 中科驭数高性能网卡产品 成就DeepSeek推理模型网络底座
中科驭数高性能网卡产品 成就DeepSeek推理模型网络底座

2025年初,DeepSeek-V3与DeepSeek-R1推理模型的开源引爆了AI社区,这两款产品作为通用千亿级模型与专用推理优化模型,为全球AI技术生态带来重大变革,不仅展示了中国AGI技术的突破性进展,而且开源模型发展带来部署成本的极速下降,为定制化AGI服务,推理本地化部署,带来发展机遇,也掀起了新的一轮智算基础设施建设浪潮。
与按Token生成数量计费的AI云服务模式不同,出于数据安全的考虑,很多用户选择采用本地化部署推理集群的方式将AI能力集成到当前业务流中。由于整个推理应用的业务链条非常长,本地化部署需要综合考虑如下各个方面与需求的匹配度:
硬件与基础设施规划:包括GPU与专用芯片选型、网络架构优化与隔离、存储方案评估
模型优化与部署策略:包括量化压缩等推理加速技术选型、资源动态调度技术等
安全与合规性:需要综合考虑数据使用的便捷性与合规要求
高可用与容灾设计:包括故障自愈方案、数据备份等
成本控制:根据业务使用模式合理制定需求规格,严控成本
为了更好地服务客户完成本地化推理集群的选型与部署工作,近期中科驭数作为国内AI网络的头部DPU芯片产品供应商,从网络选型对推理集群性能影响的角度出发,设计与执行了一系列实验并收集了翔实的一手材料数据。
本实验环境共采用了DeepSeek-R1-Distill-Qwen-32B未量化版本作为基础模型,基于vLLM搭建了推理集群,并采用evalscope对推理效果完成了评估。本次时延共使用了两台双GPU服务器,服务器基本配置如下:

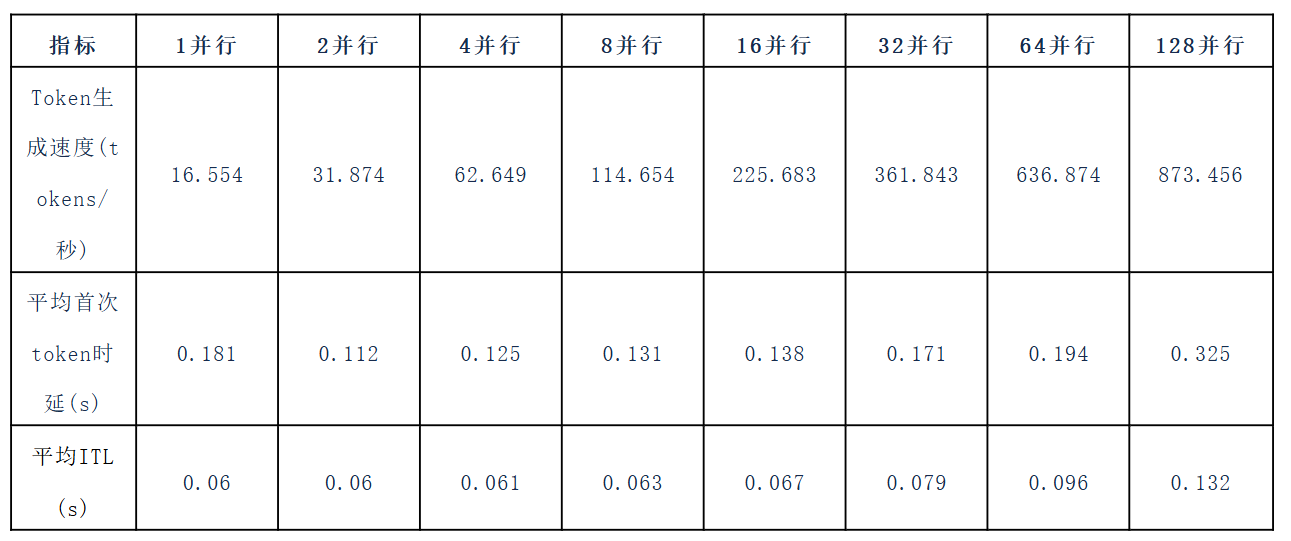
首先,我们关注采用TCP方式作为底层推理网络基础时,进行了如下测试:
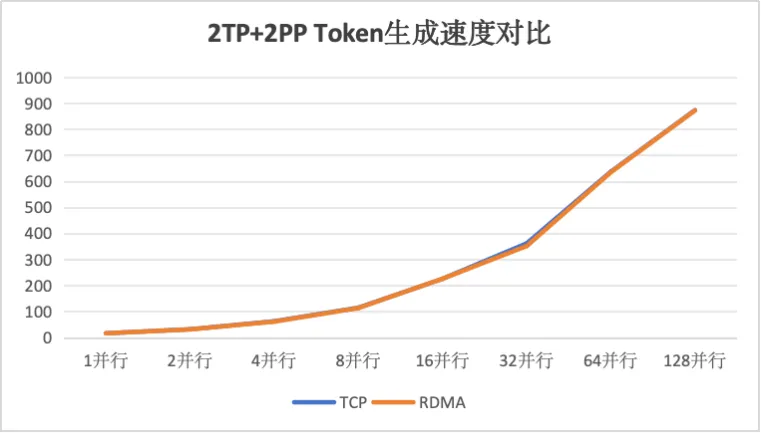
当采用2TP+2PP的模型切割方式时,获得了如下基础数据:
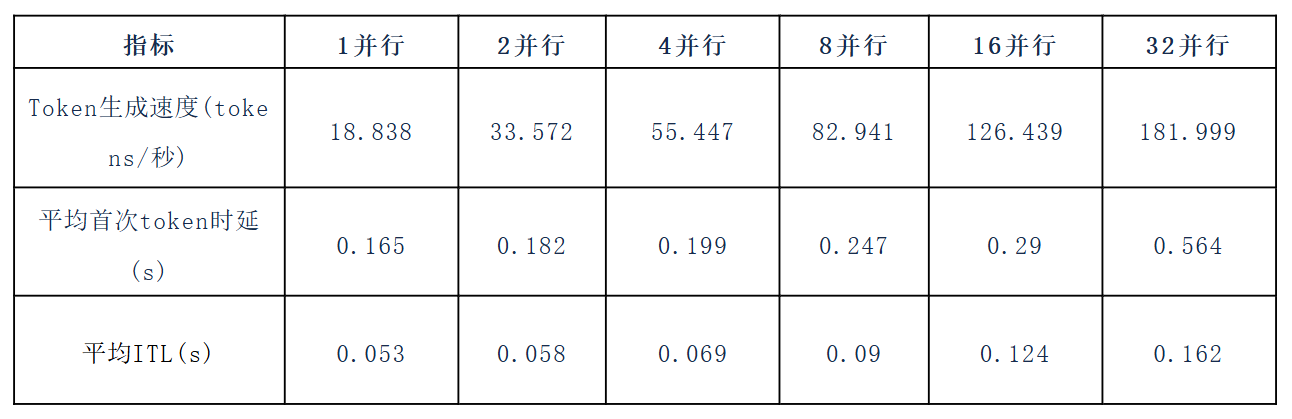
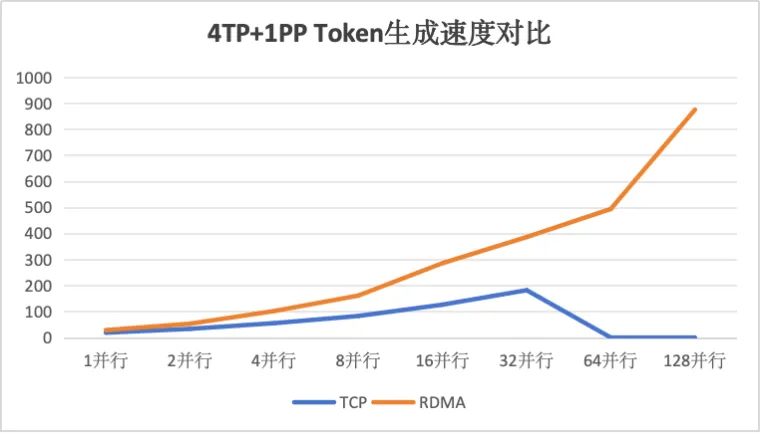
随后切换到4TP+1PP模型切割模式,加大了不同节点间的矩阵数据交换需求,得到如下数据:
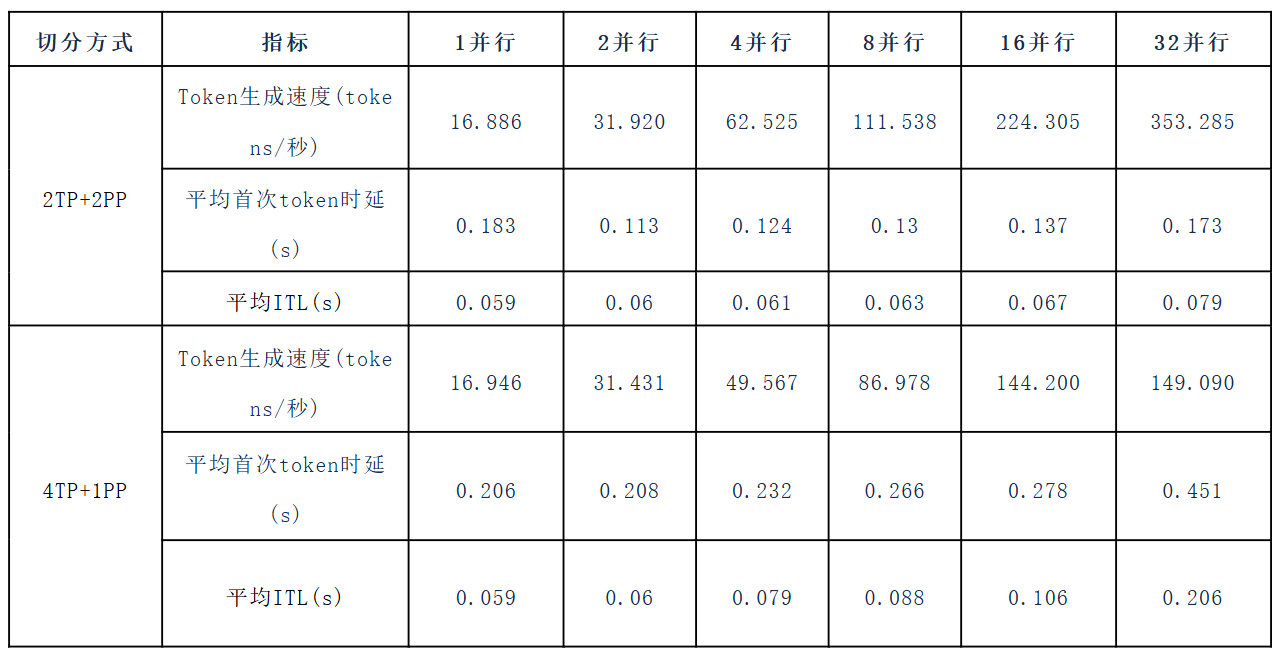
为了更好的体现测试数据的公平性,本测试随后选择行业领导企业的成熟网卡产品进行了实验,得出了基本一致的数据测试结果。并且在TCP模式下,中科驭数FlexFlow-2200T设备基本达到了与国际一线厂商相同的能力水平。
