 Hadoop 生态系统在大数据处理中的应用与实践
Hadoop 生态系统在大数据处理中的应用与实践

随着数据量的爆发式增长,大数据处理技术成为企业关注焦点,Hadoop 生态系统在其中扮演着核心角色。
Hadoop Distributed File System(HDFS)是其分布式文件存储基础。它将大文件分割成多个数据块,存储在不同节点上,实现高容错性和高扩展性。NameNode 负责管理文件系统命名空间和元数据,DataNode 负责实际数据存储。上传文件时,HDFS 自动将文件切块并分配到不同 DataNode,确保数据可靠性。
MapReduce 是分布式计算模型,用于大规模数据集并行处理。以经典的 WordCount 案例来说,Map 阶段将输入文本分割成单词,并映射为键值对,如(“apple”,1);Reduce 阶段将相同单词的键值对汇总,统计出每个单词的出现次数。这种分而治之的思想,能高效处理海量数据。
Hive 提供了类 SQL 的查询语言 HiveQL,使数据分析人员能方便地对存储在 HDFS 上的数据进行查询和分析。Hive 将 HiveQL 语句转化为 MapReduce 任务执行,降低了大数据处理的门槛。例如统计电商订单数据中的总订单数、各品类销售数量等,使用 HiveQL 能快速完成。
HBase 是基于 HDFS 的分布式 NoSQL 数据库,适用于海量结构化数据的实时读写。比如在物联网场景中,设备产生的海量实时数据,可通过 HBase 快速存储和查询。深入掌握 Hadoop 生态系统,能有效应对大数据处理挑战,挖掘数据价值。
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
大数据
+关注
关注
64文章
9096浏览量
144063
发布评论请先 登录
相关推荐
热点推荐
爱立信携手苹果和联发科技加速构建6G生态系统
爱立信正通过与苹果和联发科技等领先设备及芯片制造商建立战略合作伙伴关系,加速构建6G生态系统,驱动下一代连接技术的创新与互操作性,助力运营商及整个产业为移动网络的未来做好准备。
米尔RK3576成功上车!ROS2 Humble生态系统体验
Humble生态系统,完美移植到了这颗国产芯片上。一个稳定、全功能的机器人软件开发平台已经就绪,现在就来一起探索它的强大魅力!
一、系统启动与基础性能展示1. 硬件平台简介
开发板:MYD-LR3576
发表于 01-15 18:30
探索HD3SS460:USB Type-C生态系统的高性能复用解决方案
探索HD3SS460:USB Type-C生态系统的高性能复用解决方案 在当今的电子设备领域,USB Type-C接口凭借其强大的功能和便捷性,成为了众多设备的标配。而HD3SS460作为一款专门为
Ceva 添加 Sensory 的 TrulyHandsfree 语音激活功能, 增强 NeuPro-Nano NPU 生态系统
体验的需求激增,Ceva公司(纳斯达克股票代码:CEVA)扩展其针对NeuPro-Nano NPU的广泛人工智能生态系统,以满足这一需求。今天,Ceva和Sensory公司宣布合作,将Sensory

Cadence推出全新完整小芯片生态系统
楷登电子(美国 Cadence 公司,NASDAQ:CDNS)今日宣布推出从设计规范到封装部件的完整小芯片生态系统,助力客户开发面向物理 AI、数据中心及高性能计算 (HPC) 应用的小芯片,旨在降低工程设计复杂度,缩短产品上市周期。
海光3350便携机主板:大数据处理利器
随着企业数字化转型加速,大数据处理需求从固定机房向移动场景延伸。无论是金融机构外出调研、科研团队野外数据采集,还是个人创作者处理海量素材,便携设备的性能成为关键。海光便携机主板凭借独特的技术优势,正成为
HD3SS460:USB Type - C 生态系统的多功能复用解决方案
HD3SS460:USB Type - C 生态系统的多功能复用解决方案 在当今高速发展的电子科技领域,USB Type - C 接口凭借其强大的功能和便捷性,成为了众多设备的首选。而
生态流量监测设备技术体系及工程应用实践
生态流量是维系河流生态系统结构与功能的核心水文要素,其监测数据直接支撑水资源开发与生态保护的平衡决策。将生态流量监测设备布设于河流关键节点,

生态流量监测:设备原理、核心参数与实践应用
生态流量作为维系河流、湖泊等水域生态系统平衡的关键指标,其监测数据直接影响水资源开发利用、生态保护修复及流域管理决策。现代生态流量监测技术通

威宏科技加入Arm Total Design生态系统,携手推动AI与HPC芯片创新
2025 年 10 月 15 日 – 系统级IC设计服务领导厂商威宏科技(VIA NEXT)今日宣布正式加入 Arm® Total Design生态系统。此合作展现了威宏科技致力于提供创新

BPI-AIM7 RK3588 AI与 Nvidia Jetson Nano 生态系统兼容的低功耗 AI 模块
应用。
[]()
AIM-IO是一款专为 Jetson Nano 生态系统设计的开源扩展板。它与 RK3588 AI Module7 配合使用,为您提供一个微型 AI 开发平台,支持定制载板开发,并加速机器
发表于 10-11 09:08
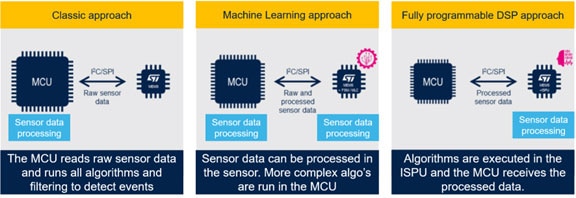
边缘感知生态系统
智能系统 创建边缘智能传感器系统的三种主流方法,如图 1 所示。“经典方法”非常灵活,具有在主机 MCU 上运行的完整算法。 在传感器中集成机器学习和数字信号
RISC-V 在数据中心软件生态系统中的机遇与挑战
软件适配来看,数据中心核心业务涉及的操作系统、存储、数据库、大数据平台、云虚拟化技术及主流编程语言运行时等,大多已能在 RISC-V 架构服务器上实现基础运行。 2025 年 7
发表于 07-18 13:38
•5530次阅读
地物光谱仪在多维生态系统监测中的应用
在气候变化与生物多样性快速演变的背景下,生态系统的监测与研究正走向精细化、数据化和智能化。越来越多科研人员将一种名为“地物光谱仪”的设备,视为构建生态研究“
水色遥感精细化:地物光谱仪在水生态系统监测中的典型应用
在遥感生态监测日益精细化的今天,“地物光谱仪”已经成为水生态系统监测中不可或缺的利器。从湖泊富营养化预警到水华蓝藻监测,再到水体透明度与悬浮物浓度的估算,地物光谱仪正以其高光谱分辨率和



评论