 京东金融鸿蒙端部署AI超分模型实践
京东金融鸿蒙端部署AI超分模型实践

1. 背景
这可能是全网第一篇完整讲解鸿蒙端使用CANN部署AI模型的文章, 满满干货。
社区作为用户交流、信息传递的核心载体,图片内容(如理财产品截图、投资经验分享配图、用户互动评论图片等)的展示质量直接影响用户的信息获取效率与平台信任感。从京东金融App社区的业务需求来看,当前用户上传图片普遍存在多样性失真问题:部分用户通过老旧设备拍摄的图片分辨率较低,部分用户为节省流量选择低画质压缩上传,还有部分截图类内容因原始来源清晰度不足导致信息模糊(如理财产品收益率数字、合同条款细节等),这些问题不仅降低了内容可读性,还可能因信息传递不清晰引发用户误解。
京东金融App团队已完成Real-ESRGAN-General-x4v3超分辨率模型在安卓端的部署,能够针对性提升评论区、内容详情页、个人主页等核心场景的图片清晰度,从视觉体验层面优化用户留存与互动意愿。
ESRGAN-General-x4v3模型在安卓端的部署,采用的是ONNX框架,该方案已有大量公开资料可参考,且取得显著业务成效。但鸿蒙端部署面临核心技术瓶颈:鸿蒙系统不支持ONNX框架,部署端侧AI仅能使用华为自研的CANN(Compute Architecture for Neural Networks)架构,且当前行业内缺乏基于CANN部署端侧AI的公开资料与成熟方案,全程需技术团队自主探索。接下来我会以ESRGAN-General-x4v3为例, 分享从模型转换(NPU亲和性改造)到端侧离线模型部署的全部过程。
2. 部署前期准备
2.1 离线模型转换
CANN Kit当前仅支持Caffe、TensorFlow、ONNX和MindSpore模型转换为离线模型,其他格式的模型需要开发者自行转换为CANN Kit支持的模型格式。模型转换为OM离线模型,移动端AI程序直接读取离线模型进行推理。
2.1.1 下载CANN工具
从鸿蒙开发者官网下载 DDK-tools-5.1.1.1 , 解压使用Tools下的OMG工具,将ONNX、TensorFlow模型转换为OM模型。(OMG工具位于Tools下载的tools/tools_omg下,仅可运行在64位Linux平台上。)
2.1.2 下载ESRGAN-General-x4v3模型文件
从https://aihub.qualcomm.com/compute/models/real_esrgan_general_x4v3 下载模型的onnx文件.
注意: 下载链接中的a8a8的量化模型使用了高通的算子(亲测无法转换), CANN工具无法进行转换, 因此请下载float的量化模型。
下载后有两个文件:
•model.onnx文件 (模型结构): 包含计算图、opset版本、节点配置等,文件较小。
•model.data文件 (权重数据): 包含神经网络参数、权重等,文件较大。
现在我们需要把这种分离文件格式的模型合并成一个文件,后续的操作都使用这个。
合并文件:
请使用JoyCode写个合并脚本即可, 提示词: 请写一个脚本, 把onnx模型文件的.onnx和.data文件合并。
2.1.3 OM模型转换
1. ONNX opset 版本转换
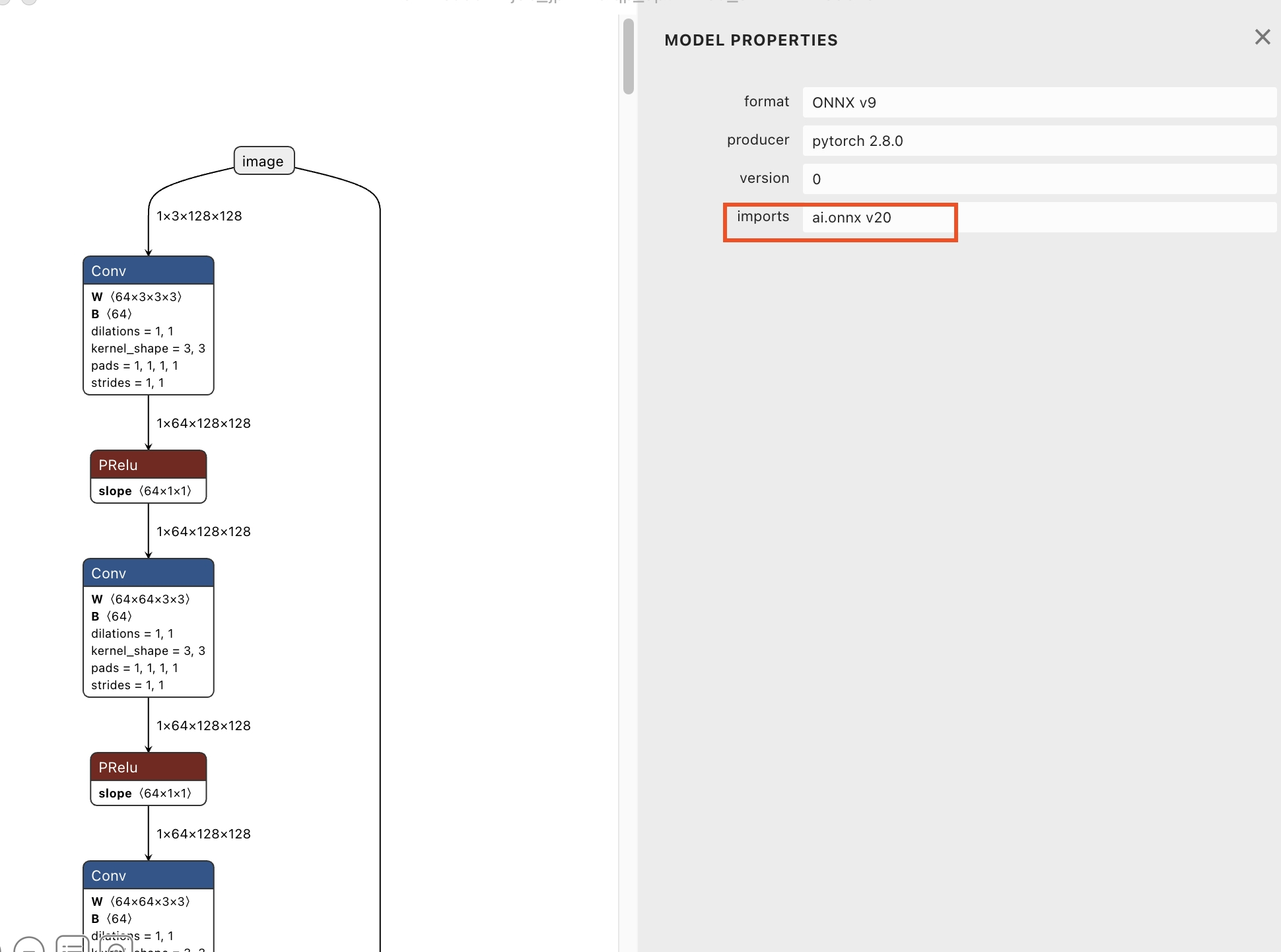
