 【AIBOX应用】通过 NVIDIA TensorRT 实现实时快速的语义分割
【AIBOX应用】通过 NVIDIA TensorRT 实现实时快速的语义分割

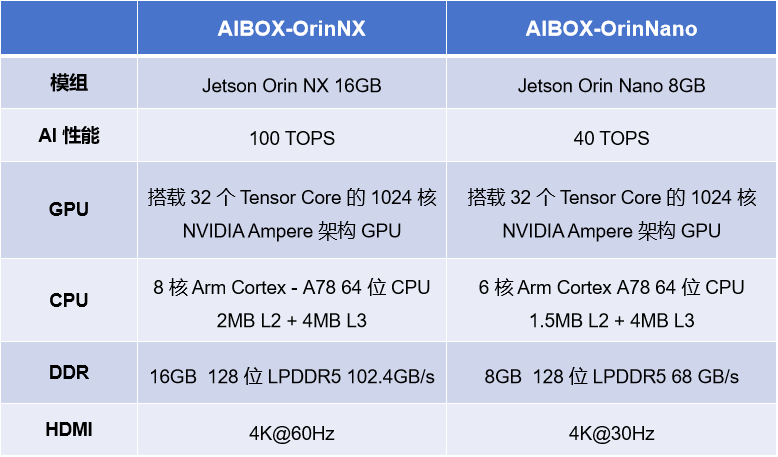
NVIDIA 系列 AIBOX
AIBOX-OrinNano 和 AIBOX-OrinNX 均搭载 NVIDIA 原装 Jetson Orin 核心板模组,标配工业级全金属外壳,铝合金结构导热,顶盖外壳侧面采用条幅格栅设计,高效散热,保障在高温运行状态下的运算性能和稳定性,满足各种工业级的应用需求。
NVIDIA TensorRT
NVIDIA系列 AIBOX 支持深度学习框架TensorRT,TensorRT是用于高性能深度学习推理的 API 生态系统,其包括推理运行时和模型优化,可为生产应用提供低延迟和高吞吐量。
TensorRT 生态系统包括 TensorRT、TensorRT-LLM、TensorRT 模型优化器和 TensorRT Cloud。
NVIDIA TensorRT 的优势
推理速度提升 36 倍
优化推理性能
加速各种工作负载
使用 Triton 进行部署、运行和扩展
应用案例—语义分割
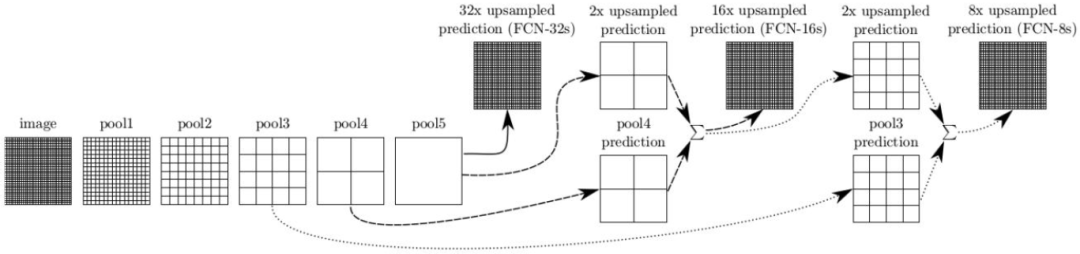
语义分割基于图像识别,但分类是在像素级别进行的,而不是在整个图像上进行。这是通过将预训练的图像识别骨干网络进行卷积化来实现的,将模型转换为能够进行逐像素标注的全卷积网络(FCN)。语义分割对于环境感知特别有用,它能够对每个场景中的许多不同潜在对象(包括前景和背景)进行密集的逐像素分类。
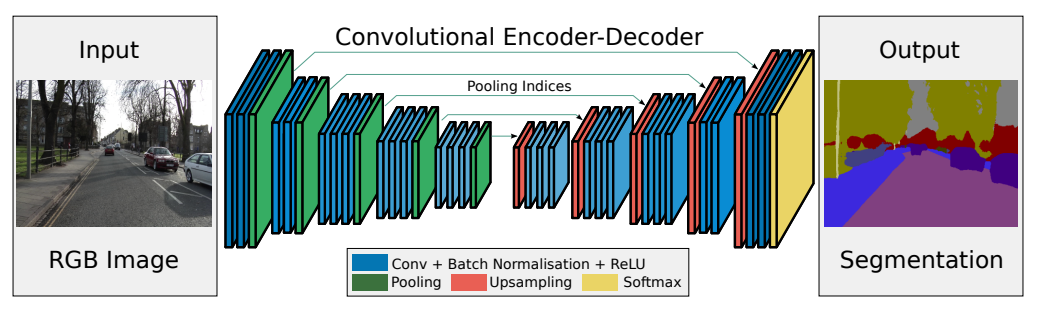
SegNet 模型
SegNet 的新颖之处在于解码器对其较低分辨率的输入特征图进行上采样的方式。具体地说,解码器使用了在相应编码器的最大池化步骤中计算的池化索引来执行非线性上采样。经上采样后的特征图是稀疏的,因此随后使用可训练的卷积核进行卷积操作,生成密集的特征图。SegNet 的架构与广泛采用的 FCN 以及众所周知的 DeepLab-LargeFOV,DeconvNet 架构进行比较。比较的结果揭示了在实现良好的分割性能时所涉及的内存与精度之间的权衡。
