 算力时代,你的GPU选对了吗?三张表看清专业卡与消费卡的本质差异
算力时代,你的GPU选对了吗?三张表看清专业卡与消费卡的本质差异

显存大小只是冰山一角,单/双精度算力才是决定GPU真实性能的关键。
一、显存越大越好?警惕选购陷阱
许多用户在挑选GPU时,第一眼总盯着显存容量。我们整理了当前显存Top 10的王者:
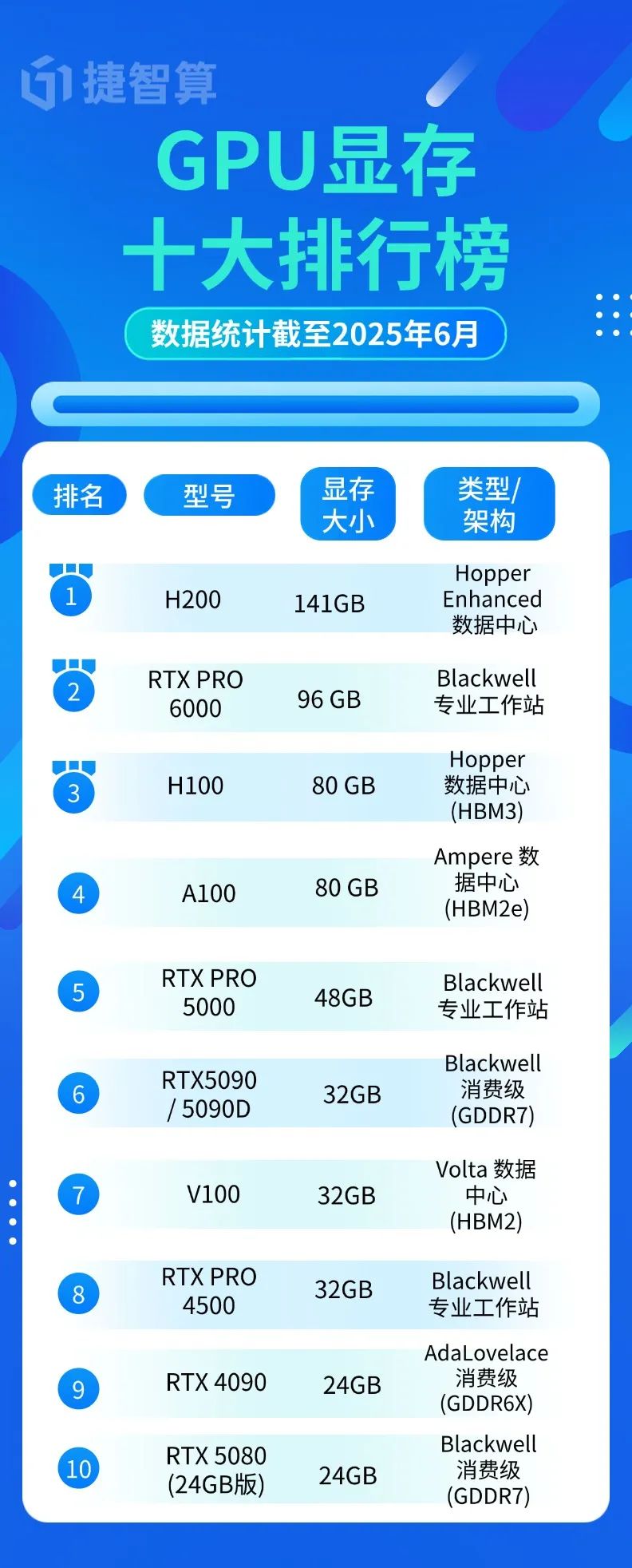
关键发现:
- H200以141GB成为科学计算新王者
- 旗舰RTX 5090仅32GB,甚至落后于5年前的数据中心卡V100
- 显存类型决定带宽:GDDR6X(如RTX 4090)性能远逊于HBM3
选购建议:大模型训练选96GB PRO 6000,4K游戏选24GB RTX 4090足矣!