当前使用CANN进行模型转换, 支持ONNX opset版本7~18(最高支持到V1.13.1), 首先需要查看原始的onnx模型的opset版本是否在支持范围, 这里我们使用Netron(点击下载)可视化工具进行查看。
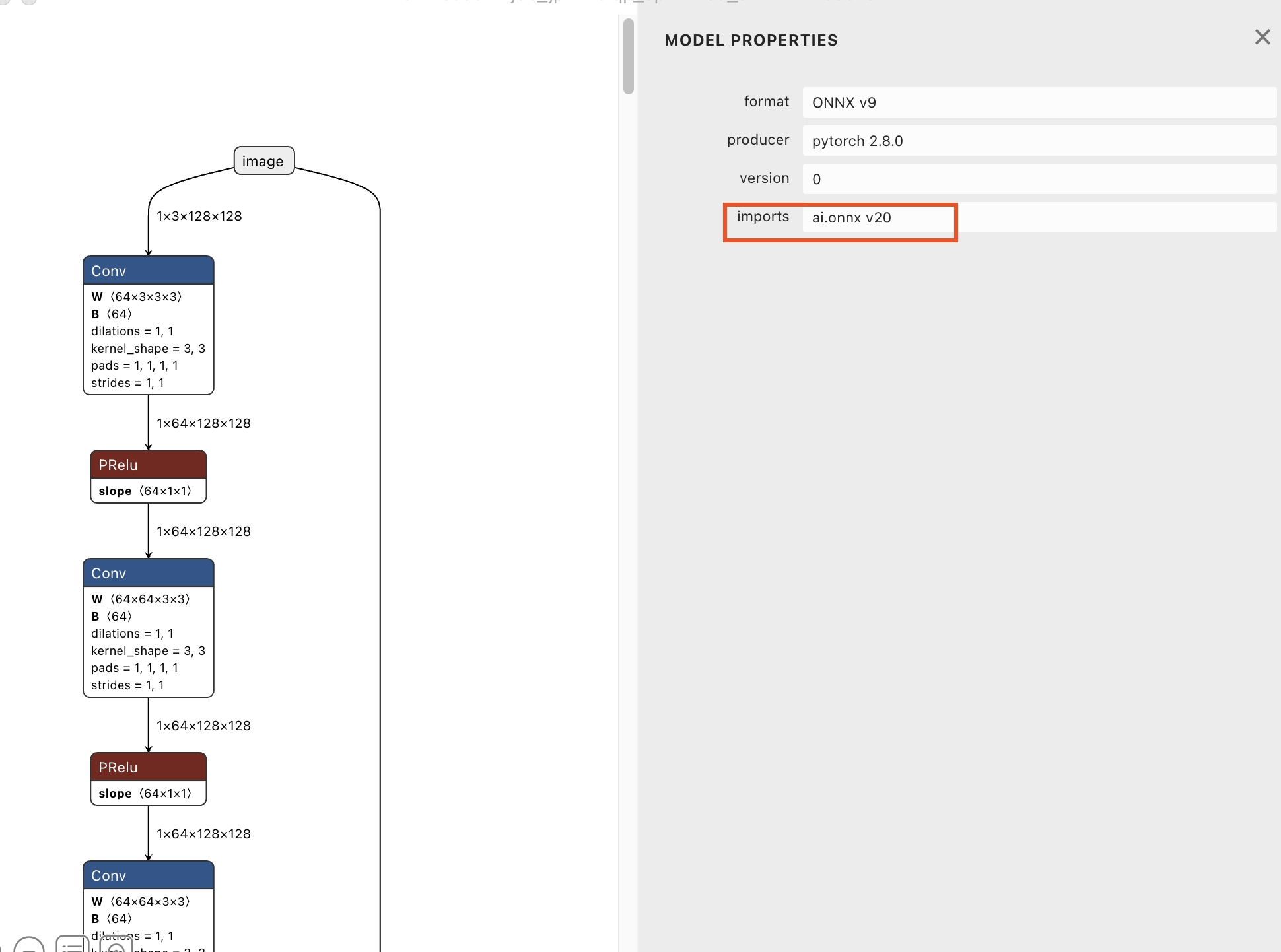
目前该模型使用的opset版本是20, 因此我们需要把该模型的opset版本转成18, 才可以用CANN转换成鸿蒙上可部署的模型。请使用JoyCode写个opset转换脚本即可, 提示词: 请写一个脚本, 把onnx模型文件的opset版本从20转换成18。
2. OM离线模型
命令行中的参数说明请参见OMG参数,转换命令:
./tools/tools_omg/omg --model new_model_opset18.onnx --framework 5 --output ./model
转换完成后, 生成model.om的模型文件, 该模型文件就是鸿蒙上可以正常使用的模型文件
2.2 查看模型的输入/输出张量信息
部署AI模式时, 我们需要确认模型的输入张量和输出张量信息, 请使用JoyCode编写一个脚本, 确定输入输出张量信息, 提示词: 写一个脚本查看onnx模型的输入输出张量信息。

2.2.1 输入张量
BCHW格式, 是深度学习中常见的张量维度排列格式, 在图像处理场景中:
•B (Batch): 批次大小 - 一次处理多少个样本。
•C (Channel): 通道数 - 图像的颜色通道数。
•H (Height): 高度 - 图像的像素高度。
•W (Width): 宽度 - 图像的像素宽度。
由此可以得出结论, 该模型1个批次处理1张宽高为128*128的RGB图片(因为C是3,因此不包含R通道)。
2.2.2 输出张量
该模型1个批次输出1张宽高为512*512的RGB图片。
2.2.3 BCHW和BHWC格式的区别:
超分模型中的BCHW和BHWC是两种不同的张量存储格式,主要区别在于通道维度的位置:
•BCHW格式(Batch-Channel-Height-Width)
◦维度顺序:[批次, 通道, 高度, 宽度]
◦内存布局:通道维度在空间维度之前
◦常用框架:PyTorch、TensorRT等
示例: 形状为 (1, 3, 256, 256) 的RGB图像
内存中的存储顺序: R通道的所有像素 -> G通道的所有像素 -> B通道的所有像素
tensor_bchw = torch.randn(1, 3, 256, 256) 访问第一个像素的RGB值需要跨越不同的内存区域 pixel_0_0_r = tensor_bchw[0, 0, 0, 0] # R通道 pixel_0_0_g = tensor_bchw[0, 1, 0, 0] # G通道 pixel_0_0_b = tensor_bchw[0, 2, 0, 0] # B通道
•BHWC格式(Batch-Height-Width-Channel)
◦维度顺序:[批次, 高度, 宽度, 通道]
◦内存布局:通道维度在最后,像素的所有通道连续存储
◦常用框架:TensorFlow、OpenCV等
示例:形状为 (1, 256, 256, 3) 的RGB图像
内存中的存储顺序:像素(0,0)的RGB -> 像素(0,1)的RGB -> ... -> 像素(0,255)的RGB -> 像素(1,0)的RGB...
