 deepseek国产芯片加速 DeepSeek的国产AI芯片天团
deepseek国产芯片加速 DeepSeek的国产AI芯片天团

遥想两年前,ChatGPT给了世界一记AI冲击,而DeepSeek无疑是第二记冲击。我们不仅对DeepSeek强劲的性能所震撼,也让远在大洋彼岸的OpenAI、谷歌、META等一众玩家感受到莫大压力,从而纷纷继续“卷”起来,效仿DeepSeek的“开源”模式。
对于DeepSeek本身,人们关注其如何在有限算力实现强大性能,更关注其在重重条令围城之下的未来之路。而在最近,全世界的芯片厂商集体出动,纷纷宣布支持DeepSeek。尤其是众多国产AI芯片厂商,集体发力,为DeepSeek建立了一个坚实的后盾。
缘起:DeepSeek成功背后
为什么DeepSeek能够掀起如此巨浪?因为令人惊讶的是,目前普遍认为DeepSeek仅仅用了550万美元的成本实现了openAI上亿美元做到的事。总结起来,DeepSeek有四点创新:
第一,拉低整体成本。信息显示,DeepSeek V3模型的训练总计耗用278.8万GPU小时,相当于在2048块H800 GPU集群上训练约2个月,成本为557.6万美元。相比之下,GPT-4o的训练成本约为1亿美元,需使用上万块性能更强的H100 GPU。同时,DeepSeek V3的成本仅为Llama 3的7%。AI专家指出,达到DeepSeek V3级别的能力需接近16000颗GPU的集群。
之所以有很低的成本,是DeepSeek的模型架构与主流设计有所不同,采用了细颗粒度的MoE(混合专家)结构。虽然细颗粒度MoE并非首创,例如阿里也在探索这一方向,但DeepSeek通过这一架构在推理时仅激活部分参数,从而显著降低成本。此外,DeepSeek在推理机制中引入了LLA,与市场上常见的多头注意力机制不同,后者需要所有参数参与计算,而DeepSeek仅激活少量参数,进一步提升了效率。当前先进模型大多采用邓氏架构,而DeepSeek的创新在于通过细颗粒度MoE和LLA实现了更高效的推理。
第二,训练方法。传统方法为FP32和FP16的混合精度,DeepSeek则采用FP8参数,比较敏感的组件还是FP16。分布式混合精度目前做的比较少,训练方法里面也有工程优化,之前时延导致GPU利用率不是很高,DeepSeek用流水线并行,高效利用通信网络,提升速率。
第三,编程不同。DeepSeek采用了NVIDIA PTX指令集(Parallel Thread Execution ISA)来提升执行效能。PTX是NVIDIA GPU最底层的控制语言,用更细颗粒度来调度底层单元,将硬件调度细化。不过,此处需要注意PTX并非是CUDA的替代品,对于大部分开发者来说学习门槛较高,所以才有了CUDA来简化开发过程。
第四,AI Infra,通常集群是三层网络,DeepSeek是两层,通信库降低PCIe消耗,减少GPU内存消耗增高网络通信速度,HF Reduce、分布式文件系统、调度平台用得比较灵活。
虽说在各种突破之下,DeepSeek的表现惊人。但对大多数用户来说,也许更多的体验是“服务器繁忙,请稍后再试”,除了国外对于DeepSeek的攻击以外,也许DeepSeek的算力真的不够用了。
根据国泰君安证券分析师舒迪、李奇测算,假设DeepSeek日均访问量为1亿次、每次提问10次,每次提问的回复用到1000个token,1000个token大概对应750个英文字母,则DeepSeek每秒的推理算力需求为1.6*1019TOPs。在这种普通推理情境下,假设DeepSeek采用的是FP8精度的H100卡做推理,利用率50%,那么推理端H100卡的需求为16177张,A100卡的需求为51282张。
这种情况下,AI芯片就显得格外重要了。
后盾:国产芯片撑起一片天
事实上,芯片算力一直都在追着大模型奔跑。换句话说,未来算力需求一定难以满足现在AI发展,DeepSeek未来会面对
据OpenAI测算,自2012年以来,AI模型训练算力需求每3~4个月就翻一番,每年训练AI模型所需算力增长幅度高达10倍。而连摩尔定律中,芯片计算性能翻一番的周期为18~24个月,更何况摩尔定律已经出现放缓迹象。专家预测,未来几年OpenAI仅训练模型⾄少还需要200~300亿美元的硬件,Google需要200-300亿美元,Anthropic需要100-200亿美元,未来几年至少投入1000亿美元纯粹用到训练⼤模型。
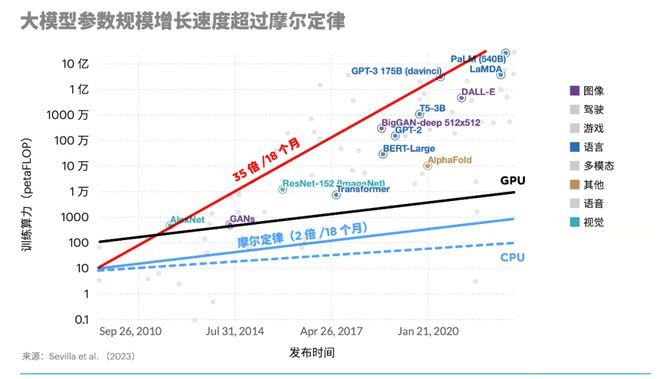
