 AI MCU# GD32G553 TinyML 轻量级边缘 AI 应用的理想选择
AI MCU# GD32G553 TinyML 轻量级边缘 AI 应用的理想选择

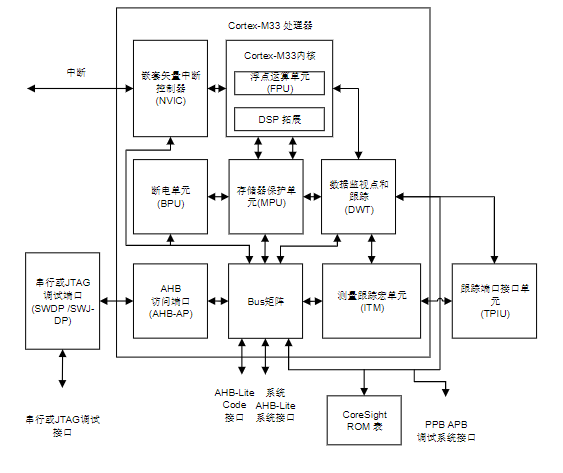
兆易创新GD32G5系列MCU采用Arm^®^ Cortex ^®^ -M33高性能内核,主频高达216MHz。内置高级DSP硬件加速器和单精度浮点单元(FPU);集成了硬件三角函数加速器(TMU),滤波算法(FAC)、快速傅里叶(FFT)等多类硬件加速单元,大幅提升处理效率。
GD32G5系列MCU配备了256KB到512KB嵌入式Flash,支持Flash双Bank功能;以及128KB SRAM,其中包含32KB紧耦合内存TCMRAM,实现关键指令与数据的零等待执行;还配备了高速缓存空间,高达2KB I-Cache及512B D-Cache,进一步提升内核处理性能。
- GD32G5系列MCU支持4个12位ADC采样速率高达5.3MSPS,具备高达42个通道;还支持4个12位DAC,其中2个采样率高达15MSPS;以及8个快速比较器(COMP)等一系列高精度模拟外设。
- GD32G5系列MCU配备了16通道高精度定时器(HRTimer),精度可达145ps;以及3个8通道高级定时器,2个32位通用定时器、5个16位通用定时器、2个16位基本定时器、1个低功耗定时器。
- 提供了包含5个U(S)ART、4个I2C、3个SPI以及1个QSPI,支持最高200MHz DDR/SDR接口;配备了3个CAN-FD模块,适用于高速通信应用场景;
- 还集成了1个HPDF高性能数字滤波器,支持8 Channels/4 Filter,外接Σ-Δ调制器;以及4个可配置逻辑模块(CLA);提供Trigsel模块支持灵活配置触发源。GD32G5全系列支持-40~105℃的宽温工作范围,能够满足光模块、工业电源、高速电机控制等对温度要求高的差异化场景。
- GD32G5系列MCU内置多种安全功能,为通信过程提供了包括支持安全OTA、安全启动、安全调试、安全升级等在内的多重安全保护机制。支持系统级IEC 61508 SIL2等级功能安全标准,提供完整的Safety Package,包括 Safety Manual、FMEDA及自检库等一系列功能安全资料。
可广泛适用于数字电源、充电桩、储能逆变、变频器、伺服电机、光通信等多元化场景。
GD32G553
- 采用Cortex®-M33内核,主频高达216MHz
存储容量支持512KB eFlash以及128KB SRAM
提供LQFP128/100/80/64/48, WLCSP81, QFN48封装选项
*附件:GD32G553数据手册.pdf
*附件:GD32G553用户手册.pdf
*附件:AN207 GD32G5x3 三角函数加速器TMU的使用说明.pdf
*附件:AN193 GD32G5xx系列硬件开发指南_Rev1.2.pdf
GD32G553 与 TinyML 的适配性及实现方案
GD32G553 虽非专为 TinyML 设计,但其硬件架构与算力特性使其成为轻量级边缘 AI 应用的理想选择。以下是其支持 TinyML 的关键能力与实现路径:
- 硬件加速单元优化模型推理效率
DSP 加速器与 FPU:支持矩阵运算、激活函数等基础 ML 操作加速,降低算法延迟。
TMU(硬件三角函数加速器):加速 Sin/Cos/Tan 等函数运算,适配信号处理类模型(如振动分析、语音识别)。
FFT 加速单元:优化频域特征提取,适用于传感器数据预处理(如电机状态监测)。 - 存储与缓存设计适配轻量级模型
512KB eFlash:可存储 TinyML 模型参数(如 TensorFlow Lite 量化后的低比特模型)。
32KB TCM RAM + 128KB SRAM:实现实时数据缓存与零等待指令执行,满足低延迟推理需求。
I-Cache/D-Cache:提升数据吞吐效率,减少模型推理过程中的内存瓶颈。 - 高精度传感器接口支持数据采集
4 个 12 位 ADC(5.3MSPS):支持多通道传感器信号同步采集(如电流/电压/温度),为模型输入提供高质量数据。
16 通道 HRTimer(145ps 精度):实现精确时序控制,适配实时反馈型 AI 应用(如动态电源调节)。 - 安全与扩展性保障
加密加速单元(CAU):保护模型参数与推理数据的安全性,防止边缘侧篡改。
EXMC 接口:支持扩展外部存储器(如 QSPI NOR Flash),部署更大规模模型。 - 典型 TinyML 应用场景
工业预测性维护:通过振动传感器数据训练异常检测模型,本地实时识别设备故障。
智能能源管理:结合 ADC 采集与 HRTimer 控制,实现基于负载预测的动态能效优化。
光通信模块监控:利用 FFT 加速器分析光信号频谱,快速定位链路异常。
开发建议
模型优化:优先采用量化(INT8)与剪枝技术,压缩模型体积以适应 512KB Flash 限制。
工具链适配:利用 GD32 SDK 集成 TensorFlow Lite Micro 或 MicroTVM 框架,简化部署流程。
能效平衡:通过 HRTimer 动态调节 MCU 工作频率,降低推理功耗(典型场景功耗可降低 30%)。
GD32G553 通过高性能计算单元与低延迟外设的协同,为 TinyML 提供了高性价比的边缘部署方案,尤其适合工业控制与能源管理领域的实时智能需求。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
发布评论请先 登录
相关推荐
热点推荐
AI大模型小龙虾-OpenClaw-0基础从入门到实战
知识库搭建、创意快速变现以及轻量级流程自动化这四大高频适用场景。它放弃了底层的学术自嗨,选择站在普通用户和业务需求的这边。对于零基础学习者而言,选择 OpenClaw,不是选择了一条成
发表于 05-06 16:04
论马斯克的预言:AI使人类边缘化
当地时间3月11日,在“Abundance Summit”科技峰会上,马斯克谈及AI进展时表示,AI已经进入自我改进阶段,在超高量级AI面前,人类终将走向
发表于 03-14 05:27
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
检索。
这一组合带来了高达176TOPS的整型AI算力(INT8)。在AI硬件行业中,算力决定了应用的天花板:
算力区间
典型应用场景
设备形态
10-40 TOPS
单路视觉识别、轻量级语音控制
物
发表于 03-10 14:19
直播有礼 | 瑞萨边缘AI线上技术月——AI MCU/MPU产品及边缘AI案例集
RA生态工作室关注我们随着人工智能技术不断迭代,使用远端算力平台进行模型部署和AI计算并在端侧决策成为可能,边缘AI技术凭借实时响应、低资源消耗、高安全性和私密性优势正引领嵌入式开发变革。瑞萨电子


