 基于最近将深度强化学习应用于迷宫导航的研究
基于最近将深度强化学习应用于迷宫导航的研究

在每个人的童年时期,我们是如何学会记住自己家附近的路的?我们是怎样学会自己去朋友家、学校或者去小卖部的?在没有地图的情况下,我们可能只是简单地记住了某条路长什么样,凭记忆引导自己。慢慢地,我们逐渐熟悉了自己的日常活动范围,就变得有信心了,能知道自己身在何处,并且学习了新的更复杂的道路。偶尔你可能会迷路,但是凭借某个标志甚至太阳你又能找到正确的路。
在非结构化的环境中导航是智能生物的特有的功能,想要实现远程导航,首先要对空间进行内部探索,然后要识别地标,同时还要有强大的视觉处理能力。基于最近将深度强化学习应用于迷宫导航的研究,DeepMind的研究人员也提出了一种端到端的深度强化学习方法,他们让智能体在真实的城市空间中导航,无需地图,并且这种方法还能迁移到不同城市环境。
导航是一项重要的认知任务,它能让人类和动物在没有地图的情况下,穿越过一片阡陌纵横的区域。这种远距离导航可以同时进行自我定位(我在这里)和目标表示(我要去那里)。
在Learning to Navigate in Cities Without a Map这篇论文里,我们展示了一种交互式导航环境,利用第一人称视角的谷歌街景照片做素材,将其游戏化以训练AI。标准的街景照片,人脸和车牌都被模糊,无法识别。我们建立了一个基于神经网络的智能体,学习使用视觉信息在多个城市中导航。注意,这项研究关注的是一般导航,而非驾驶导航;我们没有使用交通信息,也没有对车辆控制进行建模。
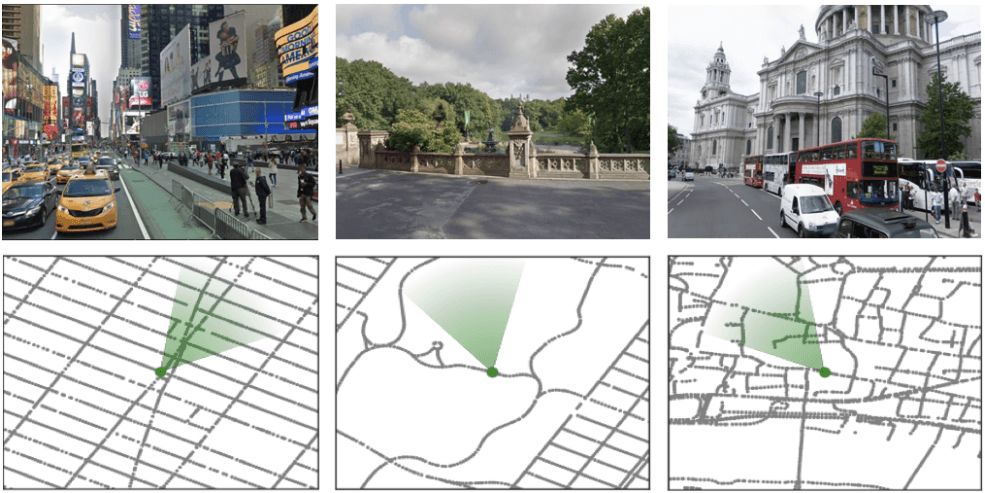
数据来源于真实街景。从左至右分别为纽约时代广场、中央公园和伦敦圣保罗大教堂
当智能体达到目的地时,它就会获得奖励(具体来说是一个经纬度坐标),就像一个没有地图的邮递员,要送无数的快递。随着时间的发展,智能体慢慢学会了用这种方法穿越整个城市。我们同样证明了智能体可以学习多个城市的道路,并且这种学习方法能有效迁移到新的城市中。
在没有地图的情况下学习导航
我们不使用传统的依赖外部映射和探索的传统方法,而是让智能体学习像人类一样导航,不用地图、GPS定位或其他辅助工具,只用视觉观察。我们创建了一个神经网络智能体,向其中输入在环境中观察到的图像,并预测它在该环境中执行的下一项操作。我们使用深度强化学习对其进行端到端训练,类似最近让智能体在复杂的3D迷宫中学习导航的研究,以及用无监督辅助方法玩游戏。与迷宫不同,我们利用真实的城市数据,例如伦敦、巴黎和纽约的复杂交叉路口、人行道、隧道和各种城市道路。此外,我们使用的方法可以迁移到不同城市,并可以优化导航行为。
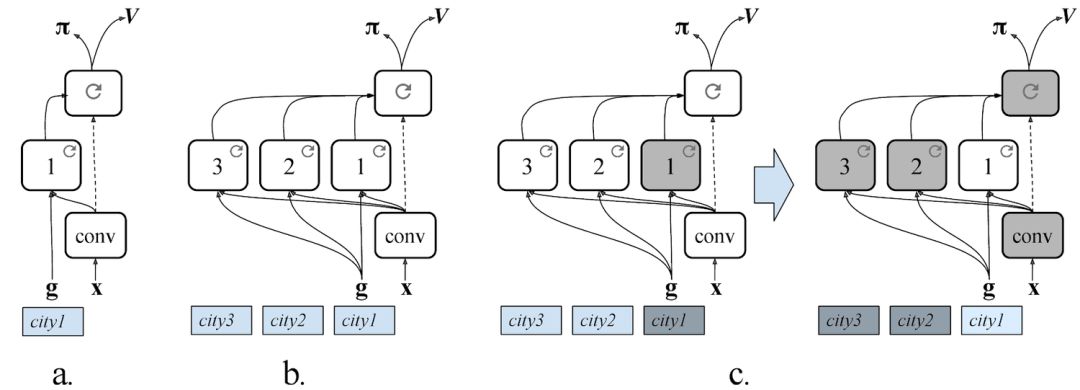
