 NVIDIA RTX 5880 Ada与Qwen3系列模型实测报告
NVIDIA RTX 5880 Ada与Qwen3系列模型实测报告

近日,阿里巴巴通义千问团队正式推出新一代开源大语言模型——Qwen3 系列,该系列包含 6 款 Dense 稠密模型和 2 款 MoE 混合专家模型,参数规模覆盖 0.6B 至 235B,构建了覆盖全场景的 AI 模型矩阵。其中旗舰模型 Qwen3-235B-A22B 在代码、数学及通用能力基准测试中,展现出与 DeepSeek-R1、OpenAI-o1、Grok-3、Gemini-2.5-Pro 等顶级模型比肩的实力。
而对于Qwen3-30B-A3B,其激活量只有 QwQ-32B 的 10%,表现超过 DeepSeek V3/GPT-4o。就中小型企业的定制化需求而已,从部署成本角度看,Qwen3-30B-A3B 相较于先前热门 Deepseek-R1-70B(BF16),部署成本降低约 40%,其模型性能表现接近 Qwen2.5-72B 级别的性能。使得中小企业在有限预算下即可实现高水准的 AI 应用定制,进一步降低了技术落地门槛。
Qwen3 集合 6 款 Dense 稠密模型:从适用于轻量级任务的 Qwen3-0.6B、1.7B,到应对中大型复杂场景的 4B、8B、14B,再到超大规模算力需求的 32B,以及 2 款 MoE 模型 Qwen3-30B-A3B、Qwen3-235B-A22B,形成丰富完备的模型体系,全方位满足不同层次、不同类型的应用需求。
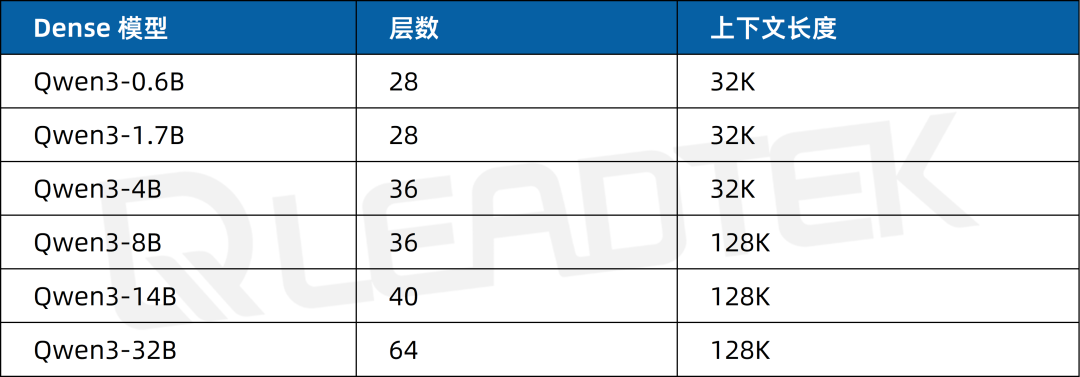

▲ Qwen3 系列模型一览
1 Qwen3 技术突破与核心优势