瑞芯微SOC智能视觉AI处理器
。B2版本通常在功耗、稳定性和部分外围接口支持上有所优化。NPU: 集成0.8 TOPS的NPU,支持INT8/INT16混合运算,能满足大多数边缘侧的轻量级AI推理需求(如分类、检测、识别)。多媒体
发表于 12-19 13:44
5G RedCap加速边缘AI革命:智能穿戴与AI眼镜迎来“直连云端”新时代
RedCap作为新一代轻量级5G标准的到来,正成为推动智能穿戴、AI眼镜等边缘设备实现高性能、低成本、低功耗连接的关键技术。 5G R

【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
景嘉微电子、海光信息技术、上海复旦微电子、上海壁仞科技、上海燧原科技、上海天数智芯半导体、墨芯人工智能、沐曦集成电路等。
在介绍完这些云端数据中心的AI芯片之后,还为我们介绍了边缘AI芯片。
云端
发表于 09-12 16:07
AI 边缘计算网关:开启智能新时代的钥匙—龙兴物联
在数字化浪潮的当下,AI 边缘计算网关正逐渐崭露头角,成为众多行业转型升级的关键力量。它宛如一座智能桥梁,一端紧密连接着各类物理设备,如传感器、摄像头、工业机器等,负责收集丰富的数据信息;另一端则
发表于 08-09 16:40
基于米尔瑞芯微RK3576开发板部署运行TinyMaix:超轻量级推理框架
本文将介绍基于米尔电子MYD-LR3576开发平台部署超轻量级推理框架方案:TinyMaix
摘自优秀创作者-短笛君
TinyMaix 是面向单片机的超轻量级的神经网络推理库,即 TinyML
发表于 07-25 16:35
如何在RK3576开发板上运行TinyMaix :超轻量级推理框架--基于米尔MYD-LR3576开发板
本文将介绍基于米尔电子MYD-LR3576开发平台部署超轻量级推理框架方案:TinyMaix摘自优秀创作者-短笛君TinyMaix是面向单片机的超轻量级的神经网络推理库,即TinyML推理库,可以

兆易创新GD32H7系列MCU解锁边缘AI新玩法
在万物互联向万物智联跃迁的时代,边缘计算正面临前所未有的性能挑战。传统MCU难以承载复杂的AI算法,而云端方案又受限于实时性和隐私问题。兆易创新GD32H7系列应势而生,以600MHz
Nordic收购 Neuton.AI 关于产品技术的分析
Nordic Semiconductor 于 2025 年收购了 Neuton.AI,这是一家专注于超小型机器学习(TinyML)解决方案的公司。
Neuton 开发了一种独特的神经网络框架,能够
发表于 06-28 14:18
边缘AI实现的核心环节:硬件选择和模型部署
边缘AI的实现原理是将人工智能算法和模型部署到靠近数据源的边缘设备上,使这些设备能够在本地进行数据处理、分析和决策,而无需将数据传输到远程的云端服务器。边缘




评论