 摩尔线程“AI工厂”:五大核心技术支撑,打造大模型训练超级工厂
摩尔线程“AI工厂”:五大核心技术支撑,打造大模型训练超级工厂

2025年7月25日,上海——在世界人工智能大会(WAIC 2025)开幕前夕,摩尔线程以“算力进化,精度革命”为主题举办技术分享会,并创新性提出“AI工厂”理念。摩尔线程创始人兼CEO张建中在主题演讲中表示,为应对生成式AI爆发式增长下的大模型训练效率瓶颈,摩尔线程将通过系统级工程创新,构建新一代AI训练基础设施,致力于为AGI时代打造生产先进模型的“超级工厂”。

“AI工厂”:锻造先进模型的“超级工厂”
人工智能前沿模型的竞争正推动着AI智能水平的迅猛提升,全球科技巨头正以惊人的速度迭代模型。从GPT系列、Gemini到DeepSeek、QWen的快速更新,模型训练迭代时间已缩短至不足3个月,这种高频迭代不仅体现在大型语言模型(LLM)上,还同步扩展至多模态模型、语音模型、世界模型等前沿模型领域。这些模型在性能、效率和应用场景上实现的指数级突破,不仅推动了AI从专用领域向通用智能的跨越,其快速迭代的特性更对新一代高性能人工智能计算基础设施提出了迫切需求。
摩尔线程提出的“AI工厂”,如同芯片晶圆厂的制程升级,是一个系统性、全方位的变革,需要实现从底层芯片架构创新、到集群整体架构的优化,再到软件算法调优和资源调度系统的全面升级。这种全方位的基础设施变革,将推动AI训练从千卡级向万卡级乃至十万卡级规模演进,以系统级工程实现生产力和创新效率的飞跃。

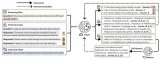
这座“AI工厂”的智能“产能”,由五大核心要素共同决定,其效率公式可概括为:AI工厂生产效率 = 加速计算通用性 × 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性
摩尔线程以全功能GPU通用算力为基石,通过先进架构、芯片算力、单节点效率、集群效率优化与可靠性等协同跃升的深度技术创新,旨在将全功能GPU加速计算平台的强大潜能,转化为工程级的训练效率与可靠性保障。
五大核心技术:系统性提升AI训练效率
摩尔线程通过软硬深度协同的系统级创新,从五大核心技术构建“AI工厂”,致力于推动大模型训练效率实现质的飞跃。
技术一:全功能GPU,实现加速计算通用性
在AI基础设施建设中,计算功能的完备性与精度完整性是支撑多元场景的核心基石。摩尔线程以自主研发的全功能GPU为核心,构建了“功能完备”与“精度完整”的通用性底座,全面覆盖从AI训练、推理到科学计算的全场景需求。
- 创新突破:单芯片覆盖多场景。基于MUSA架构的突破性设计,摩尔线程的GPU单芯片即可集成AI计算加速、图形渲染、物理仿真及超高清视频编解码能力,充分适配AI训推、具身智能、AIGC等多样化应用场景。
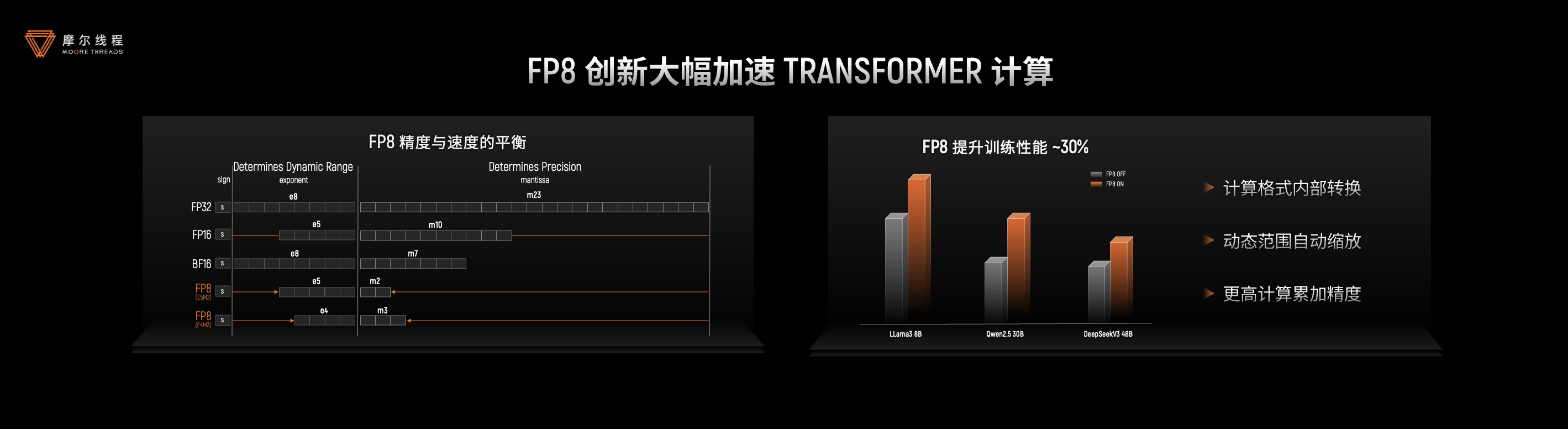
- 精度标杆:性能跃升20%~30%。在计算精度方面,摩尔线程支持从FP64至INT8的完整精度谱系,并通过FP8混合精度技术,在主流前沿大模型训练中实现20%~30%的性能跃升,为国产GPU的算力效率树立行业标杆。
- 前瞻布局:推动AI基础设施进化。这一技术体系不仅满足大模型时代的高效计算需求,更为世界模型和新兴AI架构的演化提供前瞻性支撑,助力AI基础设施向高通用性、高精度方向持续升级。


