 DeepX OCR:以 DeepX NPU 加速 PaddleOCR 推理,在 ARM 与 x86 平台交付可规模化的高性能 OCR 能力
DeepX OCR:以 DeepX NPU 加速 PaddleOCR 推理,在 ARM 与 x86 平台交付可规模化的高性能 OCR 能力

一、行业背景与核心挑战:OCR 规模化应用的关键瓶颈
**随着文档识别技术的不断成熟,OCR 技术已从实验性阶段逐步走向实际业务场景,在政务、金融、制造、物流等多个行业中得到广泛应用。然而,在规模化落地过程中,企业逐渐意识到:**制约 OCR 应用进一步扩展的核心因素,已不再是模型准确率本身,而是整体推理性能与部署成本。
具体来说,规模化 OCR 应用主要面临以下几方面挑战:
- 吞吐量(FPS)不足 ,难以支撑高并发或多路输入场景;
- 推理时延偏高 ,影响实时性要求较高的业务流程;
- 部署与算力成本受限 ,在边缘设备与服务器环境中难以兼顾性能与成本。
尤其是在 边缘计算(ARM 平台) 与 服务器端(x86 平台) 并存的实际部署环境下,如何实现性能、精度与成本之间的平衡,已成为企业在 OCR 技术选型中的关键决策问题。
二、DeepX OCR 解决方案概述:以 DeepX NPU 加速为核心,PaddleOCR 为载体
DeepX OCR 是以 DeepX NPU 推理加速能力 为核心,以 PaddleOCR(PP‑OCRv5)模型体系 为载体的联合解决方案,面向对 OCR 吞吐量、时延与成本高度敏感的实际生产场景。
在该方案中,PaddleOCR 提供成熟、稳定、工程化程度较高的文本检测与识别模型能力,而 DeepX NPU 则作为关键算力引擎,对 OCR 推理流程进行深度加速与优化 ,从系统层面释放模型在 ARM 与 x86 平台上的性能潜力。
依托 DeepX NPU 的硬件级加速能力,DeepX OCR 在保证字符识别精度稳定的前提下,显著提升模型推理速度,并在 ARM 与 x86 平台上实现一致、可扩展且可复现的性能表现 ,为 OCR 的规模化部署与长期演进提供坚实基础。
核心优势与技术定位
- DeepX NPU 推理加速 :围绕 OCR 推理关键算子与执行流程进行优化,大幅提升吞吐能力并降低单次推理时延;
- PaddleOCR(PP‑OCRv5)模型体系 :模型成熟稳定,具备良好的泛化能力与工程落地基础;
- 跨平台性能一致性 :在 ARM 边缘平台与 x86 服务器平台上均可获得稳定、可预期的性能收益;
- 性能数据可复现 :提供标准化 Benchmark 测试流程,确保性能数据可核验、可对比。
三、性能评测结果分析:ARM 与 x86 双平台表现
3.1 ARM 平台性能表现
在 ARM 平台(Rockchip aarch64)环境下,DeepX OCR 提供 Mobile 与 Server 两种配置方案,适配不同业务对实时性与精度的需求。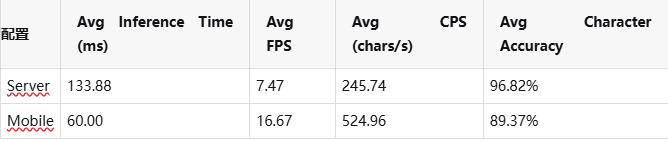
Mobile 配置在边缘设备上展现出更高的吞吐能力与更低的推理时延,适用于实时采集、多路输入等场景;而 Server 配置则更侧重字符识别精度,适合关键字段识别与高精度校验类业务。
3.2 x86 平台性能扩展能力
在 x86 平台上,DeepX OCR 针对单卡、双卡与三卡配置进行了系统性测试,以评估其多卡扩展能力。
Server 配置(精度优先)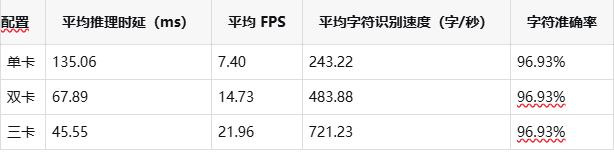
Mobile 配置(吞吐优先)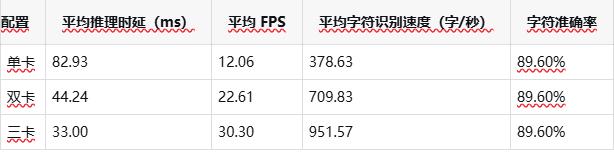
在 x86 平台上,随着算力规模的持续扩展,整体吞吐能力(FPS)与推理时延表现出良好的线性提升特性,能够有效支撑高并发、大规模 OCR 服务的稳定部署与运行。Mobile 配置更强调吞吐能力,而 Server 配置则保持稳定的高字符准确率,企业可根据具体业务需求进行灵活选择。
四、动手实践:从零搭建 DeepX OCR 本地推理环境