芯片厂商当然没有错过DeepSeek这一机会,比如在春节期间,国外芯片厂商接连宣布支持DeepSeek:
1月25日,AMD将DeepSeek-V3模型集成于Instinct MI300X GPU;
1月31日,NVIDIA NIM微服务预览版支持DeepSeek-R1模型英伟达;
1月31日,英特尔DeepSeek模型能在酷睿AIPC上离线使用;
2月1日,英特尔Gaudi 2D Al加速器支持DeepSeek Janus Pro模型。
自从AI大模型来了,英伟达喝汤喝到撑,GPU也就成了香饽饽。但在地缘政治局势愈发紧张的现如今,国内高端AI芯片不断被围追堵截。因此,自主可控成了不可不谈的问题。近几日,DeepSeek获国产芯片厂商力挺,成为支撑DeepSeek的“天团”。
1.华为:华为云宣布与硅基流动联合首发并上线基于华为云昇腾云服务的DeepSeek R1/V3推理服务;DeepSeek-R1、DeepSeek-V3、DeepSeek-V2、Janus-Pro正式上线昇腾社区;华为DCS AI全栈解决方案中的重要产品—ModelEngine,全面支持DeepSeek大模型R1&V3和蒸馏系列模型的本地部署与优化,加速客户AI应用快速落地;
2.沐曦:Gitee AI联合沐曦首发全套DeepSeek R1千问蒸馏模型,全免费体验;DeepSeek-V3满血版在国产沐曦GPU首发体验上线;
3.天数智芯:成功完成与 DeepSeek R1 的适配工作,并且已正式上线多款大模型服务,其中包括DeepSeek R1-Distill-Qwen-1.5B、DeepSeek R1-Distill-Qwen-7B、DeepSeek R1-Distill-Qwen-14B等;
4.摩尔线程:基于Ollama开源框架,完成了对DeepSeek-R1-Distill-Qwen-7B蒸馏模型的部署,并在多种中文任务中展现了优异的性能;
5.海光信息:DeepSeek V3和R1模型完成海光DCU适配并正式上线;海光DCU成功适配DeepSeek-Janus-Pro多模态大模型;
6.壁仞科技:DeepSeek R1在壁仞国产AI算力平台发布,全系列模型一站式赋能开发者创新;
7.太初元碁:基于太初T100加速卡2小时适配DeepSeek-R1系列模型,一键体验,免费API服务;
8.云天励飞:完成 DeepEdge10 “算力积木”芯片平台与DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B大模型的适配,可以交付客户使用;
9.燧原科技:完成对DeepSeek全量模型的高效适配,包括DeepSeek-R1/V3 671B原生模型、DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B、DeepSeek R1-Distill-Llama-8B/70B等蒸馏模型。截至目前,DeepSeek的全量模型已在庆阳、无锡、成都等智算中心完成了数万卡的快速部署;
10.昆仑芯:完成全版本模型适配,这其中包括DeepSeek MoE 模型及其蒸馏的Llama/Qwen等小规模dense模型;
11.灵汐芯片:完成了DeepSeek-R1系列模型在灵汐KA200芯片及相关智算卡的适配,助力国产大模型与类脑智能硬件系统的深度融合;
12.鲲云科技:全新一代的可重构数据流AI芯片CAISA 430成功适配DeepSeek R1蒸馏模型推理;
13.希姆计算:仅用数小时就将DeepSeek-R1全系列蒸馏模型快速适配到自研RISC-V开源指令集的推理加速卡系列之上,并落地全国多个千卡级以上智算中心;
14.算能:算能自研RISC-V开源指令集融合服务器SRM1-20,成功适配并本地部署DeepSeek-R1-Distill-Qwen-7B/1.5B模型;
15.清微智能:可重构计算架构RPU芯片已完成DeepSeek-R1系列模型的适配和部署运行;
16.龙芯中科:搭载龙芯3号CPU的设备成功启动运行DeepSeek R1 7B模型,实现本地化部署;
17.瀚博:已完成DeepSeek-V3与R1全系列模型训推适配,单机可支持V3与R1 671B全量满血版模型部署。
复盘:国产AI芯片发展现状
前两年,美国千方百计阻止英伟达向中国出售尖端AI芯片,不想放弃中国市场的英伟达,迅速推出中国特供版,但对国内来说,却不香了。所谓中国特供芯片,性能砍了25%,但减量不减价,国产厂商则纷纷点名华为,尤其是华为升腾910B芯片。那么,除了华为,我国还有哪些AI芯片企业值得关注?
