 基于Vulkan的端侧AI运算
基于Vulkan的端侧AI运算

【拆·应用】是为开源鸿蒙应用开发者打造的技术分享平台,是汇聚开发者的技术洞见与实践经验、提供开发心得与创新成果的展示窗口。诚邀您踊跃发声,期待您的真知灼见与技术火花!
引言
本期内容由AI Model SIG提供,介绍了在开源鸿蒙中,利用图形接口Vulkan的计算着色器能力,在端侧部署大模型的的整体思路和实践分享。
开源鸿蒙是由开放原子开源基金会孵化及运营的开源项目,目标是面向全场景、全连接、全智能时代,搭建一个智能终端设备操作系统的框架和平台,促进万物互联产业的繁荣发展。在人工智能时代下,与其它成熟的操作系统相比,开源鸿蒙部署AI LLM模型的能力欠缺。为了补齐开源鸿蒙在端侧部署大模型的能力,笔者将分享如何在端侧打通大模型部署的整体思路和实践。
软硬件选型
在硬件上选取国产CPU飞腾D2000,显卡选用AMD GPU。目前能够在OpenHarmony5.0.0 Release上点亮AMD GPU,包括RX 550、RX 580和RX 7900 XTX。
其次是推理框架的选择,笔者选取了llama.cpp这个开源的推理框架,仓库地址为:github.com/ggml-org/llama.cpp。目前很火的ollama,其也是选用了llama.cpp作为推理后端。llama.cpp是一个专注于在边缘设备、个人PC上进行llm部署的高性能推理框架。其相比于vllm等主流llm推理框架来说,有以下明显的优点:
纯 C++/C 实现,在Windows、mac、Linux等多种系统下编译都非常简单。
丰富的后端支持:如图所示,支持x86、arm、Nidia_GPU、AMD_GPU、Vulkan甚至华为昇腾NPU_CANN。
支持CPU AVX指令集进行矢量计算加速、CPU多核并行计算、CPU+GPU混合计算
支持低精度量化:1.5bit、2 bit、3 bit、4 bit、5 bit、6 bit和 8 bit整数量化,可加快推理速度并减少内存使用。
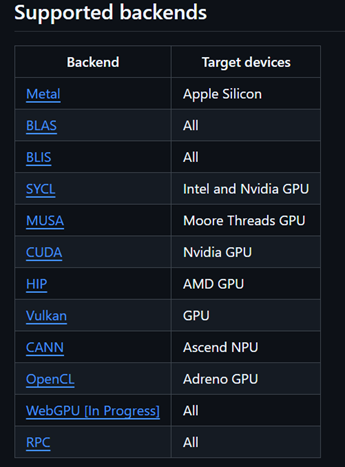
llama.cpp支持的后端及其硬件
在上图中,llama.cpp支持Vulkan后端。笔者通过查阅相关资料和阅读llama.cpp关于Vulkan的相关代码,发现其是利用图形接口Vulkan的计算着色器(Compute Shader)的能力来运行大模型的。计算着色器(Compute Shader) 是GPU上用于通用计算(GPGPU) 的特殊程序,与传统图形渲染管线解耦,可直接操作GPU并行处理非图形任务(如AI推理、物理模拟、数据处理)等。下表是计算着色器的特点:
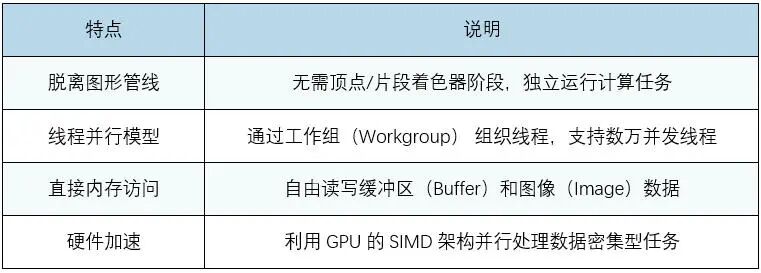
综合多因素的考量,在软硬件上最终选用飞腾D2000 + AMD GPU + OpenHarmony 5.0.0 Release的组合,利用图形接口Vulkan的计算着色器能力,在终端设备上高效运行大模型。
在开源鸿蒙部署大模型的难点
在第一部分提到将利用图形接口Vulkan的计算着色器的能力,在端侧高效运行大模型。在开源鸿蒙社区有个Vulkan的demo样例,仓库地址为:https://gitee.com/openharmony/applications_app_samples/tree/master/code/BasicFeature/Native/NdkVulkan,通过笔者的实践,目前在HarmonyOS能跑通该样例,但是在开源鸿蒙上尚不能跑通该样例。通过阅读该例子的文档说明,如下图,发现核心原因是缺少AMD GPU的Vulkan用户态驱动库libvulkan_radeon.so以及Vulkan的sdk。因此核心难点是要能将Vulkan的计算着色器在开源鸿蒙上正常跑起来。
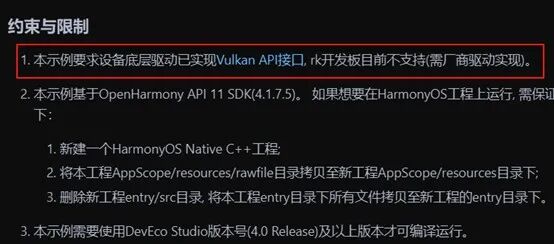
NdkVulkan例子
整体思路
为了能够利用图形接口Vulkan的计算着色器的能力跑大模型。笔者总结了以下四个的关键步骤:
在开源鸿蒙上正常点亮AMD GPU。
交叉编译出AMD的Vulkan用户态驱动。
交叉编译出Vulkan sdk。
移植llama.cpp到OpenHarmony上。
实践要点
点亮AMDGPU
1.确保AMD GPU 内核态是正常的选用的内核版本为linux 6.6.22,需要将内核的以下选项打开。

