 南大团队实现迄今最高计算精度的模拟存算一体芯片
南大团队实现迄今最高计算精度的模拟存算一体芯片

电子发烧友网综合报道在当今计算技术快速发展的背景下,模拟计算作为一种独特的计算范式,正逐渐展现出其独特的魅力与潜力。与传统的数字计算不同,模拟计算并非依赖于离散的数字信号进行运算,而是直接利用物理定律,通过连续变化的物理量(如电压、电流等)来执行计算任务。这种计算方式在能效和速度方面具有显著优势,因为它省去了数字计算中复杂的数模转换过程,能够更直接、更高效地处理信息。近年来,随着人工智能(AI)硬件领域的蓬勃发展,模拟计算因其高效能的特点,受到了广泛关注与研究。
而在模拟计算的广阔领域中,模拟存内计算(AnalogIn-MemoryComputing,AIMC)作为一种新兴技术,正成为研究的热点。模拟存内计算的核心思想是将计算过程与数据存储紧密结合,直接在存储单元内部执行计算操作,从而避免了数据在存储器与计算单元之间的频繁搬运,极大地提高了计算效率并降低了能耗。这种计算模式特别适用于需要处理大量数据的场景,如神经网络推理、图像处理等,为AI硬件的发展提供了新的思路和方向。然而,尽管模拟计算和模拟存内计算具有诸多优势,但当前仍普遍面临计算精度低、计算稳定性不足的挑战。这主要由于现有模拟硬件的计算方案高度依赖器件的内在物理参数(如电阻值),这些物理参数在每次编程时往往存在较大随机偏差,且极易受到环境因素(如温度)的影响。上述特性使得现有模拟计算精度难以提高,成为制约其走向应用的关键瓶颈。
近日,南京大学物理学院缪峰教授和梁世军教授团队针对这一难题,提出了一种高精度模拟计算方案,为模拟存内计算领域带来了新的突破。该方案将模拟计算权重的实现方式从不稳定、易受环境干扰的物理参数(例如器件电阻)转向高度稳定的器件几何尺寸比,突破了限制模拟计算精度的瓶颈。
基于这一创新思想,团队设计并验证了一款基于标准CMOS工艺的模拟存内计算芯片。结合权值重映射技术,该芯片在并行向量矩阵乘法运算中实现了仅0.101%的均方根误差,创下了模拟向量-矩阵乘法运算精度的最高纪录。值得强调的是,该芯片在-78.5°C和180°C的极端环境下依然能稳定运行,矩阵计算的均方根误差分别维持在0.155%和0.130%的水平,展现出在极端环境下保持计算精度的优秀能力。不仅如此,该方案还可应用于各种二值存储介质,因而具备广泛的应用潜力。
本研究的核心思想是将模拟计算权重的实现方式从器件参数转向器件的几何比例(图1A),利用器件几何比例在制备完成后具备极高稳定性的特点,实现高精度计算(图1B)。基于这一思想,研究团队通过电路拓扑设计,结合存储单元和开关器件,构建了可编程的计算单元(图1C)。该单元通过两级依赖尺寸比例的电流拷贝电路实现输入电流与8比特权重的乘法运算:第一级的几何比例由8位存储器控制;第二级为固定比例,为不同列上的第一级输出电流赋予对应的二进制权重。两级共同作用,决定计算单元的整体等效比例,从而实现权重可编程的模拟乘法运算。通过阵列化排布这些计算单元,研究团队设计出了一款高精度电流域向量-矩阵乘法芯片(图1D)。
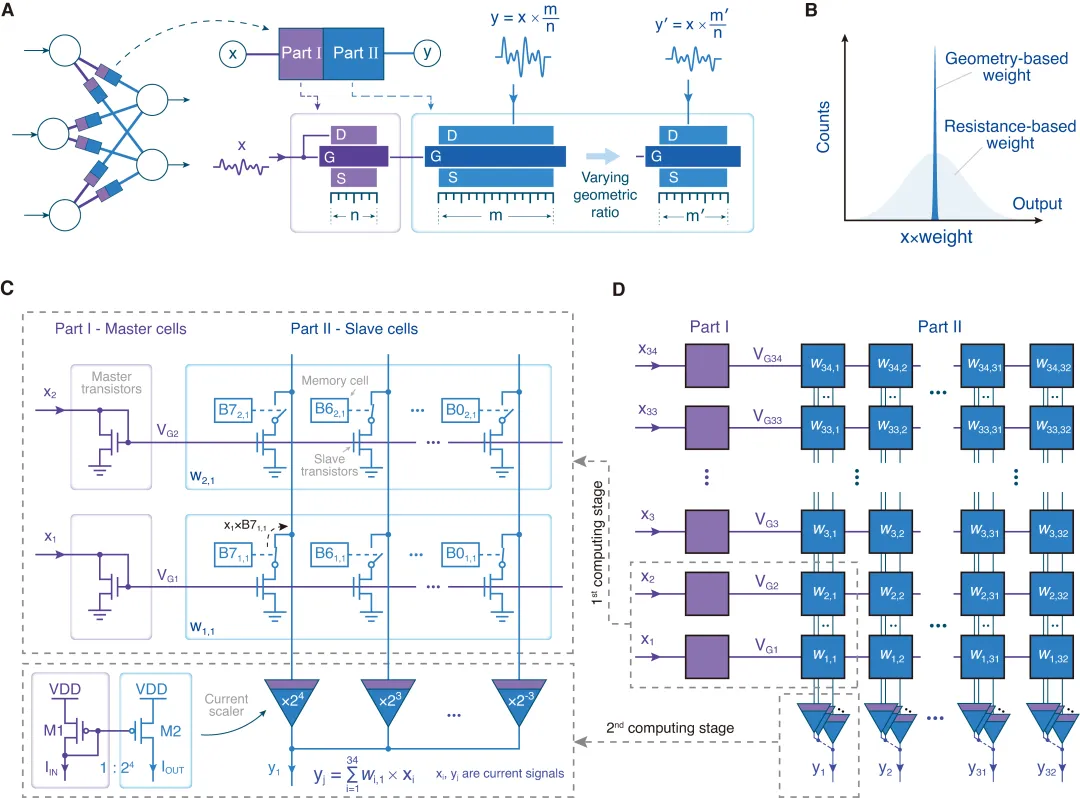
图1:高精度模拟计算方案与电路结构。(A)概念示意图。本方案利用器件的物理尺寸决定模拟信号的运算关系。(B)实现效果示意图。利用器件物理尺寸的稳定性,本方案可实现超越传统方案的计算精度。(C)计算单元原理图。通过两级依赖尺寸比例的电流拷贝电路设计,结合存储单元和开关器件,构建了等效尺寸比例可编程的计算单元,实现输入电流与8比特权重的模拟乘法运算。(D)计算阵列原理图。通过阵列化排布计算单元,设计高精度电流域向量-矩阵乘法芯片。
随后,研究团队基于180nmCMOS工艺对该方案进行了流片验证。芯片照片与测试电路如图2A所示。研究团队通过执行多轮随机向量-矩阵乘法充分测试了该芯片的计算精度。测试使用的矩阵规模为64×32(图2B),总共由4块芯片组成。同时,研究团队提出了一种权值重映射方法(图2C),可以最大程度利用器件尺寸比例的稳定性,从而进一步提高芯片的计算精度。在1500次随机向量-矩阵乘法实验中,测量到的芯片输出结果与理想值几乎完全一致(图2D),体现出极高的计算精度。进一步的统计结果显示,芯片计算相对误差的均方根仅为0.101%(图2E),刷新了模拟计算领域的最高精度纪录。与其他模拟计算方案相比,本芯片的计算精度显著提高(图2F)。

