 Transformer模型能够做什么
Transformer模型能够做什么

如果想在 AI 领域引领一轮新浪潮,就需要使用到 Transformer。
尽管名为 Transformer,但它们不是电视银幕上的变形金刚,也不是电线杆上垃圾桶大小的变压器。
在人工智能的快速发展中,Transformer 模型作为一种神经网络,以其独特的自注意力机制,引领了自然语言处理的新浪潮,以革命性的方式推动了整个行业的进步。本文将带您深入了解 Transformer 模型的起源,探讨其如何通过自注意力机制捕捉数据元素间的微妙联系,并理解其在 AI 领域中的关键作用。
什么是 Transformer 模型?
Transformer 模型是一种神经网络,通过追踪连续数据(例如句子中的单词)中的关系了解上下文,进而理解其含义。
Transformer 模型使用一套不断发展的数学方法(这套方法被称为注意力或自注意力),检测一系列数据元素之间的微妙影响和依赖关系,包括距离遥远的数据元素。
谷歌在 2017 年的一篇论文中首次描述了 Transformer,定义它为一种迄今为止所发明的最新、最强大的模型。这种模型正在推动机器学习领域的进步,一些人将其称为 Transformer AI。
斯坦福大学的研究人员在 2021 年 8 月的一篇论文中将 Transformrer 称为“基础模型”,他们认为其推动了 AI 的范式转变。他们在论文中写道:“在过去几年中,基础模型的规模之大、范围之广,超出了我们的想象。”
Transformer 模型能够做什么?
Transformer 可以近乎实时地翻译文本和语音,为不同人群包括听障人士提供会议和课堂服务。
它们还能帮助研究人员了解 DNA 中的基因链和蛋白质中的氨基酸,从而加快药物设计的速度。
Transformer 有时也被称为基础模型,目前已经连同许多数据源用于大量应用中
Transformer 可通过检测趋势和异常现象,为防止欺诈、简化制造流程、提供在线建议或改善医疗服务提供助力。
每当人们在谷歌或微软必应上进行搜索时,就会用到 Transformer。
Transformer AI 的良性循环
Transformer 模型适用于一切使用连续文本、图像或视频数据的应用。
这使这些模型可以形成一个良性的 Transformer AI 良性循环:使用大型数据集创建而成的 Transformer 能够做出准确的预测,从而被越来越广泛地应用,因此产生的数据也越来越多,这些数据又被用于创建更好的模型。
斯坦福大学的研究人员表示,Transformer 标志着 AI 发展的下一个阶段,有人将这个阶段称为 Transformer AI 时代
NVIDIA 创始人兼首席执行官黄仁勋在 GTC 2022 上发表的主题演讲中表示:“Transformer 让自监督学习成为可能,AI 迎来了了飞速发展的阶段。”
Transformer 取代 CNN 和 RNN
Transformer 正在许多场景中取代卷积神经网络和递归神经网络(CNN 和 RNN),而这两种模型在七年前还是最流行的深度学习模型。
事实上,在过去几年发表的关于 AI 的 arXiv 论文中,有 70% 都提到了 Transformer。这与 2017 年 IEEE 的研究报告将 RNN 和 CNN 称为最流行的模式识别模型时相比,变化可以说是翻天覆地。
无标记且性能更强大
在 Transformer 出现之前,用户不得不使用大量带标记的数据集训练神经网络,而制作这些数据集既费钱又耗时。Transformer 通过数学方法发现元素之间的模式,因此实现了不需要进行标记,这让网络和企业数据库中的数万亿张图像和数 PB 文本数据有了用武之地。
此外,Transformer 使用的数学方法支持并行处理,因此这些模型得以快速运行。
Transformer 目前在流行的性能排行榜上独占鳌头,比如 2019 年为语言处理系统开发的基准测试 SuperGLUE。
Transformer 的注意力机制
与大多数神经网络一样,Transformer 模型本质上是处理数据的大型编码器/解码器模块。
其能够独占鳌头的原因是在这些模块的基础上,添加了其他微小但具有战略意义的模块(如下图所示)。
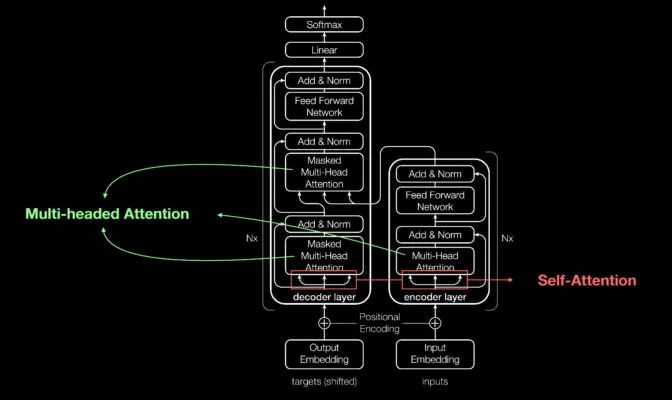
Aidan Gomez(2017 年定义 Transformer 的论文的 8 位共同作者之一)展示内容的概览图
Transformer 使用位置编码器标记进出网络的数据元素。注意力单元跟踪这些标签,计算每个元素与其他元素间关系的代数图。
注意力查询通常通过计算被称为多头注意力中的方程矩阵并行执行。