作为实现"双模推理"的开源模型,Qwen3 创新性融合了深度思考与快速响应机制:混合推理模型,具备思考和快速回答双模式。
思考模式:模型通过多步推理和深度分析以解决复杂问题,类似人类理性决策过程。这种模式适用于需要深入思考的复杂问题。
快速回答(非思考模式):模型提供快速、近乎即时的响应,直接基于已有的知识和简单的逻辑关系生成答案,而不会进行深入的多步推理。这种模式适用于那些对速度要求高于深度的简单问题。
简单来说,类似于将 DeepSeek-R1 和 V3 揉在一起。既可以当没有思维链的普通模型,又可以开启深度思考模式变成推理模型。用户可以通过设置enable_thinking参数来实现两种模式的切换。
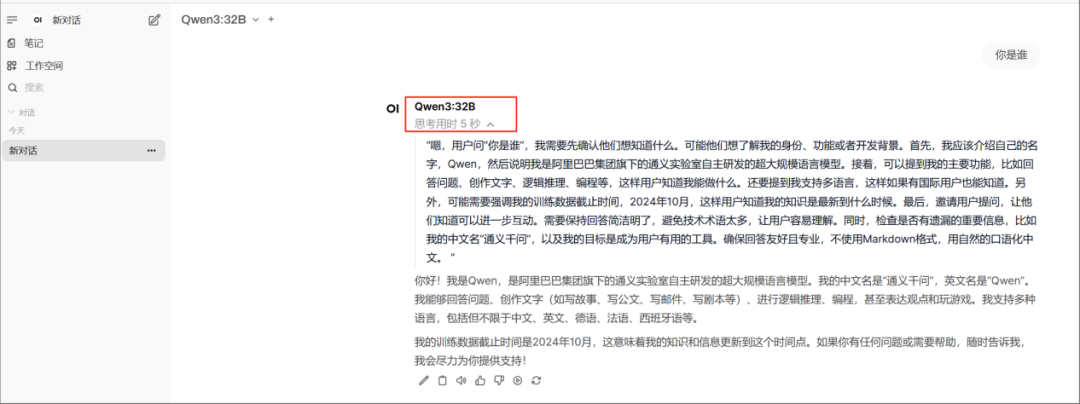
▲ Qwen3 思考模式

▲ Qwen3 快速回答
此外,Qwen3 还具备以下优势:
模型能力跻身全球 top。
MoE 和 Dense 两种架构共 8 款模型,基本覆盖所有应用场景。
Agent 能力升级:优化了 Qwen3 模型的 Agent 和代码能力,同时支持最新的 MCP(模型上下文协议)。
支持 119 种语言。
海量训练数据:Qwen3 使用的数据量达到了约 36 万亿个 token。
Qwen3 系列通过"小而强大"的技术突破(如 30B 模型超越 72B 前辈),为中小企业提供高性价比 AI 解决方案。其 Apache2.0 开源协议和免费商用特性,能够配合 AI 一体机基础设施支持,推动 AI 应用进入"平民化"时代。随着混合推理模式的普及,Qwen3 或将重新定义大模型在智能客服、代码开发、科研创新等领域的应用范式。
2 2/4 卡 RTX 5880 Ada 实测报告
2.1 测试环境
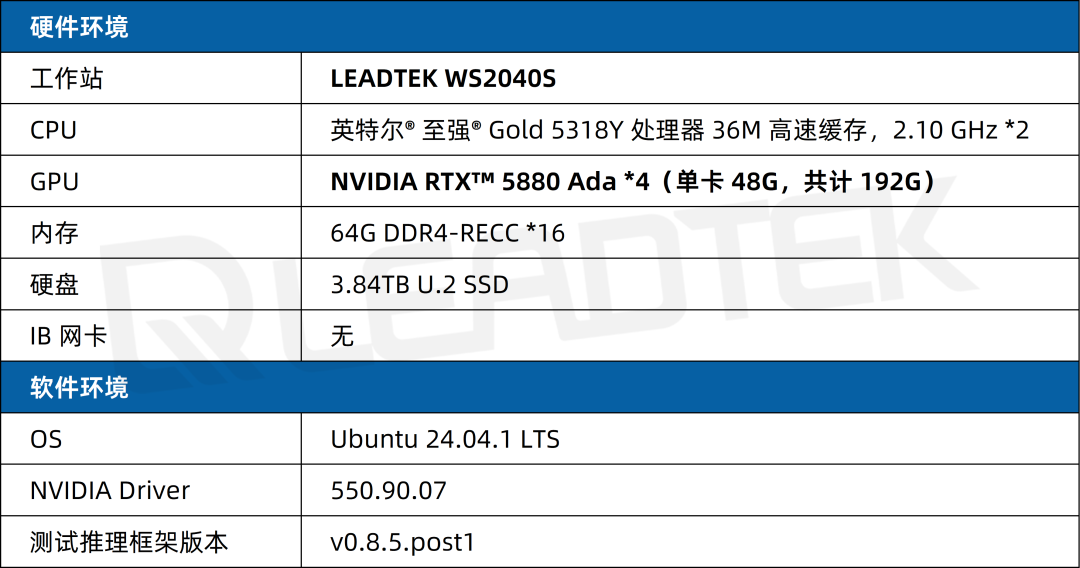
