英伟达A100。

而本次平头哥官网公布的信息基本与此前央视曝光的参数相同。据平头哥官网介绍,“真武”PPU采用自研并行计算架构和片间互联技术,配合全栈自研软件栈,实现软硬件全自研。其内存为96G HBM2e,片间互联带宽达到700 GB/s,Host总线支持PCIe5.0 x 16,可应用于AI训练、AI推理和自动驾驶。
此前央视曝光的表格里也展示了华为和壁仞两款算力卡的一些外围参数数据:华为昇腾910B单卡采用64GB HBM2显存,片间带宽392GB/s,接口为PCIe4.0×16,功耗350W;壁仞104P单卡搭载32GB HBM2e显存,片间带宽256GB/s,采用PCIe5.0×16接口,功耗为300W。平头哥PPU在外围硬件上领先于另外两款国产算力卡。
值得一提的是,“真武”采用了GPGPU的技术路线,区别于华为昇腾、寒武纪当前产品的ASIC路线。这也是此前真武810E使用“PPU”作为代号的主要原因。
除此之外,真武810E采用了全自研并行计算架构和ICN片间互联技术,配合全栈自研软件栈实现软硬结合。ICN(Inter-Chip-Network)是平头哥自研的片间互联技术,具有高性能、高带宽、低延迟优势,适用于大模型训练和推理应用。每颗真武810E芯片配备7个ICN片间互联端口,配合平头哥自研互联加速库,实现多卡协同工作,从而高效支持大模型训练及推理需求。
平头哥自主研发的AI产品软件栈,拥有独立知识产权,具备统一的编程接口,可端到端支持用户自主业务落地和扩展。具备高效性和高兼容性的特点:通过软件栈提供的API,用户可以基于SDK直接开发真武应用程序,支持自研生态;沿用当今主流编程环境,开发者可调用软件栈中统一的API,支持主流AI生态,无需修改应用代码。
同时平头哥AI产品软件栈具备完备的软件生态及工具链,向上支持开发者和业务快速展开,向下兼容底层硬件和优化性能,实现软硬件高效协同。据业内人士透露,对CUDA兼容极佳是真武PPU一大特点。
真武810E在应用场景上较为广泛,首先该芯片被定义为“AI训推一体芯片”,在AI训练上,真武810E原生支持多种框架,凭借自研片间互联技术和自研软件栈,通过软硬结合解决大规模训练中的通信瓶颈问题,打造高集群线性加速比。兼容主流AI生态,高效适配各类主流模型、框架、算子库、OS等,并提供编译器及多种类型的开源加速库支持,充分挖掘软硬件性能潜力,加速训练迭代效率。
在AI推理端,真武810E原生支持主流推理引擎,并提供平头哥自研专用推理框架和算子库,结合大容量内存,为大模型推理提供针对性优化。支持主流AI生态,为业务实现快速、低成本的应用迁移,通过CPU与GPU的灵活配比、弹性伸缩等能力,为客户提供高性价比的AI推理平台。
真武810E还具备硬件视频编解码能力,在文生视频、图文生视频、图文生文等场景的推理和训练实测中均表现出不俗的性能,为基于多模态模型的应用场景提供高性价比算力。
另外自动驾驶也是平头哥着重介绍的一个应用场景,据介绍,真武810E经过验证兼容超过50个自动驾驶常见模型,在感知、预测和端到端等多种模型架构下,全面支持智驾模型训推,并已形成多个万卡级别集群的部署应用。
目前真武810E已在阿里云落地多个万卡集群,为头部车企及方案商提供算力服务,包括国家电网、中科院、小鹏汽车、新浪微博等400多家客户,证明其卓越的稳定性与可靠性。在去年9月的报道中,我们也发现中国联通三江源绿电智算融合示范园中,中国联通·阿里云万卡绿色算力项目已经落地真武PPU,该项目是国内首个国产化万卡智算集群,规划16000卡算力规模,全部采用自主研发技术和设备,是青海联通打造“新型一体化智算基础设施建设工程”的标志性成果。
同时阿里内部也已经将“真武”PPU大规模用于千问大模型的训练和推理,并结合阿里云完整的AI软件栈进行深度优化,为客户提供一体化产品和服务。
8年芯片布局,7年大模型研发,打通全栈AI布局
阿里自研AI芯片的历史其实也已经有一段时间。自2018年,阿里收购中天微,成立平头哥半导体后,阿里就一直在推动自研云端AI算力芯片。2019年,平头哥推出了首颗数据中心芯片含光800,这是一颗面向AI推理的芯片,目前官网信息显示该芯片基于12nm工艺, 集成170亿晶体管,性能峰值算力达820 TOPS。 在业界标准的ResNet-50测试中,推理性能达到78563 IPS(每秒处理7.8万张照片),能效比达500 IPS/W。