tensor_bhwc = tf.random.normal([1, 256, 256, 3]) # 访问第一个像素的RGB值在连续的内存位置 pixel_0_0_rgb = tensor_bhwc[0, 0, 0, :] # [R, G, B]
3. 鸿蒙端部署核心步骤
3.1 创建项目
1.创建DevEco Studio项目,选择“Native C++”模板,点击“Next”。
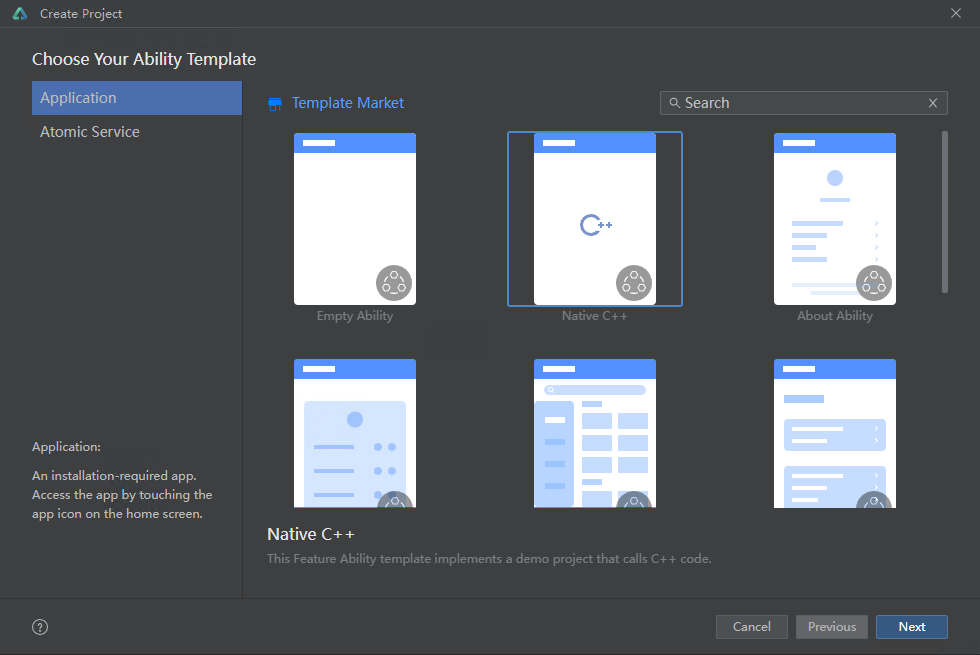
2.按需填写“Project name”、“Save location”和“Module name”,选择“Compile SDK”为“5.1.0(18)”及以上版本,点击“Finish”。

3.2 配置项目NAPI
CANN部署只提供了C++接口, 因此需要使用NAPI, 编译HAP时,NAPI层的so需要编译依赖NDK中的libneural_network_core.so和libhiai_foundation.so。
头文件引用
按需引用NNCore和CANN Kit的头文件。
#include "neural_network_runtime/neural_network_core.h" #include "CANNKit/hiai_options.h"
编写CMakeLists.txt
CMakeLists.txt示例代码如下。
cmake_minimum_required(VERSION 3.5.0)
project(myNpmLib)
set(NATIVERENDER_ROOT_PATH ${CMAKE_CURRENT_SOURCE_DIR})
include_directories(${NATIVERENDER_ROOT_PATH}
${NATIVERENDER_ROOT_PATH}/include)
include_directories(${HMOS_SDK_NATIVE}/sysroot/usr/lib)
FIND_LIBRARY(cann-lib hiai_foundation)
add_library(imagesr SHARED HIAIModelManager.cpp ImageSuperResolution.cpp)
target_link_libraries(imagesr PUBLIC libace_napi.z.so
libhilog_ndk.z.so
librawfile.z.so
${cann-lib}
libneural_network_core.so
)
3.3 集成模型
模型的加载、编译和推理主要是在native层实现,应用层主要作为数据传递和展示作用。模型推理之前需要对输入数据进行预处理以匹配模型的输入,同样对于模型的输出也需要做处理获取自己期望的结果
3.3.1 加载离线模型
为了让App运行时能够读取到模型文件和处理推理结果,需要先把离线模型和模型对应的结果标签文件预置到工程的“entry/src/main/resources/rawfile”目录中。

在App应用创建时加载模型:
1.native层读取模型的buffer。
