 在 48GB 显卡上仅用 12 小时重现DeepSeek“Wait!/Aha”时刻
在 48GB 显卡上仅用 12 小时重现DeepSeek“Wait!/Aha”时刻

作者:算力魔方创始人/英特尔创新大使刘力
近日,荷兰科学家Raz发布了Reinforce-Lite算法,实现了在 48GB显存的显卡上仅用 12 小时在3B模型上重现DeepSeek“Wait!/Aha”时刻。
原文链接:https://medium.com/@rjusnba/overnight-end-to-end-rl-training-a-3b-model-on-a-grade-school-math-dataset-leads-to-reasoning-df61410c04c6
滑动查看更多
一,Reinforce-Lite算法的显存要求
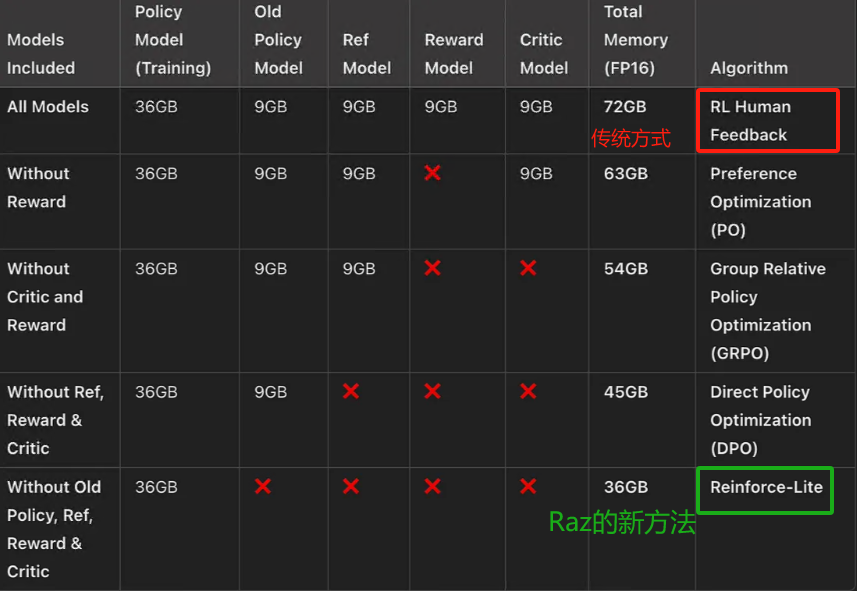
Raz通过移除KL,移除替代比率,去掉评论模型,使用组相对奖励(DeepSeek的GRPO风格)进行优势计算,提出了一种更简单、更稳定、更高效的轻量级强化学习方法:Reinforce-Lite,使得显存需求,从72GB下降到36GB!下表是:端到端的用强化学习训练 3B 模型的显存需求。
二,Reinforce-Lite算法的PyTorch实现
Reinforce-lite算法的PyTorch实现如下所示:
第一步,初始化一个指令微调的LLM,并适当提示以将其推理步骤包含在标签中。
第二步,定义一个奖励函数用于模型输出(例如,GSM8K数学推理任务中的正确性)。通过正则表达式提取标签中的数值,并与数据集中的实际答案进行比较。
第三步,通过直接计算相对于奖励的梯度来优化策略,而不需要替代损失。
第四步,使用组相对归一化进行优势计算,消除了对评论模型的需求。我们使用组大小为10。
第五步,使用标准对数概率梯度更新模型。
def reinforce_lite(batch, policy_model, tokenizer, device, step, save_dir):
"""
使用强化学习方法训练策略模型。
Args:
batch (list of tuples): 包含提示和目标句子的列表。
policy_model (torch.nn.Module): 策略模型,用于生成响应。
tokenizer (transformers.PreTrainedTokenizer): 用于处理文本的标记器。
device (torch.device): 指定模型运行的设备。
step (int): 当前训练步数。
save_dir (str): 保存模型的目录。
Returns:
tuple: 包含策略损失、平均奖励、策略损失项、0.0、第一个响应和所有响应的长度。
"""
# 设置模型为训练模式
policy_model.train()
# 解包输入数据
prompts, targets = zip(*batch)
# 获取批量大小
batch_size = len(prompts)
# 初始化评估组索引
evaluated_group = 0
# 初始化存储列表
all_logprobs = []
all_rewards = []
all_responses = []
all_lengths = []
for group_idx in range(config.GROUP_SIZE):
# 格式化提示
formatted_prompts = [format_prompt(p, tokenizer) for p in prompts]
# 将提示转换为模型输入
inputs = tokenizer(
formatted_prompts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=config.MAX_SEQ_LENGTH
).to(device)
# 生成参数
generate_kwargs = {
**inputs,
"max_new_tokens": config.MAX_NEW_TOKENS,
"do_sample": True,
"temperature": 0.7,
"top_p": 0.9,
"pad_token_id": tokenizer.pad_token_id,
"return_dict_in_generate": True,
}
# 判断当前组是否为评估组
if group_idx == evaluated_group:
# 生成响应
generated = policy_model.generate(**generate_kwargs)
# 获取生成的响应ID
generated_ids = generated.sequences
# 获取模型输出
outputs = policy_model(
generated_ids,
attention_mask=(generated_ids != tokenizer.pad_token_id).long()
)
# 获取提示长度和响应长度
prompt_length = inputs.input_ids.shape[1]
response_length = generated_ids.shape[1] - prompt_length
# 计算对数概率
if response_length > 0:
logits = outputs.logits[:, prompt_length-1:-1, :]
response_tokens = generated_ids[:, prompt_length:]
log_probs = torch.log_softmax(logits, dim=-1)
token_log_probs = torch.gather(log_probs, -1, response_tokens.unsqueeze(-1)).squeeze(-1)