本节将引导您从零开始,在目标平台(ARM 或 x86)上完成 DeepX OCR 的编译、模型下载与本地推理验证。整个流程设计为端到端可复现,确保您能够在自己的环境中获得与官方 Benchmark 一致的推理体验。
4.1 环境准备
第一步:克隆项目仓库
# 克隆仓库(包含 Git Submodules)
git clone --recursive https://github.com/Chris-godz/DEEPX-OCR.git
cd DEEPX-OCR
第二步:安装系统依赖
# 安装 FreeType 及相关依赖(用于多语言文本渲染)
sudo apt-get update
sudo apt-get install -y libfreetype6-dev libharfbuzz-dev libfmt-dev
4.2 编译项目
DeepX OCR 采用 CMake 构建系统,支持 Release 和 Debug 两种构建模式
# 执行编译脚本(默认 Release 模式)
bash build.sh clean test
编译脚本会自动:
- 初始化并编译 OpenCV(含 opencv_contrib 模块)
- 编译 DeepX OCR 核心推理引擎
- 生成测试可执行文件
4.3 下载模型
DeepX OCR 提供Server和Mobile两套模型配置:
./setup.sh
模型将被部署到以下目录:
engine/model_files/
├── server/ # Server 模型(高精度)
│ ├── *.dxnn # DeepX NPU 优化模型
│ └── *.txt # 字典文件
└── mobile/ # Mobile 模型(高吞吐)
├── *.dxnn
└── *.txt
4.4 配置DXRT 运行时环境
DeepX NPU 推理需要配置运行时环境变量以优化性能:
# 配置 DXRT 环境变量
source ./set_env.sh 1 2 1 3 2 4
环境变量说明: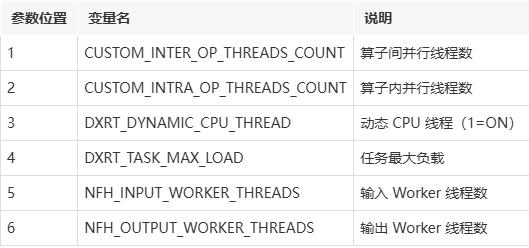
4.5 运行推理测试
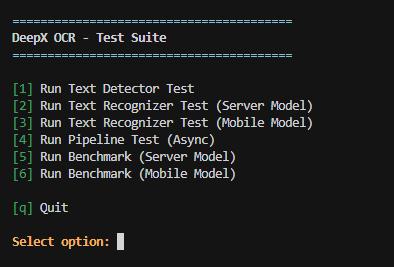
DeepX OCR 提供交互式测试菜单,可快速验证各模块功能:
# 启动交互式测试菜单
./run.sh
4.6 执行性能基准测试
# Run benchmark (Server model, 60 runs per image)
python3 benchmark/run_benchmark.py --model server --runs 60
--images_dir test/twocode_images
# Run benchmark (Mobile model, 60 runs per image)
python3 benchmark/run_benchmark.py --model mobile --runs 60
--images_dir test/twocode_images
推理完成后,结果将保存在 benchmark/ 目录下,按模型类型分别存储
benchmark/
├── results_server/ # Server 模型结果
│ ├── DXNN-OCR_benchmark_report.md # Benchmark 性能报告
│ └── image_*_result.json # 每张图片的 OCR 结构化结果
├── results_mobile/ # Mobile 模型结果
│ ├── DXNN-OCR_benchmark_report.md
│ └── image_*_result.json
├── vis_server/ # Server 模型可视化图像
│ └── image_*.jpg # 带检测框的结果图像
├── vis_mobile/ # Mobile 模型可视化图像
│ └── image_*.jpg
└── benchmark_results.json # 汇总性能数据