模块化神经网络
我们智能体的神经网络包括三个部分:
能够处理图像并提取视觉特征的卷积网络;
一个特定场所的循环神经网络,在内部进行对环境的记忆并学习表示“这里”(智能体的当前位置)和“那里”(目标位置);
一个位置不变的循环网络,能够根据智能体位置的变化进行导航。
特定场所的模块被设计成可互换的,并且正如其名,对于每个城市都是唯一的,而视觉模块和策略模块是不随着场景而变换的。
就像谷歌街景的界面一样,智能体可以在原地打转,也可以向前进入到下一个场景。但与谷歌地图和街景不同的是,智能体看不到小箭头、局部或全景地图以及标志性的街景小人,它还需要学习区分开放道路和人行道。目的地可能是几公里以外的地方,智能体需要搜索几百个全景图才能到达。
我们证明了这种方法能提供一种机制,将导航知识迁移到新城市中。和人类一样,当智能体来到一个新城市,我们会希望它学习一组新的地标,但不必重新学习它的视觉表现或行为(例如,沿着街道向前缩放,或者在交叉路口转向)。因此,使用MultiCity架构,我们在许多城市进行首次训练,然后冻结策略网络和视觉卷积网络,并在一个新城市中建立唯一一个新的特定地区路径。这种方法让智能体在获取新知识的同时不忘之前学到的东西,类似渐进式神经网络架构。
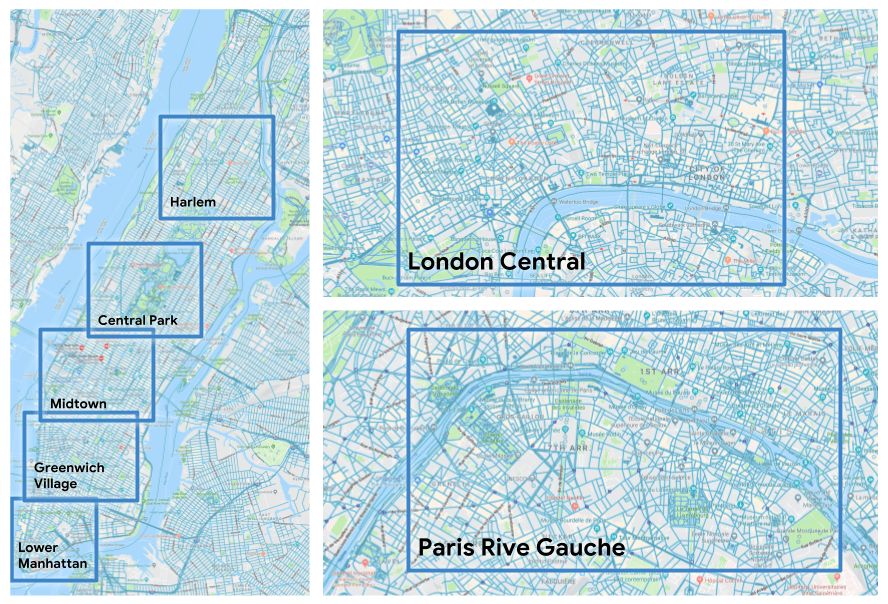
学习导航是人工智能领域的基础,试图在智能体中复制导航功能还可以帮助科学家了解其生物学基础。
-
神经网络
+关注
关注
42文章
4829浏览量
106897 -
导航
+关注
关注
7文章
570浏览量
43737 -
人工智能
+关注
关注
1813文章
49785浏览量
261932
原文标题:无需地图,DeepMind让智能体在城市中自我导航
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何训练好自动驾驶端到端模型?

中国研究发布新型混合微电网系统
今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
自动驾驶中常提的“强化学习”是个啥?

NVIDIA Isaac Lab可用环境与强化学习脚本使用指南

思岚科技AI工业机器人开放底盘Phoebus P350全新发布:深度学习导航+300KG负载

上海光机所在基于深度时空先验的动态定量相位成像研究方面取得进展
18个常用的强化学习算法整理:从基础方法到高级模型的理论技术与代码实现

详解RAD端到端强化学习后训练范式

SLAMTEC Aurora:把深度学习“卷”进机器人日常
军事应用中深度学习的挑战与机遇
BP神经网络与深度学习的关系
浅谈适用规模充电站的深度学习有序充电策略





 工商网监
工商网监
评论