AI芯片主要分为GPGPU(通用图形处理器)、FPGA(可编程逻辑器件)、ASIC(专用集成电路)、存算一体和类脑芯片几种。根据在网络中的位置,又可以分为云端AI芯片 、边缘和终端AI芯片。
GPU/GPGPU:与GPU不同,GPGPU就是将GPU图形显示部分“摘掉”,全力走通用计算,特别适合用在深度学习训练方面。目前国内GPU存在许多玩家,整个行业也经历过一轮洗牌。
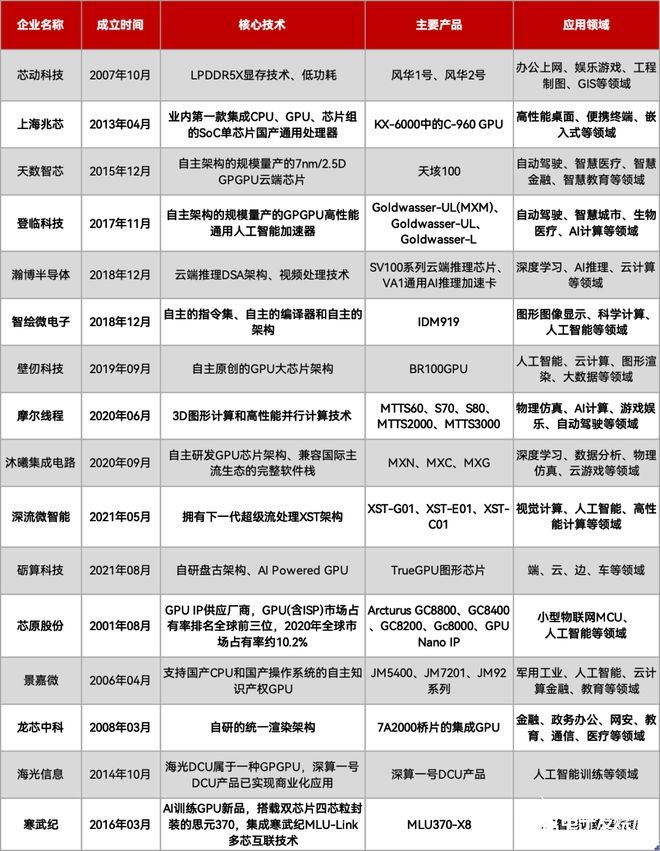
FPGA:可编程的灵活性是任何其它计算芯片无法替代的,同时它在AI领域也具备一定计算能力,但相对来说,FPGA的成本就相对高一些了,而且FPGA开发也很难,软件生态没有GPGPU的CUDA那么方便。
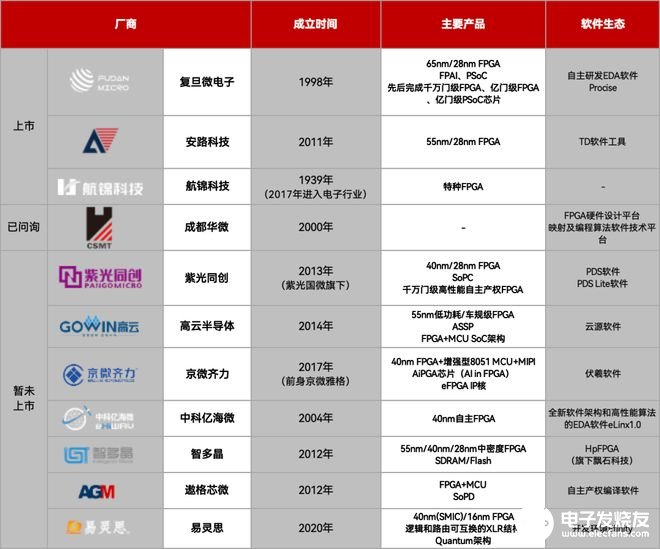
ASIC:性能强、功耗低,NPU也是加入神经单元的一种ASIC,不过针对特定算法计算,算法是无法修改的,想要做另一种算法就要再造一种ASIC芯片,前期开发需要FPGA辅助进行。
值得一提的是,TPU,全称Tensor Processing Unit,是一种专为处理张量运算而设计的ASIC芯片,由谷歌自研在2016年推出首款产品,目前国内也有中昊芯英这一玩家。
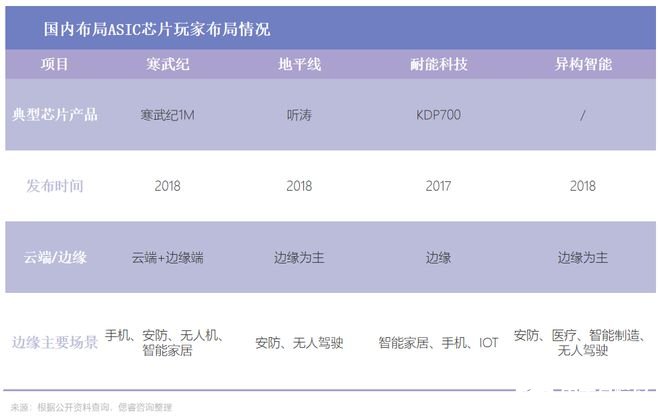
存算一体:能耗比极佳,能够突破存储墙和功耗墙,但商业化进程加速了,而且据说ST也准备在未来发布具有存算一体芯片的MCU。
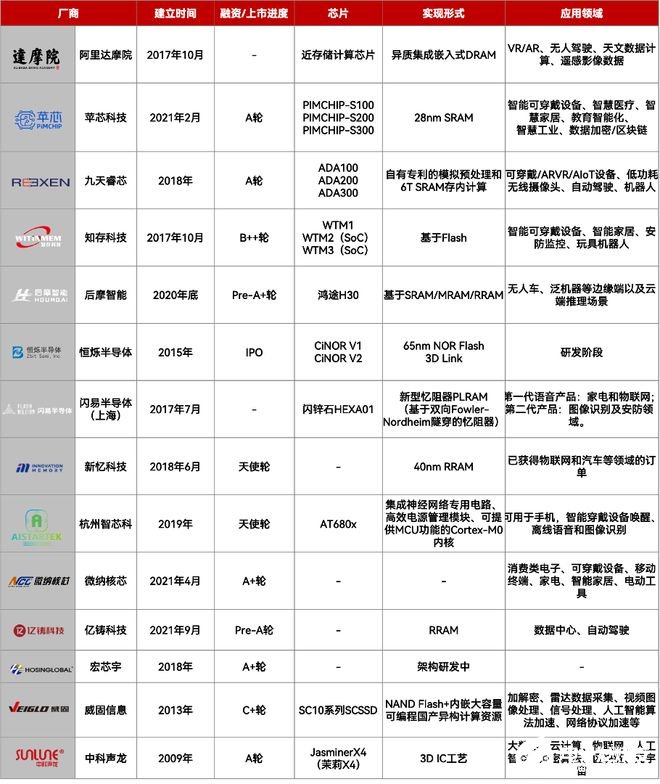
类脑计算:性能更强、功耗更低,算法也变成了SNN,但全世界都在研究之中,还未商业化。