2.2 测试指标
首次 token 生成时间(Time to First Token, TTFT(s))越低,模型响应速度越快;每个输出 token 的生成时间(Time Per Output Token, TPOT(s))越低,模型生成文本的速度越快。
输出 Token 吞吐量(Output Token Per Sec, TPS):反映系统每秒能够生成的输出 token 数量,是评估系统响应速度的关键指标。多并发情况下,使用单个请求的平均吞吐量作为参考指标。
首次 Token 生成时间(Time to First Token, TTFT(s)):指从发出请求到接收到第一个输出 token 所需的时间,这对实时交互要求较高的应用尤为重要。多并发情况下,平均首次 token 时间 (s) 作为参考指标。
单 Token 生成时间(Time Per Output Token,TPOT(s)):系统生成每个输出 token 所需的时间,直接影响了整个请求的完成速度。多并发情况下,使用平均每个输出 token 的时间 (s) 作为参考指标。这里多并发时跟单个请求的 TPOT 不一样,多并发 TPOT 计算不包括生成第一个 token 的时间。
并发数(Concurrency):指的是系统同时处理的任务数量。适当的并发设置可以在保证响应速度的同时最大化资源利用率,但过高的并发数可能导致请求打包过多,从而增加单个请求的处理时间,影响用户体验。
2.3 测试场景
在实际业务部署中,输入/输出 token 的数量直接影响服务性能与资源利用率。本次测试针对两种不同应用场景设计了具体的输入 token 和输出 token 配置,以评估模型在不同任务中的表现。具体如下:

2.4 测试结果