二、单精度算力:游戏与创作的性能基石
当涉及图形渲染、AI推理等场景,FP32算力才是核心指标:
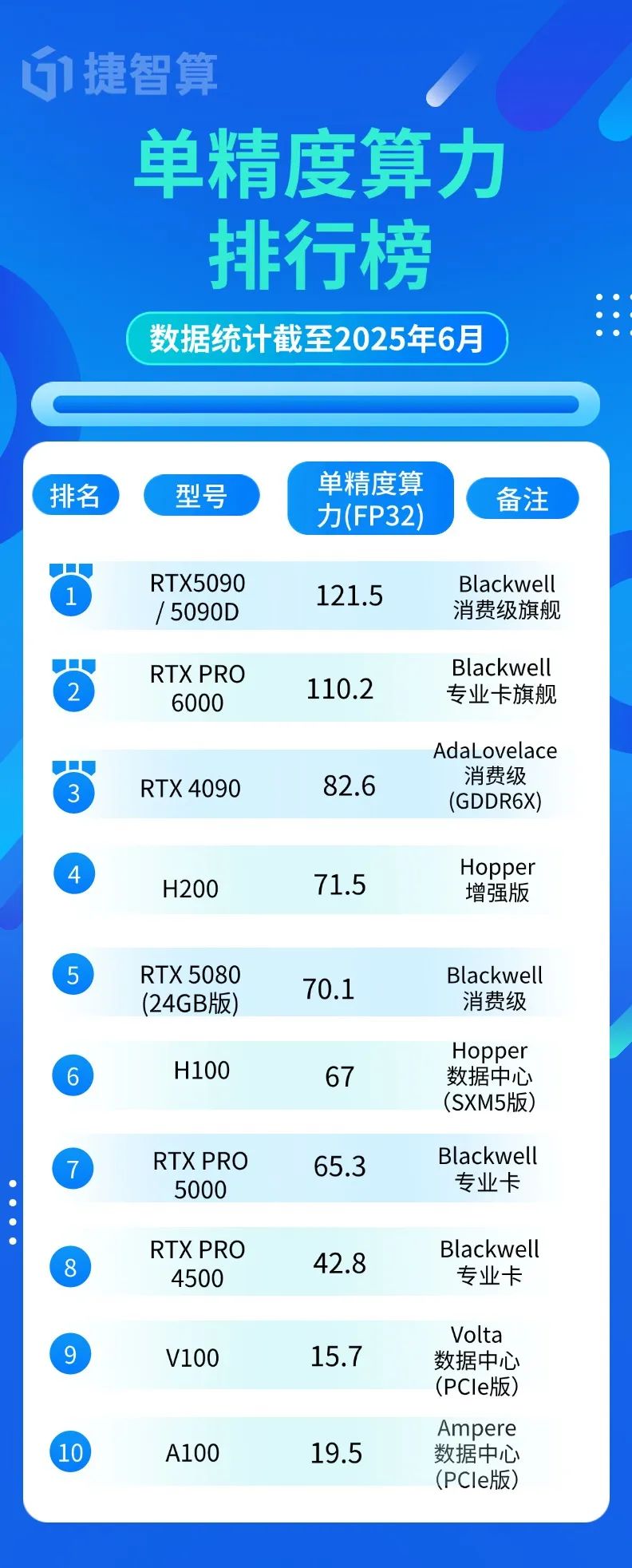
颠覆认知的真相:
- 消费级RTX 5090/5090竟以121.5 TFLOPS超越所有专业卡
- 专业卡RTX PRO 6000(110.2 TFLOPS)更适合多卡并联的稳定计算
- 老将RTX 4090仍以82.6 TFLOPS稳居消费卡第二
选购建议:游戏/视频剪辑优先看FP32,RTX 5090 > RTX 4090 > RTX 5080
三、双精度算力:科学计算的照妖镜
FP64性能差距才是专业卡与消费卡的本质分水岭:

双精度真相:
- 专业卡保留完整FP64单元(PRO 6000达55.1 TFLOPS)
- 消费级显卡普遍存在双精度阉割(FP64≈FP32的1/64)
- H200以40.2 TFLOPS成为新一代科学计算标杆
选购建议:流体仿真、量子计算等必须选专业卡(*以上建议仅供参考;本文数据来源于NVIDIA官方技术白皮书及TechPowerUp测试平台,2025年6月更新。)面对专业显卡高昂的成本与快速迭代的压力,越来越多的的个人和企业用户转向算力租赁服务。捷智算平台提供4090、5090、A100等多种高性能GPU显卡租赁,灵活选择型号和时长,无需购置硬件即可享受顶尖算力资源。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
5271浏览量
136069 -
显存
+关注
关注
0文章
112浏览量
14116 -
算力
+关注
关注
2文章
1673浏览量
16833
发布评论请先 登录
相关推荐
热点推荐
华为领衔,三剑客入局!十万卡智算集群落地,国产算力芯片强势崛起
中国移动宣布,将持续加大对人工智能领域的投入力度,总体投入翻一番,建成国内规模最大、技术领先的智算基础设施,探索十万卡智算集群建设,全国产智能算力

Java并发编程的“基石”——多线程概念初识
领域里,Java 正凭借其深厚的并发底层基石,悄然成为支撑未来算力调度的隐形王者。(搜星 课it。top)
一、 算力调度的本质:一场极端的
发表于 04-16 18:50
Hailo-8算力卡 + RK3588实测!26TOPS加持,助力AI视觉升级!
近年来,AI视觉在边缘端应用广泛,行业对AI推理硬件的要求也日益提升。传统CPU在CNN等视觉模型推理任务中逐渐显露瓶颈,而专用AI加速器成为破局的关键。 Hailo-8 AI算力加速卡凭借“高效

中科曙光scaleX万卡超集群重塑超大规模算力基础设施
在“人工智能+”行动深入推进的当下,算力基础设施已成为国家战略竞争力的核心,而超大规模集群的运维管控难题却日益凸显。中科曙光scaleX万卡超集群打造的智能管理体系,正以“能管住-管得
GPU 利用率<30%?这款开源智算云平台让算力不浪费 1%
作为 AI 开发者,你是否早已受够这些困境:花数百万采购的 GPU 集群,利用率常年低于 30%,算力闲置如同烧钱;跨 CPU/GPU/NP
墨芯人工智能千卡集群正式签约入驻新疆算力中心
在“东数西算”国家工程全面推进的大背景下,新疆凭借其丰富的清洁能源和独特的区位优势,正迅速崛起为国家级算力网络的关键枢纽。近日,墨芯人工智能(以下简称“墨芯”)的千卡集群正式签约入驻新

英伟达 H100 GPU 掉卡?做好这五点,让算力稳如泰山!
H100服务器停工一天损失的算力成本可能比维修费还高。今天,我们给大家总结一套“防掉卡秘籍”,从日常管理到环境把控,手把手教你把掉卡风险压到最低。一、供电是“生命线”,这3点必须盯紧H

aicube的n卡gpu索引该如何添加?
请问有人知道aicube怎样才能读取n卡的gpu索引呢,我已经安装了cuda和cudnn,在全局的py里添加了torch,能够调用gpu,当还是只能看到默认的gpu0,显示不了
发表于 07-25 08:18
拉曼光谱专题2 | 拉曼光谱中的共聚焦方式,您选对了吗?
拉曼光谱专题2|拉曼光谱中的共聚焦方式,您选对了吗?——共聚焦技术与AUT-XperRam共聚焦显微拉曼光谱仪系统什么是共聚焦技术:共聚焦技术的核心就像给相机和探测器配备了一对“精准定位的眼睛

热插拔算力集群
能力 服务器节点热插拔:集群服务器支持在线更换计算节点(如2U服务器容纳12个热插拔AI节点,单节点集成5个算力卡)。 GPU/算
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
自家GPU 提出的多卡算力互连技术,是早期为了应对深度学习对超高算力需求而单卡
发表于 06-18 19:31
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!
随着AI技术火得一塌糊涂,大家都在谈"大模型"、"AI加速"、"智能计算",可真到了落地环节,算力才是硬通货。你有没有发现,现在越来越多的AI企业不光用GPU,也不怎么迷信TPU了?他

控制系统调优必备知识:“运动控制卡 控制周期怎么算”你真的懂了吗?
在工业自动化领域,运动控制卡控制周期这个参数常常被忽视,但它却是影响整个系统稳定性、精度甚至产能的关键因素。你是不是也遇到过这些问题:电机总是抖动?轨迹跟踪老是偏?想优化系统却无从下手?大概率是你的运动控制




评论