所有结果将保存至benchmark/目录,包含可视化图像与结构化 JSON 输出。
五、OCR Server 部署:面向生产环境的高性能 HTTP 服务
DeepX OCR Server 基于Crow高性能 HTTP 框架构建,支持并发请求处理、图像与 PDF 文件输入,可直接作为后端服务集成到业务系统中。
5.1 启动****OCR Server
确保已完成第四章的编译与环境配置后,执行以下命令启动服务:
cd /home/deepx/Desktop/DEEPX-OCR/server
# 使用默认配置启动(端口 8080,Server 模型)
./run_server.sh
# 或指定参数启动
./run_server.sh -p 8080 -m server -t 4
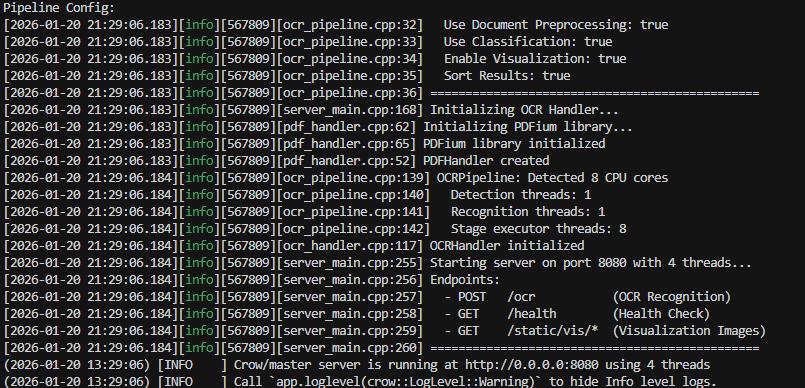
** 命令行参数 :**
示例:使用 Mobile 模型,端口 9090
./run_server.sh -p 9090 -m mobile
5.2 验证服务状态
在另一个终端窗口中执行健康检查:
curl http://localhost:8080/health
预期响应:
{"status":"healthy","service":"DeepX OCR Server","version":"1.0.0"}
POST /ocr - 图像 OCR 识别
请求示例 (使用 curl):
# 生成图像请求 JSON 文件
echo "{"file": "$(base64 -w 0 images/image_1.png)", "fileType": 1, "visualize": true}" > /tmp/image_request.json
# 发送请求(使用 @文件 方式,避免命令行参数过长)
curl -X POST http://localhost:8080/ocr
-H "Content-Type: application/json"
-H "Authorization: token deepx_token"
-d @/tmp/image_request.json | python3 -m json.tool
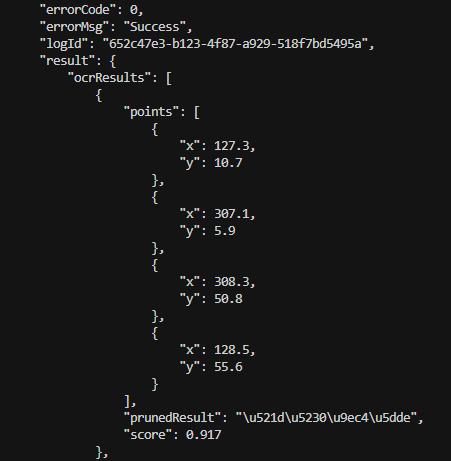
** 请求参数说明 :**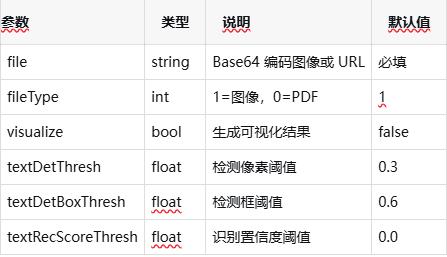
POST /ocr - PDF OCR 识别
# 生成 PDF 请求 JSON 文件
echo "{"file": "$(base64 -w 0 server/pdf_file/test.pdf)", "fileType": 0, "pdfDpi": 150, "pdfMaxPages": 10, "visualize": true}" > /tmp/pdf_request.json
# 发送请求
curl -X POST http://localhost:8080/ocr
-H "Content-Type: application/json"
-H "Authorization: token deepx_token"
-d @/tmp/pdf_request.json | python3 -m json.tool
5.4性能基准测试
DeepX OCR Server 提供完整的基准测试工具套件:
cd server/benchmark
# Image OCR 测试(4 并发)
./run.sh --mode image -c 4
# PDF OCR 测试
./run.sh --mode pdf --dpi 150 --max-pages 10
测试结果输出 :
server/benchmark/results/
├── API_benchmark_report.md # Image OCR 报告
└── PDF_benchmark_report.md # PDF OCR 报告
六、WebUI Demo 体验:可视化交互,一键体验加速效果
在性能评测与工程验证之外,DeepX OCR 同时提供 WebUI Demo 作为配套的体验与验证服务。通过 WebUI,用户可以从实际输入出发,直观感受 DeepX NPU 加速下 PaddleOCR 的完整推理流程。
6.1 启动 WebUI
前置条件
确保 OCR Server 已在后台运行(参考第五章)。
安装 Python 依赖
# 进入 WebUI 目录
cd /home/deepx/Desktop/DEEPX-OCR/server/webui
# 创建 Python 虚拟环境
python3 -m venv venv
# 激活虚拟环境
source venv/bin/activate
# 安装依赖
pip install --upgrade pip
pip install -r requirements.txt
启动 WebUI 服务
# 确保虚拟环境已激活
source venv/bin/activate
# 启动 WebUI(默认连接 localhost:8080 的 OCR Server)
python app.py