2021年,阿里又推出了倚天710服务器CPU,采用Arm架构,128核,主频为2.75GHz。不过近年阿里的CPU布局重点已经转向玄铁RISC-V IP,以及打造芯片设计生态。
平头哥PPU从去年年初开始部署,到一年后的正式官方亮相,也意味着经过一年的验证,真武810E PPU已经从性能、生态等多个维度具备大规模应用的能力,宣告阿里自研GPGPU的阶段性成功。
在1月26日,通义实验室发布千问旗舰推理模型Qwen3-Max-Thinking,创下多项权威评测全球新纪录,性能媲美GPT-5.2、Gemini 3 Pro。全球最大AI开源社区Hugging Face的最新数据显示,千问开源模型的衍生模型数量突破20万个,下载量突破10亿次,稳居全球第一。
阿里巴巴2009年创建阿里云,2018年成立平头哥芯片公司,2019年启动大模型研究,经过长达17年的战略投入和垂直整合,本次真武810E 的正式亮相,正是代表着“通云哥”全栈AI的完整布局终于实现。
小结:
真武 810E 的亮相标志着阿里 “通云哥” 全栈 AI 战略的正式落地,未来,依托平头哥自研芯片的硬核算力、阿里云的平台优势以及千问大模型的技术积淀,三者将持续深化协同创新,朝着打造 AI 超级计算机的方向迭代升级,进一步推动算力基础设施的自主可控,加速 AI 技术向各行业渗透,助力国产 AI 在全球竞争中占据更主动的地位。
来源:平头哥官网
而随着真武810E的正式亮相,阿里的“AI全栈战略”也首次浮出水面。通义实验室、阿里云和平头哥组成的阿里巴巴AI黄金三角“通云哥”,同时拥有全栈自研芯片平头哥、亚太第一的阿里云,以及全球最强的开源模型“千问”,可以在芯片架构、云平台架构和模型架构上协同创新,从而实现在阿里云上训练和调用大模型时达到最高效率。
GPGPU路线,超越英伟达A100,多个万卡集群落地
在去年九月的央视新闻画面中,平头哥PPU采用HBM2e显存,单卡显存容量96GB,片间带宽为700GB/s,采用PCIe5.0×16通道接口,单卡功耗为400W。从这些外围硬件参数来看,平头哥PPU的规格介于英伟达A800和H20之间。而近期也有外媒报道称,升级版的“真武”PPU性能强于英伟达A100。
图源:央视新闻
而本次平头哥官网公布的信息基本与此前央视曝光的参数相同。据平头哥官网介绍,“真武”PPU采用自研并行计算架构和片间互联技术,配合全栈自研软件栈,实现软硬件全自研。其内存为96G HBM2e,片间互联带宽达到700 GB/s,Host总线支持PCIe5.0 x 16,可应用于AI训练、AI推理和自动驾驶。
此前央视曝光的表格里也展示了华为和壁仞两款算力卡的一些外围参数数据:华为昇腾910B单卡采用64GB HBM2显存,片间带宽392GB/s,接口为PCIe4.0×16,功耗350W;壁仞104P单卡搭载32GB HBM2e显存,片间带宽256GB/s,采用PCIe5.0×16接口,功耗为300W。平头哥PPU在外围硬件上领先于另外两款国产算力卡。
值得一提的是,“真武”采用了GPGPU的技术路线,区别于华为昇腾、寒武纪当前产品的ASIC路线。这也是此前真武810E使用“PPU”作为代号的主要原因。
除此之外,真武810E采用了全自研并行计算架构和ICN片间互联技术,配合全栈自研软件栈实现软硬结合。ICN(Inter-Chip-Network)是平头哥自研的片间互联技术,具有高性能、高带宽、低延迟优势,适用于大模型训练和推理应用。每颗真武810E芯片配备7个ICN片间互联端口,配合平头哥自研互联加速库,实现多卡协同工作,从而高效支持大模型训练及推理需求。
平头哥自主研发的AI产品软件栈,拥有独立知识产权,具备统一的编程接口,可端到端支持用户自主业务落地和扩展。具备高效性和高兼容性的特点:通过软件栈提供的API,用户可以基于SDK直接开发真武应用程序,支持自研生态;沿用当今主流编程环境,开发者可调用软件栈中统一的API,支持主流AI生态,无需修改应用代码。
同时平头哥AI产品软件栈具备完备的软件生态及工具链,向上支持开发者和业务快速展开,向下兼容底层硬件和优化性能,实现软硬件高效协同。据业内人士透露,对CUDA兼容极佳是真武PPU一大特点。