图2:高精度模拟向量-矩阵乘法测试。(A)芯片和测试电路照片。(B)模拟向量-矩阵乘法精度测试电路原理图。(C)权值重映射方法示意图。该方法能进一步提高芯片计算精度。(D)1500组随机向量-矩阵乘法结果。理想输出与实际输出几乎重合。(E)归一化计算误差的分布图,统计得其均方根仅为0.101%。(F)本芯片与其他先进模拟计算方案的精度对比。
该芯片具有的超高模拟向量-矩阵乘法精度,使得其在实际应用中表现优异。研究团队首先测试了芯片在神经网络推理任务中的应用效果:利用团队研发的高精度模拟存算芯片执行图3A所示神经网络中的全部卷积层和全连接层运算时,在MNIST测试集上识别准确率达到97.97%(图3C),这与64位浮点精度下的软件识别率相近(-0.49%),显著优于传统模拟计算硬件(+3.82%)。进一步,团队测试了该芯片在科学计算应用中的表现。研究团队利用高精度模拟存算芯片求解纳维–斯托克斯方程,以模拟流体流动行为。经实验测试,芯片计算出的流体运动结果(图3D)与64位浮点精度的结果高度一致(图3E),而传统低精度模拟计算硬件在执行相同任务时则无法得到正确的结果(图3F)。