技术二:自研MUSA架构,提升芯片有效算力
强大的芯片有效算力是驱动“AI工厂”高效运转的核心动力。摩尔线程基于自研MUSA架构,通过计算、内存、通信三重突破,显著提升单GPU运算效率。
- 创新架构突破传统限制:摩尔线程采用创新的多引擎、可伸缩GPU架构,通过硬件资源池化及动态资源调度技术,构建了全局共享的计算、内存与通信资源池。这一设计不仅突破了传统GPU功能单一的限制,还在保障通用性的同时显著提升了资源利用率。其参数化配置可伸缩架构允许面向目标市场快速裁剪出优化的芯片配置,大幅降低了新品芯片的开发成本。
- 计算性能显著提升:在计算层面,摩尔线程的AI加速系统(TCE/TME)全面支持INT8/FP8/FP16/BF16/TF32等多种混合精度计算。作为国内首批实现FP8算力量产的GPU厂商,其FP8技术通过快速格式转换、动态范围智能适配和高精度累加器等创新设计,在保证计算精度的同时,将Transformer计算性能提升约30%。
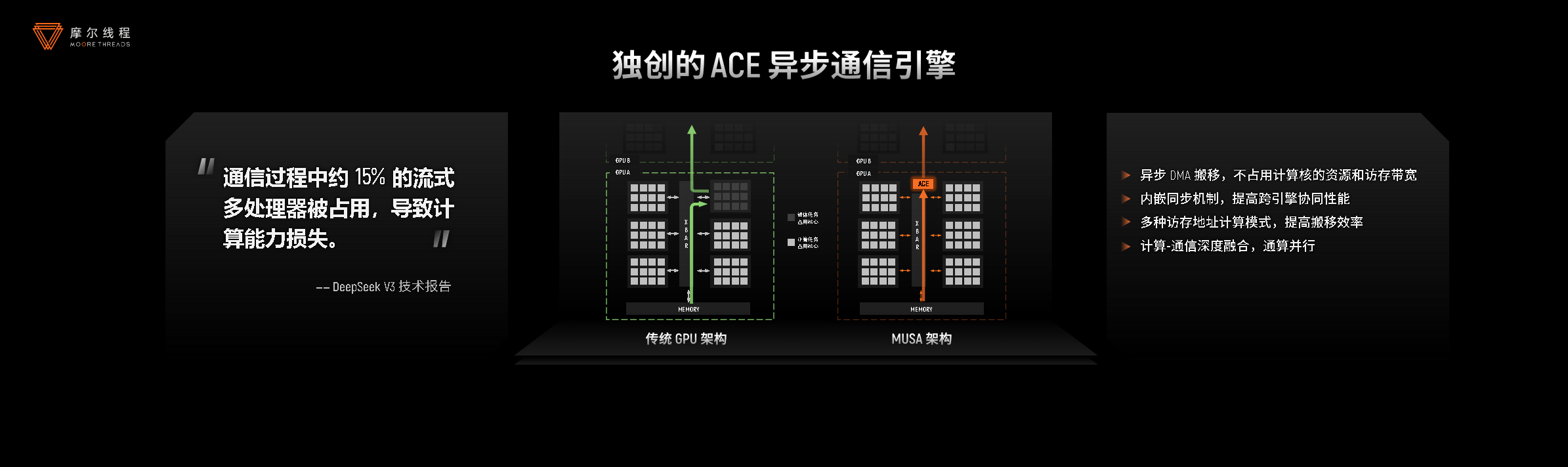
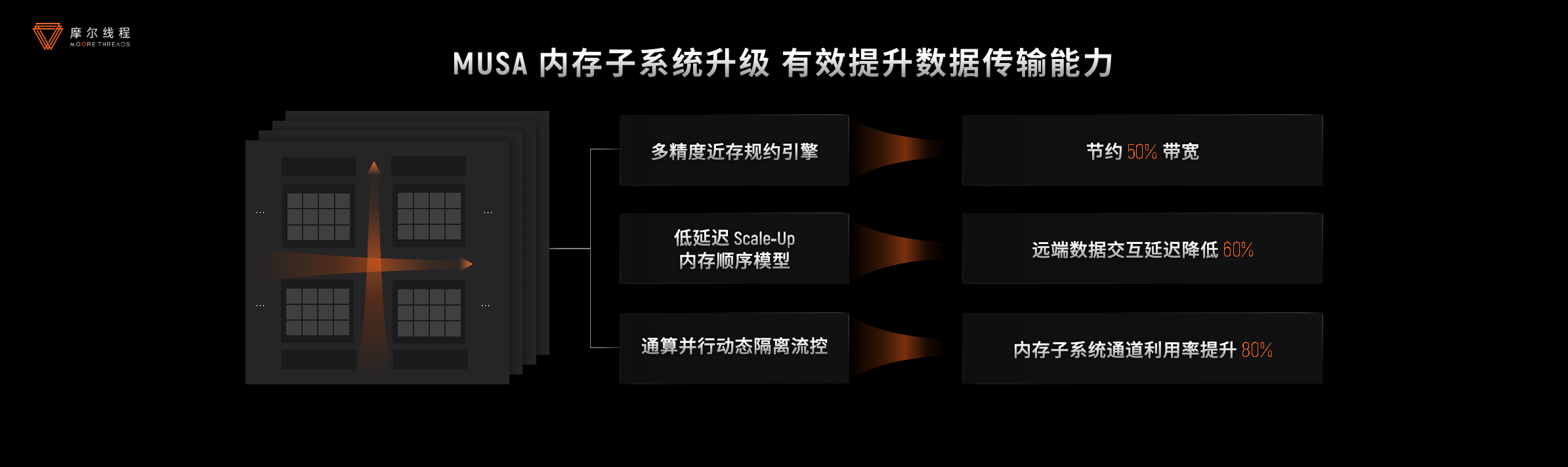
- 内存与通信效率全面优化:内存系统方面,通过多精度近存规约引擎、低延迟Scale-Up、通算并行资源隔离等技术,实现了50%的带宽节省和60%的延迟降低。在通信和互联领域,独创的ACE异步通信引擎减少了15%的计算资源损耗,MTLink2.0互联技术提供了高出国内行业平均水平60%的带宽,为大规模集群部署奠定了坚实基础。