const char* modelPath = "imagesr.om"; RawFile *rawFile = OH_ResourceManager_OpenRawFile(resourceMgr, modelPath); long modelSize = OH_ResourceManager_GetRawFileSize(rawFile); std::unique_ptr< uint8_t[] > modelData = std::make_unique< uint8_t[] >(modelSize); int res = OH_ResourceManager_ReadRawFile(rawFile, modelData.get(), modelSize);
2.使用模型的buffer, 调用OH_NNCompilation_ConstructWithOfflineModelBuffer创建模型的编译实例
HiAI_Compatibility compibility = HMS_HiAICompatibility_CheckFromBuffer(modelData, modelSize); OH_NNCompilation *compilation = OH_NNCompilation_ConstructWithOfflineModelBuffer(modelData, modelSize);
3.(可选)根据需要调用HMS_HiAIOptions_SetOmOptions接口,打开维测功能(如Profiling)。
const char *out_path = "/data/storage/el2/base/haps/entry/files"; HiAI_OmType omType = HIAI_OM_TYPE_PROFILING; OH_NN_ReturnCode ret = HMS_HiAIOptions_SetOmOptions(compilation, omType, out_path);
4.设置模型的deviceID。
size_t deviceID = 0;
const size_t *allDevicesID = nullptr;
uint32_t deviceCount = 0;
OH_NN_ReturnCode ret = OH_NNDevice_GetAllDevicesID(&allDevicesID, &deviceCount);
for (uint32_t i = 0; i < deviceCount; i++) {
const char *name = nullptr;
ret = OH_NNDevice_GetName(allDevicesID[i], &name);
if (ret != OH_NN_SUCCESS || name == nullptr) {
OH_LOG_ERROR(LOG_APP, "OH_NNDevice_GetName failed");
return deviceID;
}
if (std::string(name) == "HIAI_F") {
deviceID = allDevicesID[i];
break;
}
}
ret = OH_NNCompilation_SetDevice(compilation, deviceID);
5.调用OH_NNCompilation_Build,执行模型编译。
ret = SetModelBuildOptions(compilation); ret = OH_NNCompilation_Build(compilation);
6.调用OH_NNExecutor_Construct,创建模型执行器。