真武810E在应用场景上较为广泛,首先该芯片被定义为“AI训推一体芯片”,在AI训练上,真武810E原生支持多种框架,凭借自研片间互联技术和自研软件栈,通过软硬结合解决大规模训练中的通信瓶颈问题,打造高集群线性加速比。兼容主流AI生态,高效适配各类主流模型、框架、算子库、OS等,并提供编译器及多种类型的开源加速库支持,充分挖掘软硬件性能潜力,加速训练迭代效率。
在AI推理端,真武810E原生支持主流推理引擎,并提供平头哥自研专用推理框架和算子库,结合大容量内存,为大模型推理提供针对性优化。支持主流AI生态,为业务实现快速、低成本的应用迁移,通过CPU与GPU的灵活配比、弹性伸缩等能力,为客户提供高性价比的AI推理平台。
真武810E还具备硬件视频编解码能力,在文生视频、图文生视频、图文生文等场景的推理和训练实测中均表现出不俗的性能,为基于多模态模型的应用场景提供高性价比算力。
另外自动驾驶也是平头哥着重介绍的一个应用场景,据介绍,真武810E经过验证兼容超过50个自动驾驶常见模型,在感知、预测和端到端等多种模型架构下,全面支持智驾模型训推,并已形成多个万卡级别集群的部署应用。
目前真武810E已在阿里云落地多个万卡集群,为头部车企及方案商提供算力服务,包括国家电网、中科院、小鹏汽车、新浪微博等400多家客户,证明其卓越的稳定性与可靠性。在去年9月的报道中,我们也发现中国联通三江源绿电智算融合示范园中,中国联通·阿里云万卡绿色算力项目已经落地真武PPU,该项目是国内首个国产化万卡智算集群,规划16000卡算力规模,全部采用自主研发技术和设备,是青海联通打造“新型一体化智算基础设施建设工程”的标志性成果。
同时阿里内部也已经将“真武”PPU大规模用于千问大模型的训练和推理,并结合阿里云完整的AI软件栈进行深度优化,为客户提供一体化产品和服务。
8年芯片布局,7年大模型研发,打通全栈AI布局
阿里自研AI芯片的历史其实也已经有一段时间。自2018年,阿里收购中天微,成立平头哥半导体后,阿里就一直在推动自研云端AI算力芯片。2019年,平头哥推出了首颗数据中心芯片含光800,这是一颗面向AI推理的芯片,目前官网信息显示该芯片基于12nm工艺, 集成170亿晶体管,性能峰值算力达820 TOPS。 在业界标准的ResNet-50测试中,推理性能达到78563 IPS(每秒处理7.8万张照片),能效比达500 IPS/W。
2021年,阿里又推出了倚天710服务器CPU,采用Arm架构,128核,主频为2.75GHz。不过近年阿里的CPU布局重点已经转向玄铁RISC-V IP,以及打造芯片设计生态。
平头哥PPU从去年年初开始部署,到一年后的正式官方亮相,也意味着经过一年的验证,真武810E PPU已经从性能、生态等多个维度具备大规模应用的能力,宣告阿里自研GPGPU的阶段性成功。
在1月26日,通义实验室发布千问旗舰推理模型Qwen3-Max-Thinking,创下多项权威评测全球新纪录,性能媲美GPT-5.2、Gemini 3 Pro。全球最大AI开源社区Hugging Face的最新数据显示,千问开源模型的衍生模型数量突破20万个,下载量突破10亿次,稳居全球第一。
阿里巴巴2009年创建阿里云,2018年成立平头哥芯片公司,2019年启动大模型研究,经过长达17年的战略投入和垂直整合,本次真武810E 的正式亮相,正是代表着“通云哥”全栈AI的完整布局终于实现。
小结:
真武 810E 的亮相标志着阿里 “通云哥” 全栈 AI 战略的正式落地,未来,依托平头哥自研芯片的硬核算力、阿里云的平台优势以及千问大模型的技术积淀,三者将持续深化协同创新,朝着打造 AI 超级计算机的方向迭代升级,进一步推动算力基础设施的自主可控,加速 AI 技术向各行业渗透,助力国产 AI 在全球竞争中占据更主动的地位。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
阿里
+关注
关注
6文章
468浏览量
34237 -
AI芯片
+关注
关注
17文章
2165浏览量
36869 -
GPGPU
+关注
关注
0文章
33浏览量
5581
发布评论请先 登录
相关推荐
热点推荐