技术三:MUSA全栈系统软件,提升单节点计算效率
当AI算力竞争进入深水区,摩尔线程通过MUSA全栈系统软件实现关键技术突破,推动AI工厂从单点创新转向系统级效能提升。其核心创新包括:
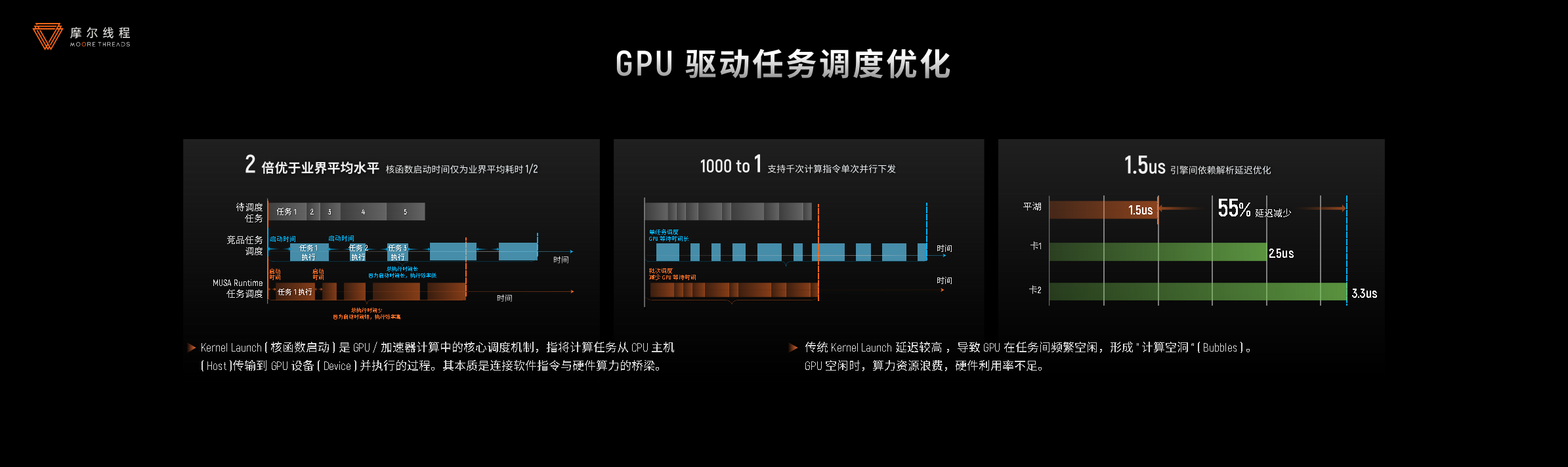
- 任务调度优化:核函数启动时间缩短50%;
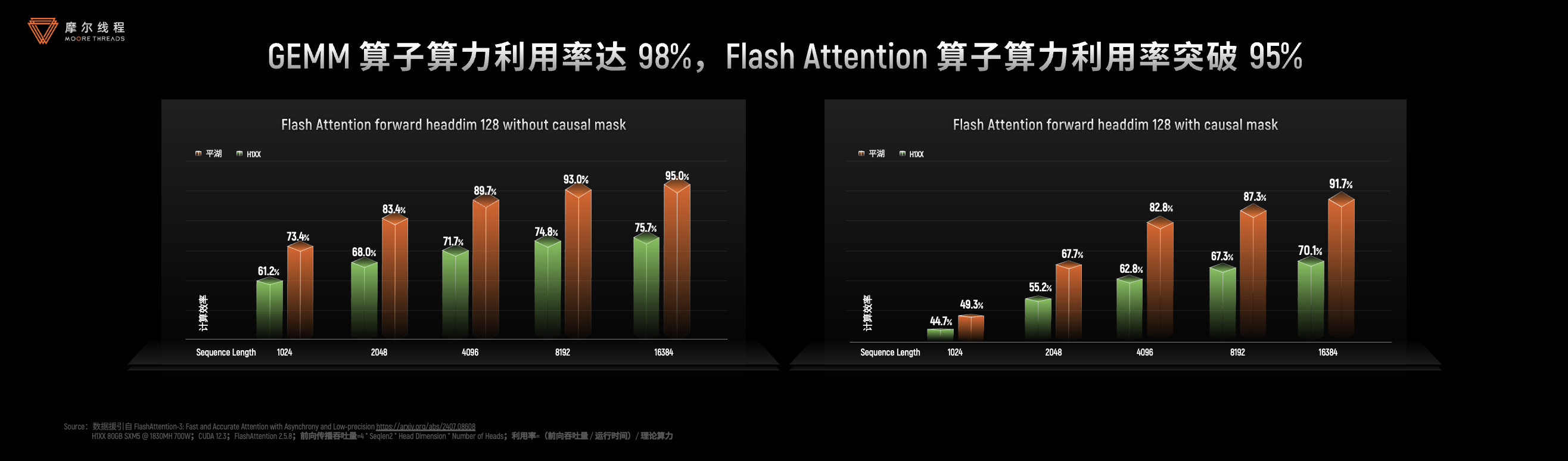
- 极致性能算子库:GEMM算子算力利用率达98%,Flash Attention 算子算力利用率突破95%;