executor_ = OH_NNExecutor_Construct(compilation);
7.调用OH_NNCompilation_Destroy,释放模型编译实例。
3.3.2 准备输入输出Tensor
1.处理模型的输入,模型的输入为1*3*128*128格式(BCHW) Float类型的数据, 需要把RGB 数据转成BCHW格式并进行归一化。
从图片中读取的RGB数据为BHWC,需要转换成模型可以识别的BCHW
/**
* 把bhwc转成bchw
*/
uint8_t *rgbData = static_cast< uint8_t* >(data);
uint8_t *floatData_tmp = new uint8_t[length];
for (int c = 0; c < 3; ++c) {
for (int h = 0; h < 128; ++h) {
for (int w = 0; w < 128; ++w) {
// HWC 索引: h * width * channels + w * channels +c
int hwc_index = h * 128 * 3 + w * 3 + c;
// CHW 索引: C * height * width + h* width + W
int chw_index = c * 128 * 128 + h * 128 + w;
floatData_tmp[chw_index] = rgbData[hwc_index];
}
}
}
//归一化
float *floatData = new float[length];
for (size_t i = 0; i < length; ++i) {
floatData[i] = static_cast< float >(floatData_tmp[i])/ 255.0f;
}
2.创建模型的输入和输出Tensor,并把应用层传递的数据填充到输入的Tensor中
// 准备输入张量
size_t inputCount = 0;
OH_NN_ReturnCode ret = OH_NNExecutor_GetInputCount(executor_, &inputCount);
for (size_t i = 0; i < inputCount; ++i) {
NN_TensorDesc *tensorDesc = OH_NNExecutor_CreateInputTensorDesc(executor_, i);
NN_Tensor *tensor = OH_NNTensor_Create(deviceID_, tensorDesc);
if (tensor != nullptr) {
inputTensors_.push_back(tensor);
}
OH_NNTensorDesc_Destroy(&tensorDesc);
}
ret = SetInputTensorData(inputTensors_, inputData);
// 准备输出张量
size_t outputCount = 0;
ret = OH_NNExecutor_GetOutputCount(executor_, &outputCount);
for (size_t i = 0; i < outputCount; i++) {