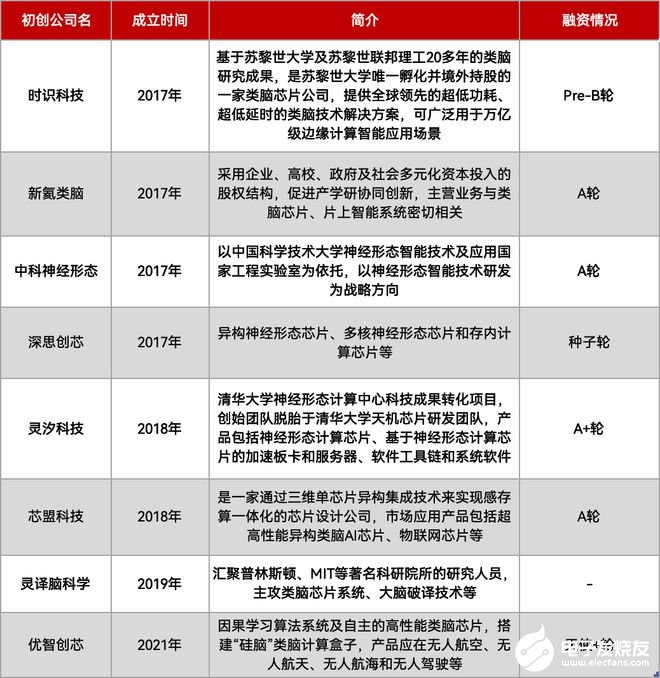
可重构计算:能够重新配置的数据流处理器架构,专为特定用例量身定制,可在其“计算结构”上并行执行经过特殊优化的代码。特别是在低功耗嵌入式和边缘计算中,并且需要支持通用编程语言的专有软件堆栈(编译器)。
目前,可重构计算的玩家包括清微智能、鲲云科技、千芯科技、澜起科技。(可参考文章:《》)
融合:千行百业正在被重塑
DeepSeek诞生的本身,也在促进着国内所有行业的发展,形成了一个循环的产业链。千行百业,正在因为DeepSeek而重塑,各行各业也不断支持DeepSeek。
1.汽车产业:吉利汽车、东风汽车、东风旗下岚图汽车等均宣布了接入DeepSeek,大模型“上车”已经成为大趋势;
2.手机:华为系统级智能体小艺在HarmonyOS NEXT(原生鸿蒙)上接入了DeepSeek最新的R1模型,OPPO Find N5也将接入DeepSeek;
3.云计算:阿里云、百度智能云、腾讯云、华为云已经官宣支持 DeepSeek大模型;
4.教育应用:网易有道、云学堂均宣布全面拥抱DeepSeek-R1;
5.网络安全:360、奇安信、启明星辰、安恒、北信源、天融信、国投智能、安博通、永信至诚、亚信、拓尔思、观安信息均宣布接入DeepSeek;
6.生物医药:恒瑞医药、医渡科技、智云健康、豫资开勒均宣布了DeepSeek的接入与部署;
7.电信运营商:三大运营商中国移动、联通、电信全面宣布接入DeepSeek;
8.软件公司:远光软件、安恒信息、当虹科技、万兴科技、金慧软件接入DeepSeek模型。