- 通信效能跃升:MCCL通信库实现RDMA网络97%带宽利用率;基于异步通信引擎优化计算通信并行,集群性能提升10%;
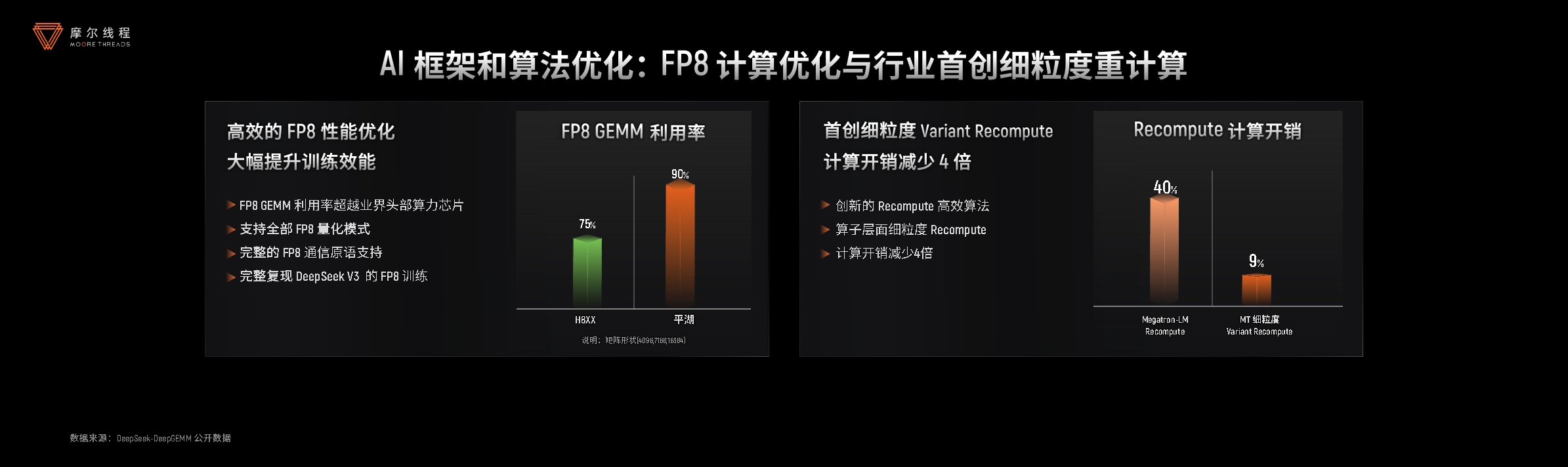
- 低精度计算效率革新:FP8优化与重计算技术显著降低训练开销;
- 开发生态完善:基于Triton-MUSA编译器+MUSA Graph 实现DeepSeek R1推理加速1.5倍,全面兼容Triton等主流框架。