NN_TensorDesc *tensorDesc = OH_NNExecutor_CreateOutputTensorDesc(executor_, i);
NN_Tensor *tensor = OH_NNTensor_Create(deviceID_, tensorDesc);
if (tensor != nullptr) {
outputTensors_.push_back(tensor);
}
OH_NNTensorDesc_Destroy(&tensorDesc);
}
if (outputTensors_.size() != outputCount) {
DestroyTensors(inputTensors_);
DestroyTensors(outputTensors_);
OH_LOG_ERROR(LOG_APP, "output size mismatch.");
return OH_NN_FAILED;
}
3.3.3 进行推理
调用OH_NNExecutor_RunSync,完成模型的同步推理。
OH_NN_ReturnCode ret = OH_NNExecutor_RunSync(executor_, inputTensors_.data(), inputTensors_.size(),
outputTensors_.data(), outputTensors_.size());
说明
•如果不更换模型,则首次编译加载完成后可多次推理,即一次编译加载,多次推理。
•所有关于模型的操作, 均无法多线程执行。
3.3.4 获取模型输出并处理数据
1.调用OH_NNTensor_GetDataBuffer,获取输出的Tensor,在输出Tensor中会得到模型的输出数据。
// 获取第一个输出张量 NN_Tensor* tensor = outputTensors_[0]; // 获取张量数据缓冲区 void *tensorData = OH_NNTensor_GetDataBuffer(tensor); // 获取张量大小 size_t size = 0; OH_NN_ReturnCode ret = OH_NNTensor_GetSize(tensor, &size); float *tensorDataOutput = (float*)malloc(size); // 将tensorData的数据一次性复制到tensorDataOutput中 memcpy(tensorDataOutput, tensorData, size);
2.对Tensor输出数据进行相应的处理
把模型输出的BCHW转成BHWC, 并进行反归一化处理
//把模型输出的BCHW转成BHWC
float *outputResult = static_cast< float * >(tensorData);
float *output_tmp = new float[size/sizeof(float)];
for (int h = 0; h < 512; ++h) {
for (int w = 0; w < 512; ++w) {
for (int c = 0; c < 3; ++c) {
output_tmp[h * 512 * 3 + w* 3 + c] = outputResult[c * 512 * 512 + h * 512 + w];
}
}
}