随后,本实验将底层基础网络技术切换为RDMA网络,进行了测试验证并收集到如下数据:
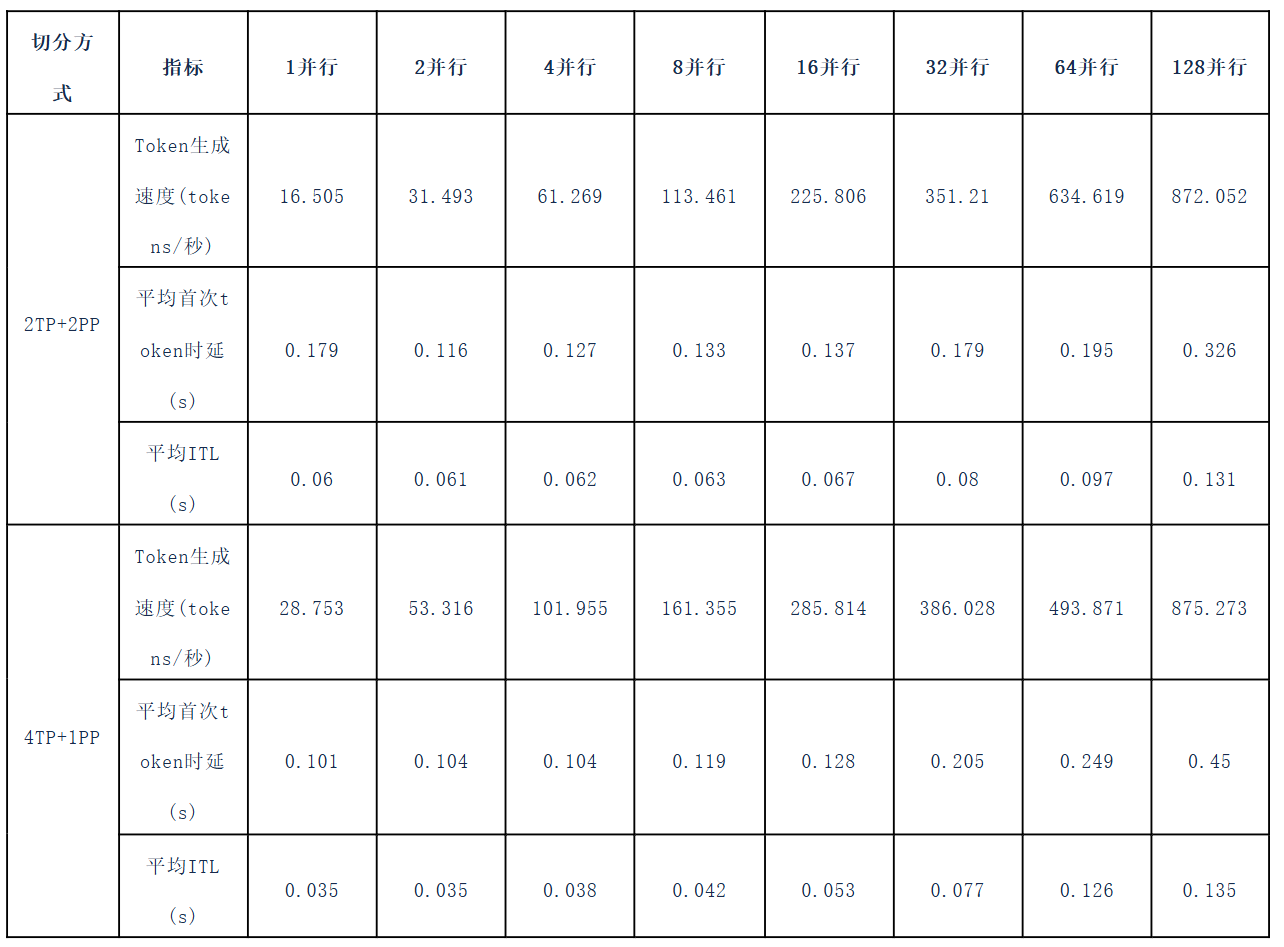
通过对比可以得知在模型进行良好切分设计的情况下,RDMA网络并未能提升整体推理性能,但是在节点间需要传递张量数据的情况下,RDMA网络可大幅提升模型推理性能,同时在大并发规模时,能够更好的保持推理集群的服务稳定性。
通过一系列的实验结果,我们可以得出如下结论:
一、良好的模型切分设计可以大幅提升模型性能,此时无需引入复杂的RDMA网络运维,即可获得最佳的推理性能体验,从而获得最高的投入产出比。
二、在单台服务器GPU算力受限,不得不在节点间进行张量切分时,可以使用RDMA网络保证推理模型的服务性能与稳定性。但是引入RDMA带来性能提升的同时,成本的提升比例也是一致的。大家可以按照实际应用场景,考虑多方因素后综合选择。

中科驭数的作为国内全品种网卡的研发企业,基于全自研、国产芯片K2-Pro打造的FlexFlow-2200T网卡,可以承担智算大模型的网络底座,为您的智算模型增加一颗“中国芯”。
审核编辑 黄宇
-
网卡
+关注
关注
4文章
346浏览量
29076 -
DPU
+关注
关注
0文章
417浏览量
27149 -
DeepSeek
+关注
关注
2文章
840浏览量
3406
发布评论请先 登录
阿里巴巴发布通义千问旗舰推理模型Qwen3-Max-Thinking

LLM推理模型是如何推理的?

彰显硬科技实力 中科驭数荣登VENTURE50硬科技榜 构建DPU“运力”底座
中科驭数西南总部落地成都天府新区
什么是AI模型的推理能力
NVIDIA Nemotron Nano 2推理模型发布

中科驭数亮相2025 CCF全国高性能计算学术大会
澎峰科技完成OpenAI最新开源推理模型适配
利用NVIDIA推理模型构建AI智能体

速看!EASY-EAI教你离线部署Deepseek R1大模型




评论