系统正常启动后,采用modetest工具进行测试,在测试前需要关闭render_service、composer_host和allocator_host这三个进程,具体的命令如下:

在hdc shell中运行以下命令:
如果能够在显示屏上看到彩色的条纹,如下图,说明AMD GPU的内核态是正常的。
modetest测试结果
2.确保AMD GPU的用户态是正常的
首先通过mesa3d交叉编译出AMD GPU的用户态驱动,主要为libEGL.so.1.0.0、libgallium_dri.so、libgbm.so.1.0.0、libglapi.so.0.0.0、libGLESv1_CM.so.1.1.0和libGLESv2.so.2.0.0这个5个动态库。
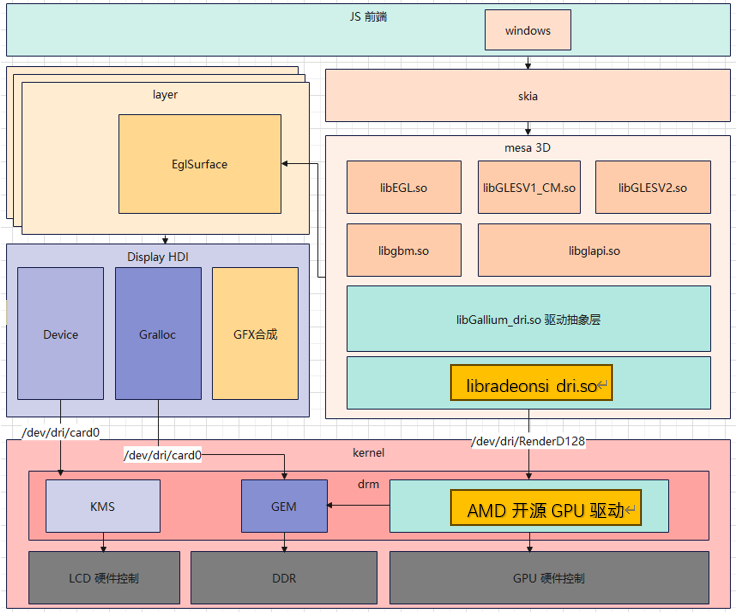
大家可以参考laval社区的《开源鸿蒙开源GPU库Mesa3D适配说明》这篇文章,了解GPU的适配过程,链接地址为:https://laval.csdn.net/64804567ade290484cb2ed06.html
这篇文章主要讲的是mali gpu的mesa3d点亮过程。由于跑Vulkan的计算着色器可以不用到显示的功能,因此在这里具体的适配过程就不展开,感兴趣的读者可在AI Model SIG的ohos_vulkan仓库获取相关的AMD GPU 的mesa用户态驱动的库,仓库地址为:https://gitcode.com/ai_model_sig/ohos_vulkan 成功适配后,可以在显示屏正常看到开源鸿蒙的桌面。
Vulkan用户态驱动
这一步的核心是能够获得libvulkan_radeon.so这个动态库。在mesa3d中有Vulkan用户态驱动的实现,因此通过编译mesa3d这个开源项目编译出libvulkan_radeon.so这个Vulkan用户态驱动库。
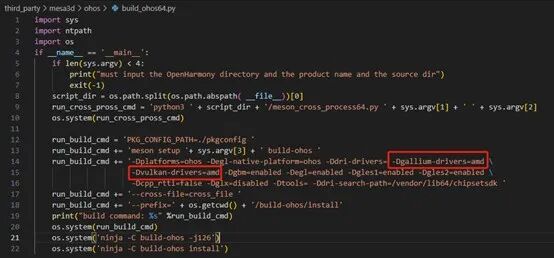
在build_ohos.py文件中需要指定 -Dgallium-drivers=amd 和 -Dvulkan-drivers=amd这两个参数,如下图:
通过以下指令:
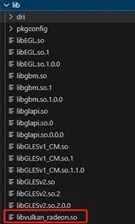
便可以编译出libvulkan_radeon.so这个动态库,如下图所示
Vulkan sdk
Vulkan sdk的构成主要包含以下11个项目:
https://github.com/KhronosGroup/glslang.git
https://github.com/KhronosGroup/SPIRV-Headers.git
https://github.com/KhronosGroup/SPIRV-Tools.git
https://github.com/zeux/volk.git
https://github.com/KhronosGroup/Vulkan-ExtensionLayer.git
https://github.com/KhronosGroup/Vulkan-Headers.git
https://github.com/KhronosGroup/Vulkan-Loader.git
https://github.com/KhronosGroup/Vulkan-Tools.git
https://github.com/KhronosGroup/Vulkan-Utility-Libraries.git
https://github.com/KhronosGroup/Vulkan-ValidationLayers.git
在这里需要通过交叉编译的方式获得aarch64版本的产物,如下图所示。
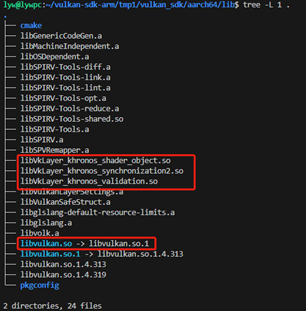
Vulkan sdk的编译比较复杂,这里不进行展开,读者可以通过这个链接下载:
https://gitcode.com/ai_model_sig/ohos_vulkan/pull/1
下面介绍一下如何将Vulkan sdk部署在开源鸿蒙上:
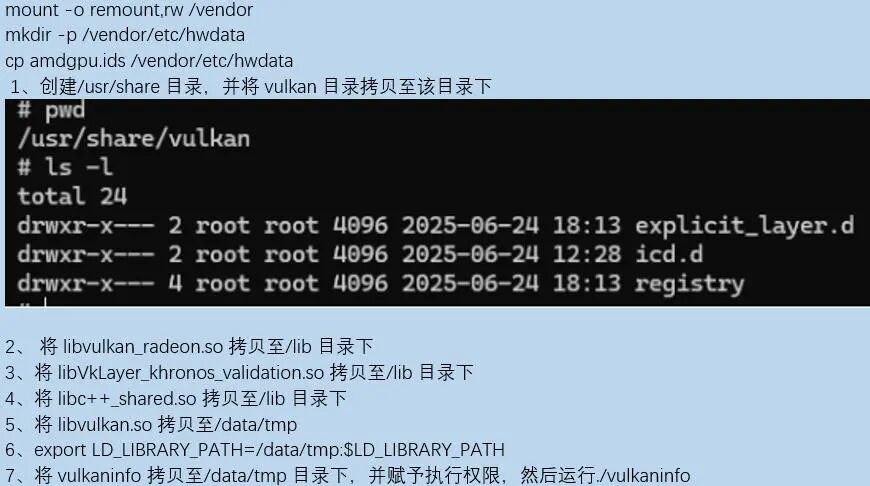
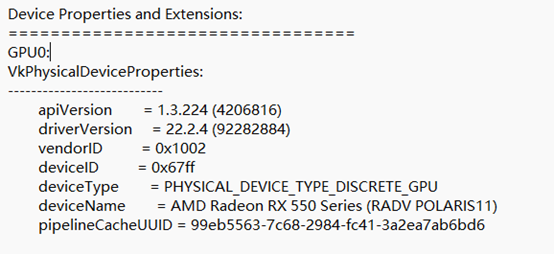
通过运行vulkaninfo可以获取vulkan的相关信息,也能获取我们所用GPU的型号。