通过这些工具,计算机也能看到人类所看到的模式。
自注意力机制能够明确意义
例如在下面的句子中:
她把壶里的水倒到杯子里,直到它被倒满。
我们知道这里的“它”指的是杯子,而在下面的句子中:
她壶里的水倒到杯子里,直到它被倒空。
我们知道这里的“它”指的是壶。
领导 2017 年这篇开创性论文研究工作的前 Google Brain 高级研究科学家 Ashish Vaswani 表示:“意义是事物之间的关系所产生的结果,而自注意力是一种学习关系的通用方法。”
Vaswani 表示:“由于需要单词之间的短距离和长距离关系,因此机器翻译能够很好地验证自注意力。”
“现在我们已经看到,自注意力是一种强大、灵活的学习工具。”
Transformer 名称的由来
注意力对于 Transformer 非常关键,谷歌的研究人员差点把这个词作为他们 2017 年模型的名称。
在 2011 年就开始研究神经网络的 Vaswani 表示:“注意力网络这个名称不够响亮。”
该团队的高级软件工程师 Jakob Uszkoreit 想出了“Transformer”这个名称。
Vaswani 表示:“我当时觉得我们是在转换表征,但其实转换的只是语义。”
Transformer 的诞生
在 2017 年 NeurIPS 大会上发表的论文中,谷歌团队介绍了他们的 Transformer 及其为机器翻译创造的准确率记录。
凭借一系列技术,他们仅用 3.5 天就在 8 颗 NVIDIA GPU 上训练出了自己的模型,所用时间和成本远低于训练之前的模型。这次训练使用的数据集包含多达十亿对单词。
2017 年参与这项工作并做出贡献的谷歌实习生 Aidan Gomez 回忆道:“距离论文提交日期只有短短三个月的时间。提交论文的那天晚上,Ashish 和我在谷歌熬了一个通宵。我在一间小会议室里睡了几个小时,醒来时正好赶上提交时间。一个来得早的人开门撞到了我的头。”
这让 Aidan 一下子清醒了。
“那天晚上,Ashish 告诉我,他相信这将是一件足以改变游戏规则的大事。但我不相信,我认为这只是让基准测试进步了一点。事实证明他说得非常对。”Gomez 现在是初创公司 Cohere 的首席执行官,该公司提供基于 Transformer 的语言处理服务。
机器学习的重要时刻
Vaswani 回忆道,当看到结果超过了 Facebook 团队使用 CNN 所得到的结果时,他感到非常兴奋。
Vaswani 表示:“我觉得这可能成为机器学习的一个重要时刻。”
一年后,谷歌的另一个团队尝试用 Transformer 处理正向和反向文本序列。这有助于捕捉单词之间的更多关系,提高模型理解句子意义的能力。
他们基于 Transformer 的双向编码器表征(BERT)模型创造了 11 项新记录,并被加入到谷歌搜索的后台算法中。
“由于文本是公司最常见的数据类型之一”,在短短几周内,全球的研究人员就将 BERT 应用于多个语言和行业的用例中。Anders Arpteg,这位拥有 20 年机器学习研究经验的专家表示,因为文本是公司最常见的数据类型之一,所以这种调整变得尤为重要。
小结
Transformer 模型的诞生标志着自然语言处理技术的一次重大飞跃。本文上篇为您揭示了这一模型的基本原理和发展历程。随着对 Transformer 模型的深入理解,我们可以看到其在机器翻译、文本理解、基因序列分析等多个领域的广泛应用,预示着 AI 技术革新与发展的无限可能。
-
AI
+关注
关注
90文章
38189浏览量
297001 -
模型
+关注
关注
1文章
3649浏览量
51719 -
Transformer
+关注
关注
0文章
154浏览量
6819
原文标题:什么是 Transformer 模型(一)
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

Transformer如何让自动驾驶变得更聪明?
图解AI核心技术:大模型、RAG、智能体、MCP
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
小白学大模型:国外主流大模型汇总

NVIDIA Nemotron Nano 2推理模型发布

自动驾驶中Transformer大模型会取代深度学习吗?

Transformer架构中编码器的工作流程

Transformer架构概述

VLM(视觉语言模型)详细解析

如何使用MATLAB构建Transformer模型

transformer专用ASIC芯片Sohu说明






 工商网监
工商网监
评论