 通过NVIDIA RTX PRO服务器加速企业工作负载
通过NVIDIA RTX PRO服务器加速企业工作负载

从大语言模型(LLM)到代理式 AI 推理和物理 AI ,随着 AI 工作负载的复杂性和规模不断增加,人们对更快、扩展性更高的计算基础设施的需求空前强烈。满足这些需求就要从基础开始重新思考系统架构。
NVIDIA 正在通过NVIDIA ConnectX-8 SuperNIC升级平台架构。NVIDIA ConnectX-8 SuperNIC 是业内首款在单个设备中集成PCIe6.0 交换机和超高速网络的 SuperNIC。ConnectX-8 专为现代 AI 基础架构设计,可提供更高的吞吐量,同时简化系统设计,并提高能效和成本效益。
为 PCIe6.0 连接的时代做好准备
在基于 PCIe 连接的平台中,尤其是配备 8 个或更多 GPU 的平台,PCIe 交换机对于最大化 GPU 间通信带宽和实现可扩展的 GPU 拓扑至关重要。现有设计依赖于独立的 PCIe 交换机,这通常会增加设计复杂性,并可能会限制性能和效率。
ConnectX-8 通过内置的 PCIe6.0 交换机提供 48 通道的 PCIe6.0 连接解决了这一问题。将 GPU 到 GPU 和 GPU 到 NIC 通信整合到单一高性能设备中,消除了对独立 PCIe 交换机的需求,减少了元器件数量并简化了主板设计,为 AI 基础设施打造了更具成本效益、可扩展的架构。
此外,凭借原生 PCIe6.0 支持,ConnectX-8 可满足新一代 GPU、CPU 和 IO 加速器日益增长的 IO 需求。它使系统架构师能够设计出向前兼容的平台,能够充分享用领先的高吞吐 PCIe6.0 设备的带宽。
通过 NVIDIA RTX PRO 服务器加速企业工作负载
ConnectX-8 SuperNIC 现已全面投产。 在 COMPUTEX 2025 上,ConnectX-8 被发布用于全球各系统合作伙伴的 NVIDIA RTX PRO 服务器中。
图 1 比较了两种服务器架构:采用独立 PCIe 交换机的传统设计,以及采用 NVIDIA ConnectX-8 SuperNIC 集成 PCIe6.0 交换机的 NVIDIA RTX PRO 服务器的 优化配置。
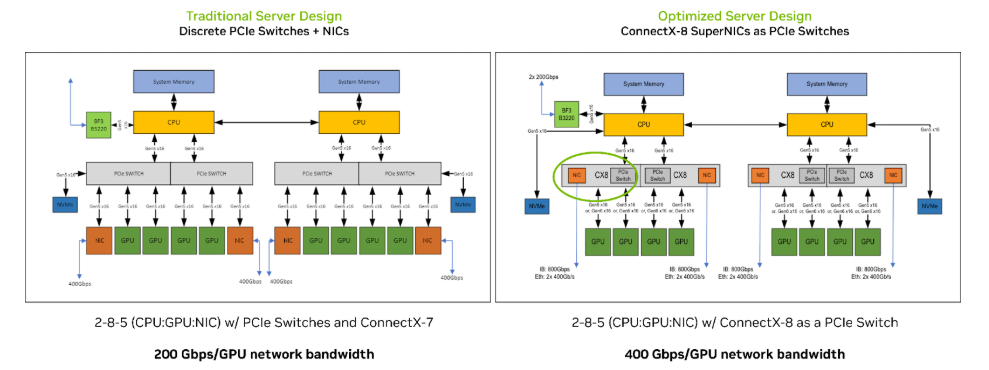
图 1:传统(左)和与采用 ConnectX-8 SuperNIC 优化(右)服务器设计的比较
在传统设计中,服务器布局包括 2 个 CPU、8 个 GPU 和 5 个 NIC(包括 4 个 NVIDIA ConnectX-7 NIC 和 1 个 NVIDIA BlueField-3 DPU)。这种配置还需要两到四个独立的 PCIe 交换机来实现 GPU 到 GPU 和 GPU 到 NIC 的连接,从而增加复杂性和组件数量。
在优化过的设计中,用 ConnectX-8 SuperNIC 替换掉了专用 PCIe 交换机,将 PCIe6.0 交换和 800 Gb/s 网络集成在了单一网卡设备中。
它使每个 GPU 的网络带宽翻倍,有助于消除 IO 瓶颈,并加快 GPU、NIC 和存储之间的数据移动速度。因此,此 NVIDIA RTX PRO 服务器平台可提供高达 2 倍的 NCCL all-to-all 性能,加速在多 GPU 和多节点工作负载中至关重要的集合通信,并提高 AI 工厂的可扩展性。
在图 1 的基础上,图 2 让我们更深入地了解经过优化设计的服务器架构如何改善三种主要 GPU 通信路径之间的连接:
GPU 到 GPU 通信跨越两个 CPU 插座:在传统设计中,此路径可能会遇到主机 CPU 和内部插座瓶颈问题,根据 CPU 之间链路的利用率不同,可能被限制在 25 GB/s 或更低的速度。相比之下,基于 ConnectX-8 的优化设计可为集群内的所有 GPU 间通信提供高达 每个GPU 50 GB/s 的 IO 带宽,因为 NCCL 直接通过网络转发所有流量。
GPU 到 NIC 通信:在 2:1 的 GPU 到 NIC 配置下,经过优化的架构为每个 GPU 提供 50 GB/s 的带宽,无论 GPU 或主机系统是 PCIe5.0 或 PCIe6.0。
GPU 到 GPU 通信通过同一 PCIe 交换机:相较 PCIe5.0,配备 PCIe6.0 的系统可将带宽提高一倍,从而显著加速同一 PCIe 交换机上的点对点 GPU 传输。
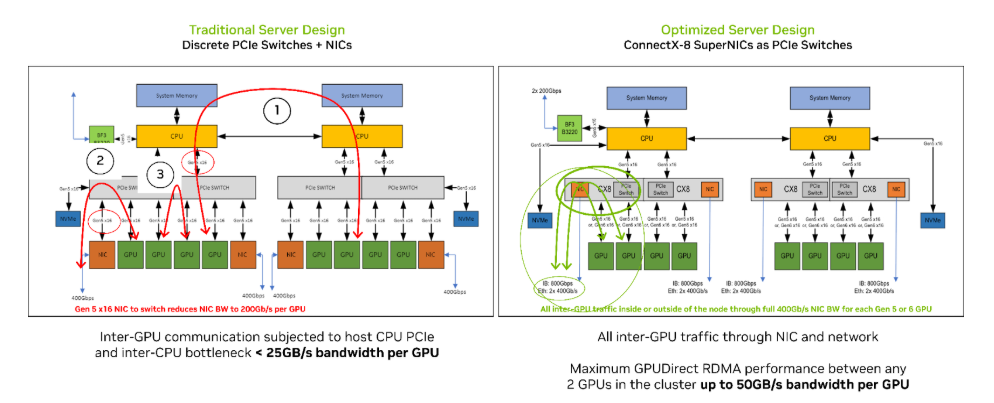
图 2:传统(左)和与采用 ConnectX-8 SuperNIC 的优化(右)服务器设计的比较,强调了三种关键的 GPU 通信路径
通过将 PCIe 交换直接集成到 SuperNIC 中,ConnectX-8 还简化了主板设计、改善了气流并增强了可维护性。这将打造一个更紧凑、更节能、更经济高效的平台。在 NVIDIA 参考设计的支持下,这项创新可帮助系统厂商更快地扩展其系统,并提高性能及降低 TCO。
基于 PCIe 总线的 AI 基础架构的未来
NVIDIA ConnectX-8 正在重新定义基于 PCIe 总线的系统的可能性。通过将 PCIe6.0 交换机和高性能 SuperNIC 集成到单一集成设备中,ConnectX-8 可简化服务器设计,减少组件数量,并解锁现代 AI 工作负载所需的高带宽通信路径。从而打造更简单、更节能的平台,同时降低总体拥有成本(TCO)并实现出色的性能可扩展性。
此外,ConnectX-8 SuperNIC 还可在基于多 GPU 的平台中实现增强的机密计算能力。
在 COMPUTEX 2025 上,领先的数据中心合作伙伴展示了由内置 NVIDIA ConnectX-8 SuperNIC 的 NVIDIA RTX PRO 服务器所加速的先进 AI 平台架构。
-
NVIDIA
+关注
关注
14文章
5682浏览量
110102 -
总线
+关注
关注
10文章
3056浏览量
91862 -
AI
+关注
关注
91文章
40982浏览量
302534 -
PCIe
+关注
关注
16文章
1474浏览量
88898
原文标题:NVIDIA ConnectX-8 SuperNIC 通过 PCIe6.0 总线升级 AI 平台架构
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA RTX PRO 2000 Blackwell GPU性能测试

基于NVIDIA GPU的加速服务 为AI、机器学习和AI工作负载提速
nVidia许可服务器存在问题
RTX刀片服务器实现云渲染密度、效率及可扩展性的飞跃
NVIDIA虚拟工作站新版本可支持RTX服务器
NVIDIA公布通过NVIDIA认证系统测试的全球首批加速服务器 企业 AI 使用量倍增
NVIDIA Grace超级芯片为HPC及AI工作负载提速

使用NVIDIA Triton推理服务器来加速AI预测
NVIDIA Blackwell RTX PRO 提供工作站和服务器两种规格,助力设计师、开发者、数据科学家和创作人员构建代理式

NVIDIA加速的Apache Spark助力企业节省大量成本

NVIDIA RTX PRO 4500 Blackwell GPU测试分析

NVIDIA RTX PRO 4000 Blackwell GPU性能测试

NVIDIA RTX PRO 5000 Blackwell GPU的深度评测




评论