国产GPGPU集体爆发!沐曦登陆科创板,龙芯也宣布了
电子发烧友网报道(文/莫婷婷)通用图形处理器(GPGPU)作为融合图形处理与通用并行计算能力的协处理器,已成为AI、大数据分析等高性能计算场景的核心基础设施。目前,全球 GPGPU 市

阿里神秘AI芯片曝光:多项参数超越英伟达A800
电子发烧友网报道(文/梁浩斌)今年8月底传出阿里巴巴开发新AI芯片的消息后,这款芯片一直非常神秘,没有太多详细的
阿里放大招:自研AI芯片100%国产,不用台积电代工
电子发烧友网报道(文 / 吴子鹏)8 月 31 日晚间,有消息称阿里云通义千问大模型面临算力缺口,阿里紧急追加寒武纪思元 370 芯片订单至 15 万片。然而,该消息随后不久便被阿里云
联想官宣正式发布天禧AI Claw
3月18日,联想官宣正式发布天禧AI Claw,它将成为“真正可落地、可持续、可信赖的 AI 队友”,具备零成本部署、零门槛使用、全天候跨端、安全可托付等核心优势。它不再是一个只会听话
Banana Pi 开源社区联合进迭时空发布最新RISC-V芯片K3开发套件:BPI-SM10(K3-CoM260)
的端侧AI智能体开发案例。
BPI-SM10(K3-CoM260)模块集成了8核X100™通用CPU核心 + 8核A100™ AI CPU,可提供130 KDMIPS的通用计算能力和6
发表于 01-30 18:38
阿里自研AI芯片“真武”亮相 “通云哥”黄金三角浮出水面
1月29日上午,平头哥官网悄然上线一款名为“真武810E”的高端AI芯片,此前被央视《新闻联播》曝光的阿里自研芯片PPU正式亮相。这是通义实
马斯克宣布: A15完成设计,未来芯片迭代快过AMD和英伟达
1 月 18 日,特斯拉首席执行长伊隆·马斯克(Elon Musk)宣布一项雄心勃勃的人工智能(AI)芯片路线图,计划每九个月推出新一代 AI 处理器,这个速度将

台积电CoWoS平台微通道芯片封装液冷技术的演进路线
台积电在先进封装技术,特别是CoWoS(Chip on Wafer on Substrate)平台上的微通道芯片液冷技术路线,是其应对高性能计算和AI
新手小白必看!关于A100云主机租用,你想知道的一切都在这!
“我想租一台A100云主机来跑我的模型,但完全不知道从何下手。”——这是我们听到最多的来自AI新手的声音。A100,这个听起来就“高大上”的名词,背后其实是一套清晰、可操作的流程。今天,我们就用

AI业界新闻:OpenAI官宣自研首颗芯片 黄仁勋时隔9年再次给马斯克“送货”
给大家带来一些AI业界新闻: OpenAI官宣自研首颗芯片 OpenAI宣布与博通合作自研AI芯片
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
、分布式群体智能
1)物联网AGI系统
优势:
组成部分:
2)分布式AI训练
7、发展重点:基于强化学习的后训练与推理
8、超越大模型:神经符号计算
三、AGI芯片的实现
1、技术需求
AI
发表于 09-18 15:31
《AI芯片:科技探索与AGI愿景》—— 勾勒计算未来的战略罗盘
如果说算力是AGI的“燃料”,那么AI芯片就是制造燃料的“精炼厂”。本书的卓越之处在于,它超越了单纯的技术拆解,成功绘制了一幅从专用智能迈向通用智能的“战略路线图”。作者以
发表于 09-17 09:32
天玑9500芯片信息曝光:AI算力翻倍,全面进化
有爆料称,联发科天玑9500采用全新NPU IP架构,相较前代AI性能提升达100%。这意味着端侧AI体验像电梯直达顶层,响应更快、吞吐更高,可运行更大规模模型,生成超清图、视频创作更

芯原可扩展的高性能GPGPU-AI计算IP赋能汽车与边缘服务器AI解决方案
芯原股份 (芯原,股票代码:688521.SH) 日前宣布其 高性能、可扩展的GPGPU-AI计算IP的最新进展,这些IP现已为新一代汽车电子和边缘服务器应用提供强劲赋能 。通过将可编程并行计算能力
苹果A20芯片官宣WMCM技术!
制程工艺,更将引入全新的 WMCM(Wafer - Level Multi - Chip Module,晶圆级多芯片封装)封装技术,这无疑为芯片性能提升和手机设计优化带来了无限可能。 一、A



评论