技术四:自研KUAE大规模集群,优化集群效率
- 当单节点效率达到新高度,如何实现大规模集群的高效协作成为新的挑战。摩尔线程自研KUAE计算集群通过5D大规模分布式并行计算技术,实现上千节点的高效协作,推动AI基础设施从单点优化迈向系统工程级突破。
- 创新5D并行训练:摩尔线程整合数据、模型、张量、流水线和专家并行技术,全面支持Transformer等主流架构,显著提升大规模集群训练效率。
- 性能仿真与优化:自主研发的Simumax工具面向超大规模集群自动搜索最优并行策略,精准模拟FP8混合精度训练与算子融合,为DeepSeek等模型缩短训练周期提供科学依据。
- 秒级备份恢复:针对大模型稳定性难题,创新CheckPoint加速方案利用RDMA技术,将百GB级备份恢复时间从数分钟压缩至1秒,提升GPU有效算力利用率。



技术五:零中断容错技术,提升集群的稳定性和可靠性
在构建高效集群的基础上,稳定可靠的运行环境是“AI工厂”持续产出的保障。
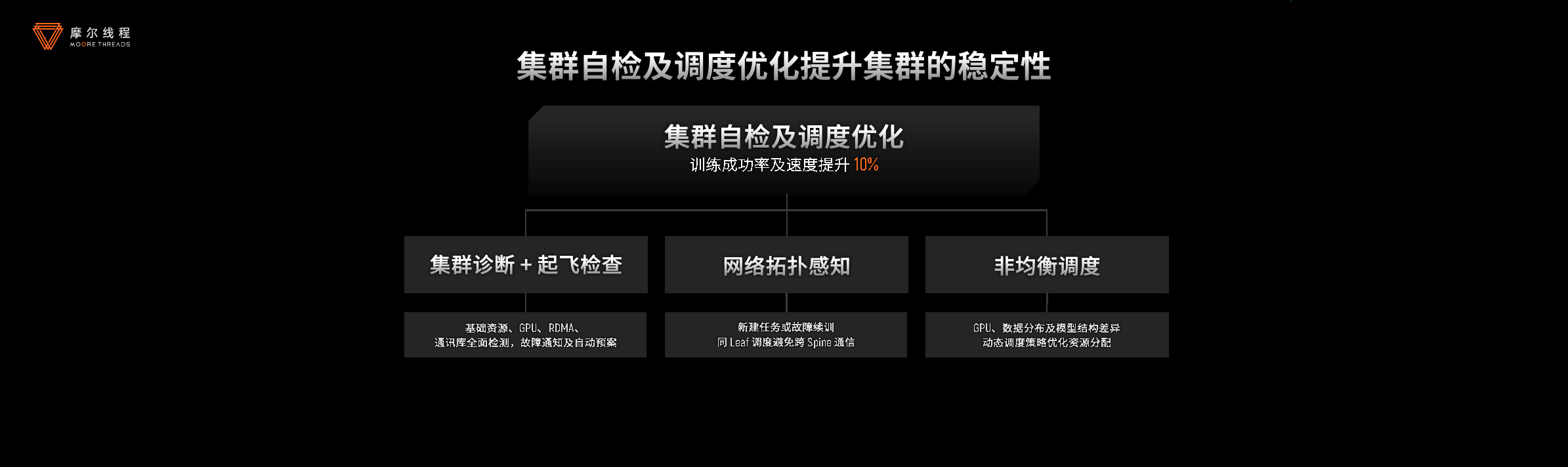
特别在万卡级AI集群中,硬件故障导致的训练中断会严重浪费算力。摩尔线程创新推出零中断容错技术,故障发生时仅隔离受影响节点组,其余节点继续训练,备机无缝接入,全程无中断。这一方案使KUAE集群有效训练时间占比超99%,大幅降低恢复开销。
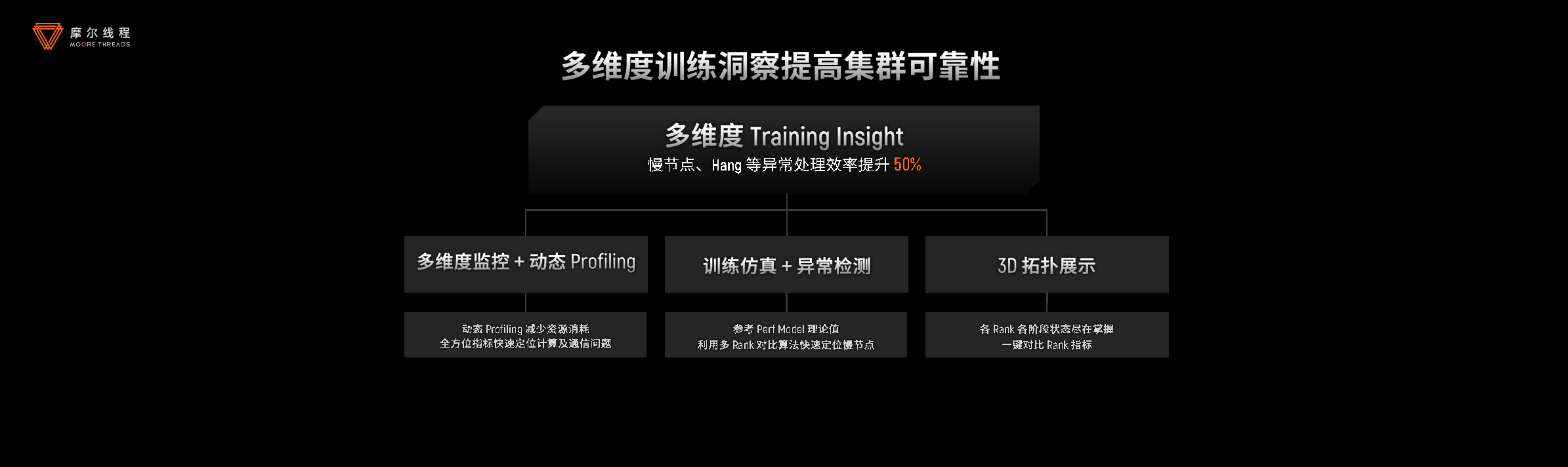
同时,KUAE集群通过多维度训练洞察体系实现动态监测与智能诊断,异常处理效率提升50%;结合集群巡检与起飞检查,训练成功率提高10%,为大规模AI训练提供稳定保障。