4 卡 NVIDIA RTX 5880 Ada 测试
文本生成场景测试中,单请求吞吐量约39.07tokens/s,并发 200 时降至约10.59tokens/s。
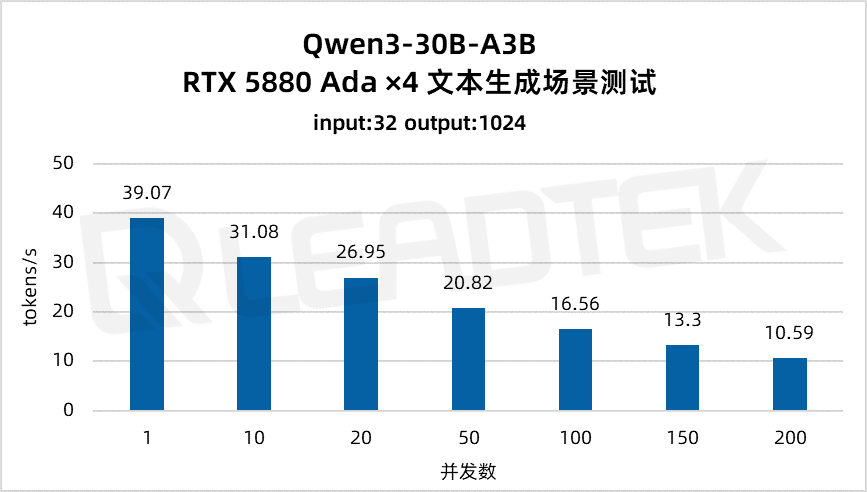
▲ 4 卡 RTX 5880 Ada 文本生成场景测试结果图表
2025 丽台(上海)信息科技有限公司
本文所有测试结果均由丽台科技实测得出,如果您有任何疑问或需要使用此测试结果,请联系丽台科技(下同)
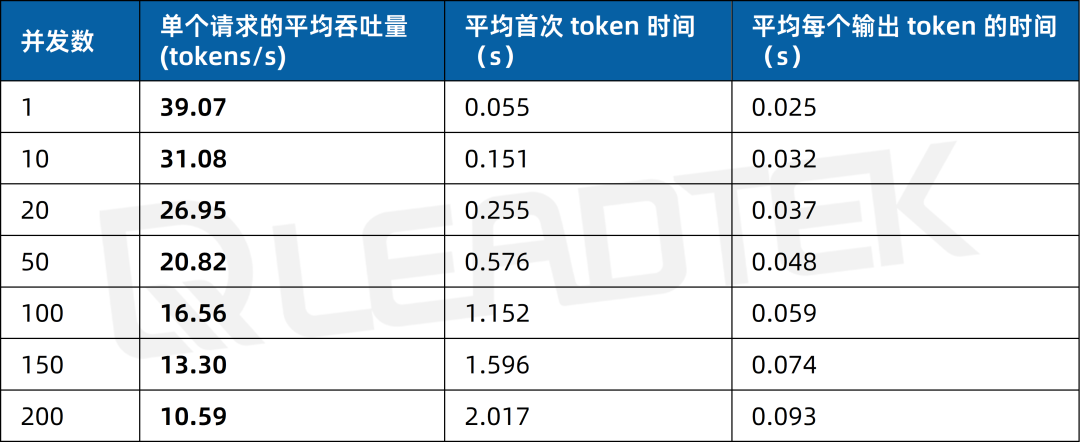
文本总结场景测试中,单请求吞吐量约38.35tokens/s,并发 150 时降至约10.78tokens/s。
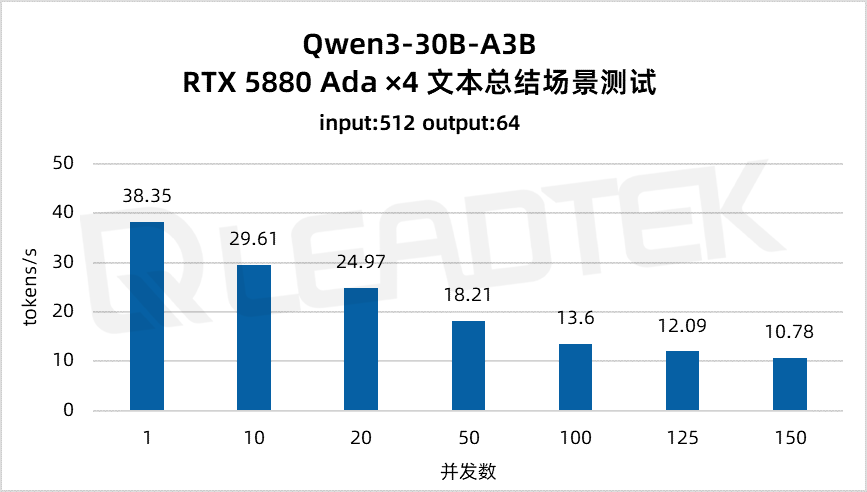
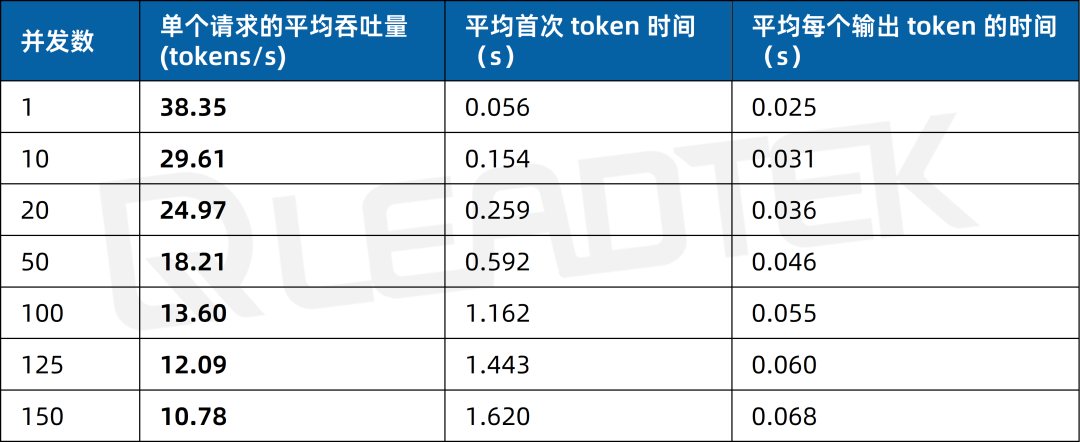
▲ 4 卡 RTX 5880 Ada 文本总结场景测试结果图表
2 卡 NVIDIA RTX 5880 Ada 测试
文本生成场景测试中,单请求吞吐量约25.14tokens/s,并发 150 时降至约9.24tokens/s。
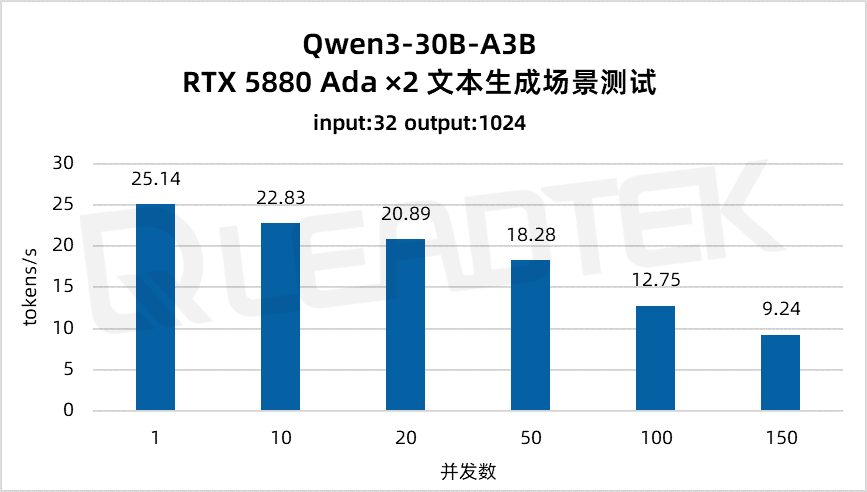
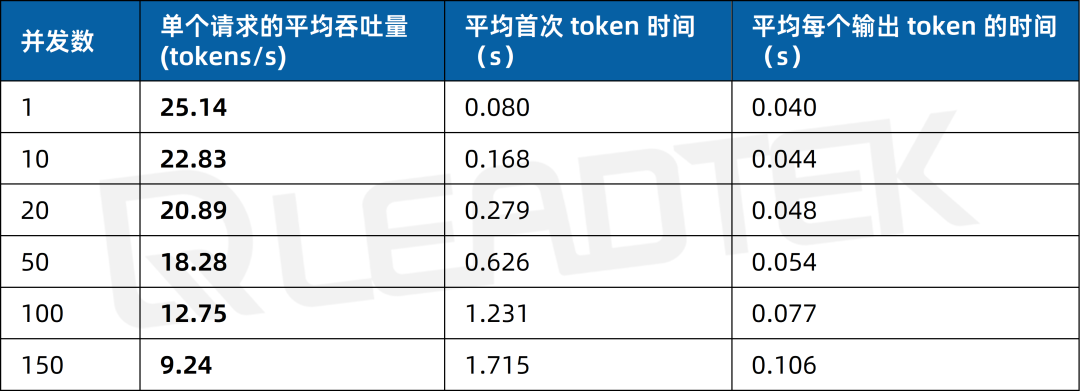
▲ 2 卡 RTX 5880 Ada 文本生成场景测试结果图表
文本总结场景测试中,单请求吞吐量约23.63tokens/s,并发 150 时降至约8.75tokens/s。
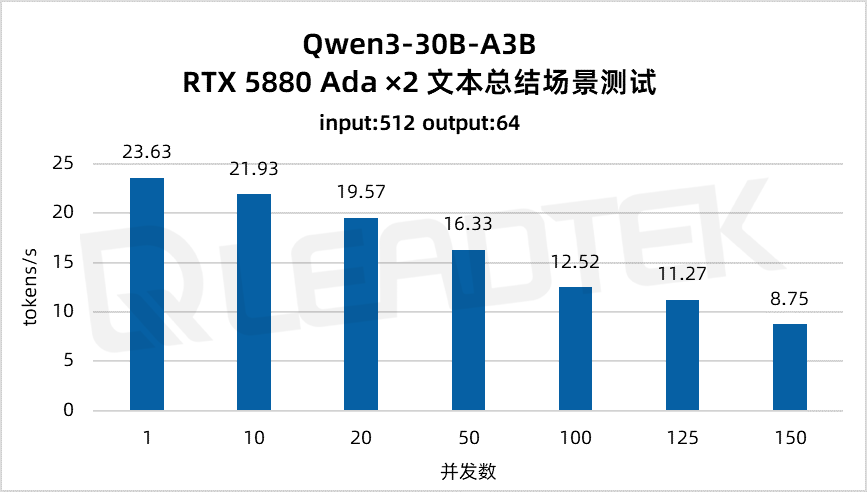
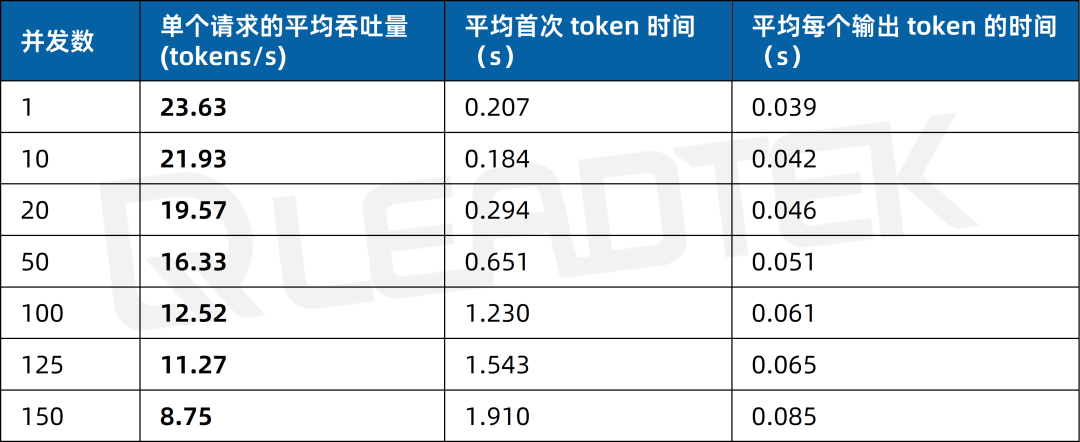