总之,DeepSeek作为一次“全民狂欢”,其意义非凡。为了契合这个话题,我们也问了DeepSeek自己对于自己诞生的意义,它的回答是:DeepSeek的诞生不仅是技术上的突破,更是对AI未来形态的积极探索。它通过开源共享、垂直应用和AGI愿景,推动AI从“工具”向“伙伴”演进,同时助力中国在全球AI竞争中占据更重要的战略地位。其意义不仅限于商业成功,更在于为人类与AI共生的未来提供了一种可能性。
作者:EEWorld电子工程世界 付斌 在此特别鸣谢!
-
国产芯片
+关注
关注
2文章
399浏览量
31862 -
AI芯片
+关注
关注
17文章
2165浏览量
36869 -
算力
+关注
关注
2文章
1676浏览量
16833 -
DeepSeek
+关注
关注
2文章
839浏览量
3406
发布评论请先 登录
DeepSeek V3.1发布!拥抱国产算力芯片

国产AI算力:从DeepSeek V4与华为昇腾协同看全栈自主之路

成都汇阳投资关于国产开源模型持续突破,国产AI 竞争力增强
曙光AI超集群系统全面支持DeepSeek-V3.2-Exp
速看!EASY-EAI教你离线部署Deepseek R1大模型

【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
【「DeepSeek 核心技术揭秘」阅读体验】--全书概览
【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
AI驱动连接器赛道,材料界“DeepSeek”加速国产化
【书籍评测活动NO.62】一本书读懂 DeepSeek 全家桶核心技术:DeepSeek 核心技术揭秘




评论