目前我们能将Vulkan在开源鸿蒙上正式跑起来了,接下来需要写一个简单的例子来验证Vulkan的计算着色器是否正常。笔者提供了一个简单的利用计算着色器来进行矩阵并行计算,大家可以通过laval社区的这篇文章详细了解一下,文章链接:
https://laval.csdn.net/685bdb3d965a29319f2773cb.html
该例子的核心就是矩阵A和矩阵B相乘的到矩阵C,矩阵C的每个元素需要做256次乘法和255次加法。
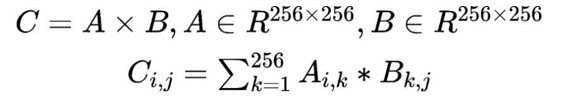
下面是例子的具体内容:
整体流程:初始化Vulkan → 创建矩阵缓冲区 → 构建计算管线 → 提交计算任务 → 同步获取结果 → 验证输出 → 资源释放;
编写计算着色器,如下图;
并行策略:每个线程计算输出矩阵的一个元素;
工作组配置:每个工作组包含16x16=256个并行线程;
执行粒度:与主程序中的vkCmdDispatch(MATRIX_SIZE/16, MATRIX_SIZE/16, 1)配合,共调度 (256/16)^2 = 256个工作组覆盖整个矩阵;
线程总数:256 * 256 = 65536 个并行线程。

计算着色器
假设矩阵A的元素全为1,矩阵B的元素全为2,那么矩阵C的计算结果应该全为512。如下图可见矩阵C的计算结果正确,总耗时大概在5毫秒左右。通过对比矩阵C的结果和耗时,初步可以确认Vulkan的计算着色器能在开源鸿蒙上正常运行。
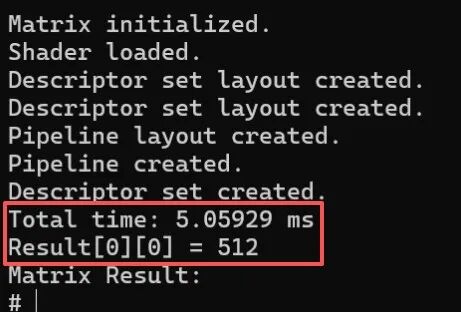
矩阵C的计算结果
推理框架 llama.cpp
利用前一步得到的Vulkan sdk,接下来需要交叉编译出llama.cpp。下面是交叉编译的命令。

最终我们将编译的产物拷贝至开源鸿蒙设备上,然后运行。可以看到llama.cpp能够正确识别我们的AMD GPU并将模型的权重加载至显卡上。

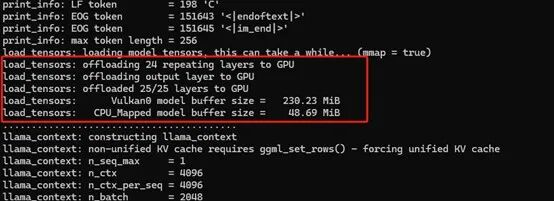
总结
本文主要分享了如何在端侧打通大模型部署的整体思路和实践,从而补齐开源鸿蒙在端侧部署大模型的能力。目前能够利用图形接口Vulkan的计算着色器的能力,能够在端侧的AMD的消费级显卡AMD 7900XTX上部署类似DeepSeek 32B这类的大模型,从而打造了AI能力的算力底座,为AI应用提供支撑。
-
cpu
+关注
关注
68文章
11327浏览量
225903 -
AI
+关注
关注
91文章
41115浏览量
302607 -
开源
+关注
关注
3文章
4346浏览量
46443 -
大模型
+关注
关注
2文章
3771浏览量
5273
原文标题:拆·应用丨第6期:基于Vulkan的端侧AI运算
文章出处:【微信号:gh_e4f28cfa3159,微信公众号:OpenAtom OpenHarmony】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

端侧AI浪潮已来!炬芯科技发布新一代端侧AI音频芯片,能效比和AI算力大幅度提升

首创开源架构,天玑AI开发套件让端侧AI模型接入得心应手
荣耀引领端侧AI新时代
广和通端侧AI解决方案驱动性能密集型场景商用型场景商用



中信建投建议关注端侧AI模组机会
广和通Fibocom AI Stack:加速端侧AI部署新纪元
AI大模型端侧部署正当时:移远端侧AI大模型解决方案,激活场景智能新范式

AI大模型端侧部署正当时:移远端侧AI大模型解决方案,激活场景智能新范式

炬芯科技探索端侧AI技术与应用
借助谷歌LiteRT构建下一代高性能端侧AI




评论