▲ 2 卡 RTX 5880 Ada 文本总结场景测试结果图表
3 总结
3.1 性能亮点速览
高并发文本生成场景:4 卡优势显著
输入 32 tokens + 输出 1024 tokens(文本生成)
4 卡配置:150 并发下吞吐量13.30tokens/s,较 2 卡(9.24 tokens/s)提升43.94%;
延迟表现:4 卡的“首次 token 时间”显著低于 2 卡,响应更敏捷。
文本总结场景:吞吐与延迟平衡
输入 512 tokens + 输出 64 tokens(文本总结)
4 卡配置:150 并发下吞吐量10.78tokens/s,延迟控制在1.62s内;
2 卡配置:适配 100 并发以内场景,吞吐量12.52tokens/s,满足日常推理需求。
吞吐量衰减率:4 卡更稳定
随着并发数从 1 增至 200,并发量翻倍时,4 卡吞吐量衰减率(63%),体现更强的负载均衡能力。
3.2 Leadtek AI 一体机

▲ Leadtek AI 一体机
基于NVIDIA RTX 5880 Ada显卡的 Leadtek AI 一体机,搭配通义千问 Qwen3-30B-A3B 模型,在大模型推理场景中展现出卓越性能:
4 卡配置:在高并发(200 并发)下仍能保持10.59 tokens/s的吞吐量,且单请求延迟可控;
2 卡配置:在中低并发场景下表现稳定,满足中小型任务需求;
NVIDIA RTX 5880 Ada完美适配 Qwen3-30B-A3B 的 MoE 结构(激活参数仅 30 亿,性能超越 QwQ-32B),实现高效能比。
适用场景
智能办公与教育:智能办公助手(如日程管理、文档生成);个性化学习辅导(根据学生进度定制内容);教育领域的智能答疑与内容创作。