std::vector< float > output(size / sizeof(float), 0.0);
for (size_t i = 0; i < size / sizeof(float); ++i) {
output[i] = output_tmp[i];
}
delete [] output_tmp;
// 计算总的数据大小
size_t totalSize = output.size();
// 分配结果数据内存
std::unique_ptr< uint8_t[] > result_data = std::make_unique< uint8_t[] >(totalSize);
// 将float数据转换为uint8_t (反归一化)
size_t index = 0;
for (float value : result) {
// 将float值转换为uint8_t (0-255范围)
float scaledValue = value * 255.0f;
scaledValue = std::max(0.0f, std::min(255.0f, scaledValue));
result_data[index++] = static_cast< uint8_t >(scaledValue);
}
result_data 就是最终的超分数据,可以正常显示
4. 总结与技术展望
京东金融App在鸿蒙端部署Real-ESRGAN-General-x4v3超分辨率模型的完整实践过程,成功解决了ONNX模型到OM离线模型转换、BCHW与BHWC张量格式处理、以及基于CANN Kit和NAPI的完整部署链路等关键技术难题。
展望端智能的未来发展,随着芯片算力的指数级增长、模型压缩技术的突破性进展以及边缘计算架构的日趋成熟,端侧设备将从单纯的数据采集终端演进为具备强大推理能力的智能计算节点,通过实现多模态AI融合、实时个性化学习、隐私保护计算和跨设备协同等核心能力,将大语言模型、计算机视觉、语音识别等AI技术深度集成到移动设备中,构建起无需联网即可提供智能服务的自主计算生态,推动人机交互从被动响应向主动感知、预测和服务的范式转变,最终开启真正意义上的普惠人工智能时代。
-
AI
+关注
关注
91文章
41101浏览量
302579 -
模型
+关注
关注
1文章
3818浏览量
52265 -
金融
+关注
关注
3文章
536浏览量
16711
发布评论请先 登录
边缘AI应用越来越普遍,AI模型在边缘端如何部署?

添越智创基于 RK3588 开发板部署测试 DeepSeek 模型全攻略
首创开源架构,天玑AI开发套件让端侧AI模型接入得心应手
AI端侧部署开发(SC171开发套件V3)
AI端侧部署开发(SC171开发套件V3)2026版
AI端侧部署开发(SC171开发套件V2-FAS)
介绍在STM32cubeIDE上部署AI模型的系列教程
真正的金融科技才刚刚开始 京东金融改名京东数科
三行代码完成AI模型的部署!
AI大模型端侧部署正当时:移远端侧AI大模型解决方案,激活场景智能新范式

AI大模型端侧部署正当时:移远端侧AI大模型解决方案,激活场景智能新范式

开源鸿蒙开发者大会2025·AI分论坛圆满闭幕,探索开源鸿蒙AI无限可能

【HarmonyOS 5】金融应用开发鸿蒙组件实践

基于Vulkan的端侧AI运算
京东金融鸿蒙端部署AI超分模型实践(纯干货)



评论