 借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率

随着模型规模迈入百亿、千亿甚至万亿参数级别,如何在有限显存中“塞下”训练任务,对研发和运维团队都是巨大挑战。NVIDIA Megatron-Core作为流行的大模型训练框架,提供了灵活高效的并行化策略;理解这些策略对显存的影响,才能更好地规划训练超参数,在不 OOM (out of memory) 的情况下尽可能提升硬件使用效率。
显存的组成与衡量方法:通过 torch 的显存可视化工具捕捉一个典型的模型训练中的显存占用。静态显存主要组成部分包括模型参数、梯度和优化器的所占用的空间,及一些其他的系统开销。设定 R 为参数重复次数,则对 bf16 训练来说每个参数占用的字节数为 6+12/R。对于Mixture of Experts (MoE)模型来说,由于 Megatron 支持 parallel folding,模型的模型会分为稠密部分和 MoE 部分,其中稠密部分的 R 为 DP*CP,MoE 部分的 R 为 EDP=n_GPU/PP/EP/ETP。
动态显存则是模型前向传播过程中暂存的中间结果,用于反向传播时计算梯度,通常被称为激活 (Activation),绝大部分为 bf16 数据类型。
对显存影响的关键超参数:Megatron-Core 支持以下并行、重算维度,组合后可覆盖当下主流大模型训练需求。
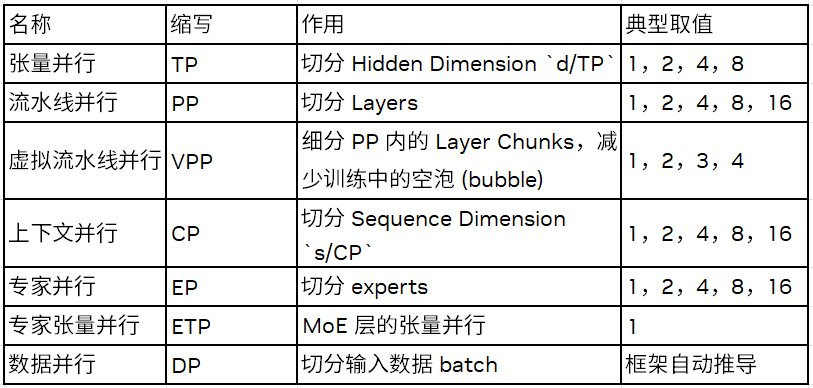
约束关系:`n_GPU / PP = TP×CP×DP = EP×ETP×EDP`,其中 `EDP` 为专家数据并行度。
除了完全不重算的情况之外,为了降低动态显存,Megatron-Core 0.14 提供
完全重算 (full) 和细粒度重算 (selective) 这两档重算。
显存估计器的设计:当前 Megatron 基于 torch 实现,所有模块均派生自 torch.nn.Module,构成训练 GPT 类模型的模块。我们通过实现一个基类 MemEstimator 并基于此基类派生出所有需要的模块类,根据每个模块的显存占用特点分别计算其中的参数量和激活量。然后复用 Megatron 中本身构建模型的代码,实现一个 Megatron 模拟器,并可以展示出个层次的模块数据量。
关键结论:选取 Qwen3 235B 和 DeepSeek v3 两个时下流行的大模型,使用流行的配置开启训练,并对比显存估计的结果与真实的显存占用。两个模型的实际峰值与估计峰值相差均小于 2GB。
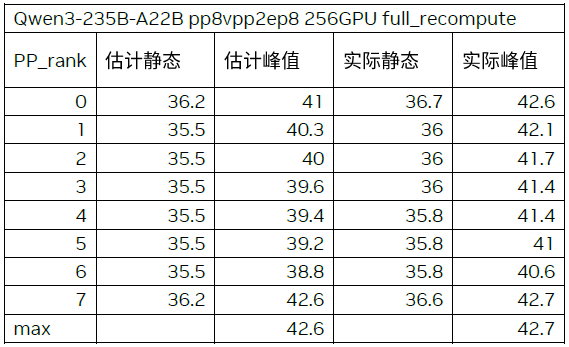
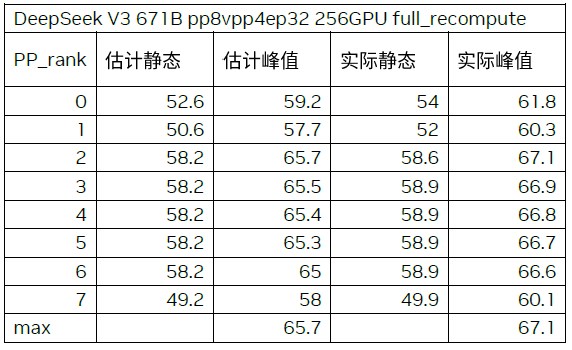
通过对动态显存分析,只有 TP 和 CP 能降低激活量,EP 和 ETP 只会改变集群内激活值的分布,无法降低激活量,PP 和 VPP 由于 1f1b 的流水线预热机制,无法有效降低峰值激活量。对每一部分激活量,可以通过卸载到 CPU 或者重算的方式来降低显存。Megatron-Core 0.13 当前对卸载的支持还在开发中,但重算已经支持。
Megatron-Core 0.13 现已支持通过 CPU 分担 optimizer 的显存占用,并可以通过超参数设置卸载到 CPU 的比例,每个参数的 6 字节 (bf16 参数,fp32 梯度) 无法卸载,其余可以卸载。
用例分析:用户目标在 32 张 80GB 显存的 GPU 上实现 Qwen3-30B-A3B 的强化学习训练,序列长度是 10k,用户使用显存估计器对并行配置进行摸底。
Megatron 开发者可以通过显存分析工具的 breakdown 视角,详细察看每个模块的激活量,通过权衡激活量和计算量寻找性价比高(激活量 / 计算量)的模块的激活为其开发进行重算或卸载功能。
-
cpu
+关注
关注
68文章
11382浏览量
226573 -
大模型
+关注
关注
2文章
3884浏览量
5314
原文标题:探索在大模型训练中使用 Megatron-Core 训练框架提高显存使用效率
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
零基础手写大模型资料2026
HM博学谷狂野AI大模型第四期
AWQ/GPTQ量化模型加载与显存优化实战
大模型服务为什么总是爆显存
NVIDIA推出代理式AI蓝图与电信推理模型
在Python中借助NVIDIA CUDA Tile简化GPU编程

利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
在Ubuntu20.04系统中训练神经网络模型的一些经验
NVIDIA开源Audio2Face模型及SDK

NVIDIA 利用全新开源模型与仿真库加速机器人研发进程

NVIDIA Isaac Lab多GPU多节点训练指南
借助NVIDIA Cosmos模型提升机器人训练效率




评论