企业级应用与开发:智能客服(高效处理用户咨询);复杂任务推理(数学计算、编程分析,需思考模式);API 集成与微调(适配特定业务需求,如工具调用)。
目前,丽台训推一体机、大模型一体机等都已集成 Qwen3 系列模型。
Leadtek AI 一体机凭借NVIDIA RTX 5880 Ada的硬核性能与Qwen3-30B-A3B的卓越优化,重新定义了本地化大模型推理的天花板。无论是追求极限吞吐的商业场景,还是注重成本效益的中小团队,都能寻求到最优解。
-
AI
+关注
关注
91文章
41401浏览量
302753 -
开源
+关注
关注
3文章
4375浏览量
46487 -
大模型
+关注
关注
2文章
3809浏览量
5282
原文标题:Qwen3 正式发布!30B 大模型 4 卡 RTX 5880 Ada 实测
文章出处:【微信号:Leadtek,微信公众号:丽台科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Intel OpenVINO™ Day0 实现阿里通义 Qwen3 快速部署
在openEuler上基于vLLM Ascend部署Qwen3
NVIDIA使用Qwen3系列模型的最佳实践

NVIDIA RTX 5000 Ada显卡性能实测报告

RTX 5880 Ada Generation GPU与RTX™ A6000 GPU对比

NVIDIA RTX 4500 Ada与NVIDIA RTX A5000的对比
NVIDIA RTX 5880 Ada显卡部署DeepSeek-R1模型实测报告

壁仞科技完成阿里巴巴通义千问Qwen3全系列模型支持
几B都有!BM1684X一键适配全系列Qwen3




评论