下载源码
$ git clone --recursive --depth=1 https://github.com/dusty-nv/jetson-inference
编译 / 安装
参考:https://github.com/dusty-nv/jetson-inference/blob/master/docs/building-repo-2.md
运行示例
$ ./segnet.py --network=fcn-resnet18-cityscapes city_0.jpg output_city_0.jpg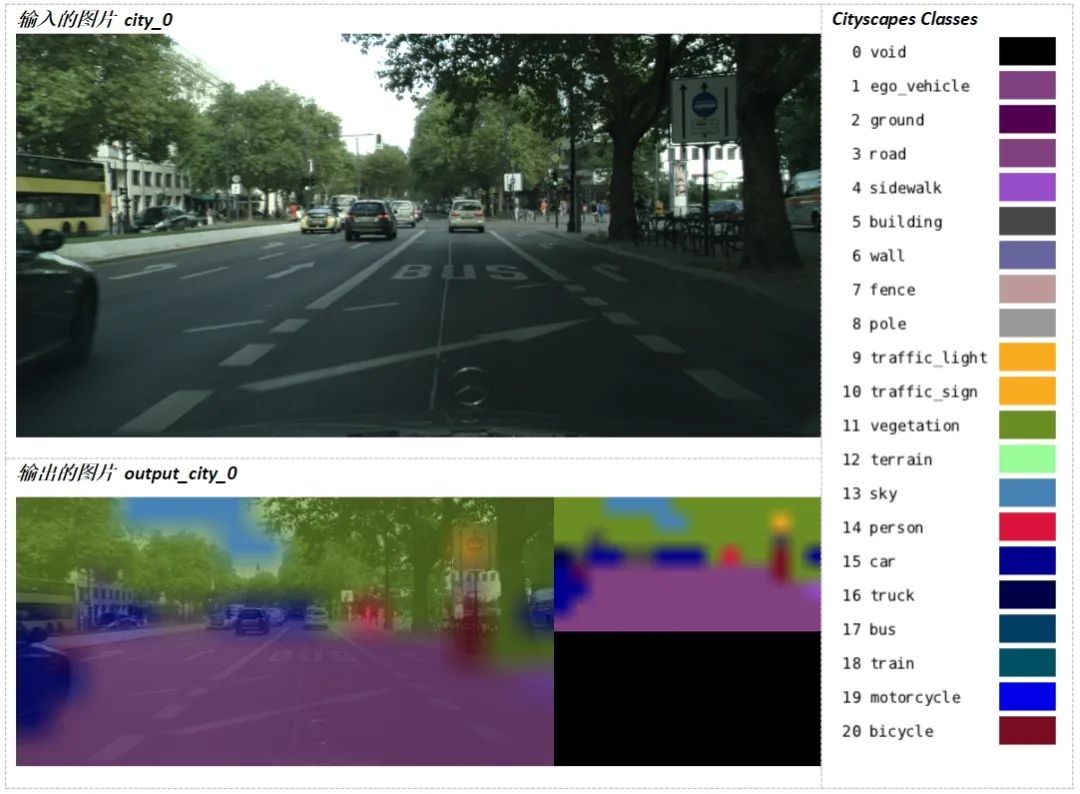
-
解码器
+关注
关注
9文章
1225浏览量
43771 -
NVIDIA
+关注
关注
14文章
5696浏览量
110121 -
核心板
+关注
关注
6文章
1422浏览量
32142
发布评论请先 登录
AI 主机盒在智慧安防中的 5 大应用场景:以视美泰 AIBOX-3576M/AIBOX-3588M 为例

中科创达量产版AIBOX-N1亮相CES 2026
【NPU实战】在迅为RK3588上玩转YOLOv8:目标检测与语义分割一站式部署指南

NVIDIA TensorRT LLM 1.0推理框架正式上线
TensorRT-LLM的大规模专家并行架构设计

中科创达与吉利汽车、NVIDIA联合发布创新产品AIBOX
DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

Ansys使用NVIDIA技术优化CFD仿真解决方案
北京迅为itop-3588开发板NPU例程测试deeplabv3 语义分割

NVIDIA RTX AI加速FLUX.1 Kontext现已开放下载
使用英伟达 NVIDIA Air 服务将仿真与现实世界连接
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
AIBOX 产品矩阵:支持主流大模型的私有化部署,满足个性化 AI 应用需求

使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

【AIBOX 应用案例】通过 U²-Net 实现背景移除



评论