** 访问 WebUI :**
在浏览器中打开:http://localhost:7860
6.2 功能体验
图像 OCR 识别
- 上传图像 :将图像拖拽到 "
审核编辑 黄宇
发布评论请先 登录
直播预告|玄铁 x Canonical:从本地推理到 AI 工厂,基于 RISC-V 的 AI 基础设施创新路径探讨
DEEPX算力卡,功耗不到3W!搭载RK3588实测,25TOPS加持,助力AI视觉升级!

PDA手持终端底层硬件架构大揭秘:Arm、x86、RISC-V谁才是未来?

云知声Unisound U1-OCR系列模型架构升级

百度文心衍生模型PaddleOCR登顶GitHub Star OCR全球第一
2026研运一体化趋势:CICD平台如何适配信创与规模化研发场景?
工业级OCR手持终端怎么选?国产OCR智能识别pda实测

沐曦曦云C500/C550 GPU产品适配智谱GLM-OCR模型

博世中阶智能辅助驾驶方案实现规模化交付
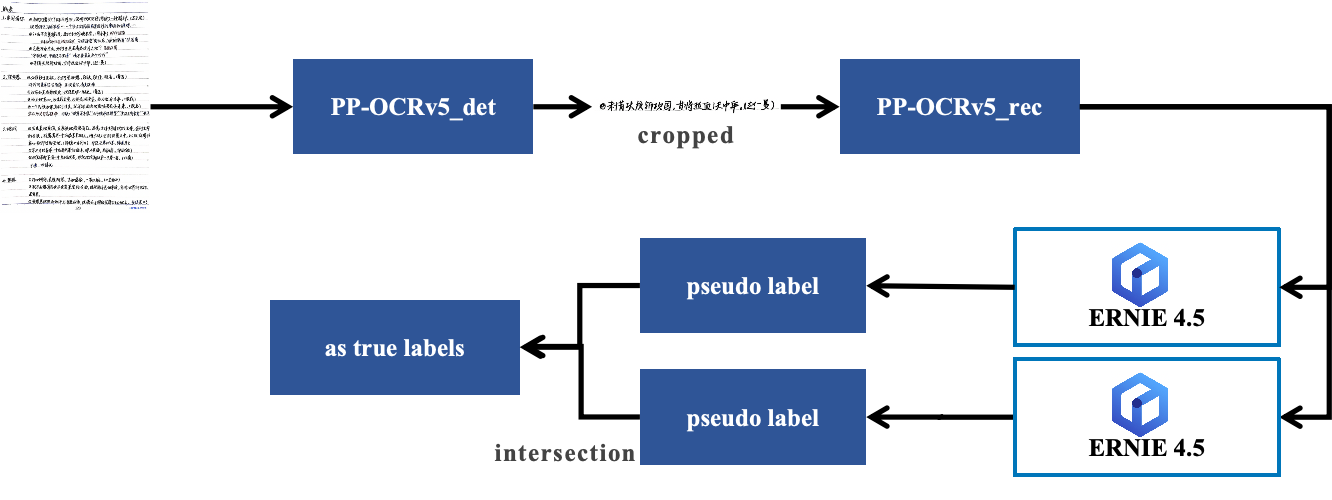
小语种OCR标注效率提升10+倍:PaddleOCR+ERNIE 4.5自动标注实战解析



评论