sequence_log_probs = token_log_probs.sum(dim=1)
else:
sequence_log_probs = torch.zeros(batch_size, device=device)
else:
# 在不计算梯度的情况下生成响应
with torch.no_grad():
generated = policy_model.generate(**generate_kwargs)
sequence_log_probs = torch.zeros(batch_size, device=device)
# 解码生成的响应
responses = tokenizer.batch_decode(
generated.sequences[:, inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
# 计算奖励
rewards = torch.tensor([get_reward(resp, tgt) for resp, tgt in zip(responses, targets)], device=device)
# 存储结果
all_responses.extend(responses)
all_rewards.append(rewards)
all_logprobs.append(sequence_log_probs)
all_lengths.extend([len(r.split()) for r in responses])
# 堆叠奖励和对数概率
rewards_tensor = torch.stack(all_rewards)
logprobs_tensor = torch.stack(all_logprobs)
# 分离评估组的奖励和其他组的奖励
evaluated_rewards = rewards_tensor[evaluated_group]
others_rewards = torch.cat([
rewards_tensor[:evaluated_group],
rewards_tensor[evaluated_group+1:]
], dim=0)
# 计算基线值
baseline = others_rewards.mean(dim=0)
# 计算优势
advantages = (evaluated_rewards - baseline) / (others_rewards.std(dim=0) + 1e-8)
advantages = torch.clamp(advantages, -2.0, 2.0)
# 计算策略损失
policy_loss = -(logprobs_tensor[evaluated_group] * advantages.detach()).mean()
return policy_loss, rewards_tensor.mean().item(), policy_loss.item(), 0.0, all_responses[0], all_lengths
滑动查看更多
三,Reinforce-Lite算法的数据集:GSM 8K
Reinforce-Lite使用GSM8K数据集:这是一个小学数学数据集,包含数学问题及其答案,格式如下:
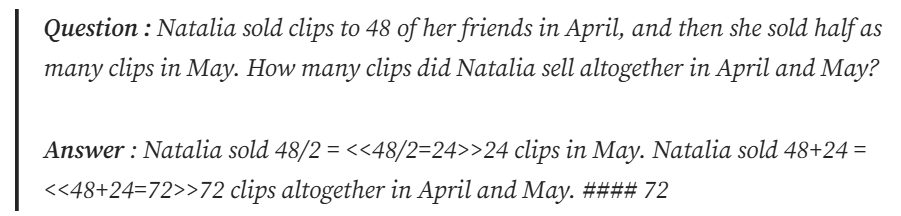
虽然答案也涉及推理步骤,但我们感兴趣的是 ### 之后的最终答案。我们将简单地提示策略模型以 格式输出最终答案,并使用它来验证策略模型计算出的答案是否正确。这更像是蒙特卡洛问题,我们会在情节结束时获得奖励。
Reinforce-Lite的完整实现方式和训练过程,Raz将很快开源!敬请期待。
四,DeepSeek:快速生成PPT大纲
Reinforce-Lite 改进了结构化推理:从生成的序列中我们可以看到 RL 微调模型,评估分数略有提高。
Reinforce-Lite 不需要 PPO 的复杂性:单个策略网络足以进行 LLM 微调。
Reinforce-Lite 是一种计算友好的算法,允许端到端 RL 训练,同时最大限度地降低训练复杂性和显存的需求,让AI平权的时代可尽快到来。
人人都能在自己的48GB显存显卡上,重现DeepSeek“Wait!/Aha”时刻!另外,需要48GB显存的显卡,请联系我们!
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
-
显卡
+关注
关注
17文章
2523浏览量
71716 -
AI
+关注
关注
91文章
41060浏览量
302571 -
DeepSeek
+关注
关注
2文章
837浏览量
3396
发布评论请先 登录
【实测】用全志A733平板搭建一个端侧Deepseek算力平台
HarmonyOS NEXT开发实战:DevEco Studio中DeepSeek的使用
NVIDIA不放弃12nm图灵显卡,将推出8GB版RTX 2060
曝NVIDIA将推出RTX 2060显卡的8GB显存版 仍不放弃12nm图灵显卡
RTX 3080 20GB显卡复活本月即将上市
英伟达正式发布RTX 3060 显卡:12GB 显存
微星推出面向Mini-ITX主机/主板的RTX 3060 12GB显卡
NVIDIA推出了RTX 3060显卡 12GB显存超过RTX 3080
NVIDIA正式宣布其基于Ampere GPU架构的GeForce RTX 3060 12 GB显卡
新型DDR5内存的应用
SK海力士推出48GB 16层HBM3E产品
英特尔2025上半年将推24GB显存锐炫B580显卡
DeepSeek在昇腾上的模型部署的常见问题及解决方案
铭瑄在COMPUTEX 2025上发布Intel Arc Pro B60 Dual 48G Turbo显卡




评论