从训练到验证:构建完整闭环
摩尔线程以打造先进的“AI工厂”为目标,凭借全功能GPU的通用计算能力、创新的MUSA架构、优化的MUSA软件栈、自研的KUAE集群以及零中断容错技术这五大核心要素,构建起高效的“AI工厂”,为AI大模型训练提供了强大而可靠的基础设施支持。
完善的“AI工厂”不仅需要高效训练大模型,还需具备推理验证能力。摩尔线程基于自研MUSA技术栈,构建覆盖LLM、视觉、生成类模型的全流程推理解决方案,实现“训练-验证-部署”的无缝衔接。其MT Transformer自研推理引擎、TensorX自研推理引擎和vLLM-MUSA推理框架,为模型验证和部署提供极致性能支持。

AI工厂,驱动千行百业智能升级
依托AI工厂,摩尔线程成功构建起覆盖"训练-推理-部署"全流程的高效体系。这一突破标志着国产计算基础设施已具备支撑AGI时代规模化、高效率、高可靠模型生产的关键能力。

从图形渲染基石到AI算力引擎,摩尔线程全功能GPU持续加速计算革新。以“KUAE+MUSA”为智算业务核心,摩尔线程将加速赋能千行百业,推动全功能GPU驱动的AI技术在物理仿真、AIGC、科学计算、具身智能、智能体、医疗影像分析、工业大模型等关键领域的应用与部署。
同时,摩尔线程深知开放是生态繁荣之源。摩尔线程将于今年10月举办首届MUSA开发者大会,诚邀全球开发者共探前沿技术,共享MUSA自主新生态。
随着WAIC 2025正式拉开帷幕,摩尔线程以“全功能GPU,为美好世界加速”为主题,精彩亮相上海世博展览馆H1-A821展位,诚邀业界同仁莅临参观交流,共同见证国产人工智能基础设施的创新突破与发展。

关于摩尔线程
摩尔线程以全功能GPU为核心,致力于向全球提供加速计算的基础设施和一站式解决方案,为各行各业的数智化转型提供强大的AI计算支持。
我们的目标是成为具备国际竞争力的GPU领军企业,为融合人工智能和数字孪生的数智世界打造先进的加速计算平台。我们的愿景是为美好世界加速。
-
摩尔线程
+关注
关注
2文章
286浏览量
6663 -
大模型
+关注
关注
2文章
3772浏览量
5273
发布评论请先 登录
小马智行与摩尔线程达成战略合作
全栈国产AI Coding上线:摩尔线程+硅基流动+智谱,强强联合!

摩尔线程正式推出AI Coding Plan智能编程服务
算力即国力!摩尔线程架构/芯片/超节点/万卡集群四连发,助力打造AI国之重器

五大大模型支撑后勤保障方案生成系统软件的应用与未来发展
摩尔线程新一代大语言模型对齐框架URPO入选AAAI 2026
摩尔线程发布大模型训练仿真工具SimuMax v1.0

摩尔线程:五大核心技术提升 AI 工厂效率
摩尔线程副总裁王华:AI工厂全栈技术重构算力基建,开启国产 GPU 黄金时代

摩尔线程WAIC2025亮相:以“AI工厂”理念重塑算力生态 全栈产品开启智能新纪元

摩尔线程亮相WAIC 2025:以“AI工厂”理念驱动算力进化,全栈AI应用赋能千行百业

摩尔线程“AI工厂”:以系统级创新定义新一代AI基础设施
【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
【书籍评测活动NO.62】一本书读懂 DeepSeek 全家桶核心技术:DeepSeek 核心技术揭秘
关于AI工厂三阶段模型




评论