图3:高精度模拟计算芯片的应用表现。(A)神经网络结构与数据集。(B)在MNIST测试集上识别结果的混淆矩阵,识别率达到97.97%。(C)准确率对比。高精度模拟计算芯片测试结果与64位浮点精度下的软件识别率相近(-0.49%),显著优于传统模拟计算硬件(+3.82%)。(D)高精度模拟计算芯片求解纳维–斯托克斯方程得到的流体行为预测结果。(E)64位浮点精度下的软件计算结果,本芯片结果与其高度一致。(F)低精度模拟计算硬件的结果无法准确反映流体行为。
研究团队不仅测试了该模拟存算芯片的超高计算精度,还验证了这一芯片在极端环境中有效保持计算精度的鲁棒性。即使在外界环境变化条件下,器件的几何比例依然能保持恒定,这使得本芯片在极端环境中仍然能保持较高的计算精度。研究团队在-78.5℃和180℃下利用该模拟存算芯片执行模拟向量-矩阵乘法运算测试,测得相对误差的均方根分别仅为0.155%和0.130%(图4A、B)。在更宽温区(-173.15℃至286.85℃)的测试中,芯片核心单元输出电流相较于常温条件的最大偏差仅为1.47%(图4C-F)。此外,研究团队也在强磁场环境(最高10T)中对芯片输出电流进行了测量。结果显示,芯片核心单元的输出电流相较于无磁场条件的变化不超过0.21%(图4G-J)。上述结果充分说明了团队所提出的高精度模拟计算方案在极端环境下的可靠性。

图4:高精度模拟计算芯片的鲁棒性测试。(A)低温下(-78.5℃)芯片的向量-矩阵乘法精度测试结果。测得芯片输出的相对误差均方根为0.155%。(B)高温下(180℃)芯片的向量-矩阵乘法精度测试结果。测得芯片输出的相对误差均方根为0.130%。(C)将芯片核心单元置于更宽温区(-173.15℃至286.85℃)进行测试的示意图。(D)-(F)宽温区下的输出电流测量结果。相对于常温条件,输出电流偏差不超过1.47%。(G)将芯片核心单元置于强磁场(最高10T)下进行精度测试的示意图。(H)-(J)强磁场下的输出电流测量结果。相对于零磁场条件,输出电流偏差不超过0.21%。
相关研究成果以“Ultrahigh-precisionanalogcomputingusingmemory-switchinggeometricratiooftransistors”(基于器件尺寸比例稳定性的超高精度模拟计算方案)为题,于2025年9月12日发表在学术期刊ScienceAdvances上。
-
模拟
+关注
关注
7文章
1447浏览量
85507 -
存算一体
+关注
关注
1文章
121浏览量
5209
发布评论请先 登录
AI存算一体,这家ReRAM新型存储受关注

知存科技王绍迪:AI可穿戴需求爆发,存算一体成主流AI芯片架构

载誉而归 | 苹芯科技斩获AABI火炬技术转移奖,存算一体技术探索跨境创新合作

【设计周报】电子发烧友每周内容精选第32期

存算一体AI芯片公司九天睿芯完成超亿元B轮融资
后摩尔定律时代,3D-CIM+RISC-V打造国产存算一体新范式

知存科技荣获2025半导体市场创新表现奖
在TR组件优化与存算一体架构中构建技术话语权

存算一体技术加持!后摩智能 160TOPS 端边大模型AI芯片正式发布

2025端侧AI芯片爆发:存算一体、非Transformer架构谁主浮沉?边缘计算如何选型?
缓解高性能存算一体芯片IR-drop问题的软硬件协同设计
国际首创新突破!中国团队以存算一体排序架构攻克智能硬件加速难题

Matlab与MWORKS软件计算精度对比
苹芯科技 N300 存算一体 NPU,开启端侧 AI 新征程



评论