 存内生态构建重要一环- 存内计算工具链
存内生态构建重要一环- 存内计算工具链

本篇文章重点讲述存内计算相关工具链,我们将从工具链定义出发,依次讲述工具链研究背景及现有工具链、存内计算相关工具链发展现状、存内计算工具链未来展望等内容。
一.工具链研究背景及现有工具链
工具链,英文名称toolchain,通常是指在软件开发或硬件设计中使用的一系列工具和软件,用于完成特定任务或流程。这些工具一般接连地使用,从而完成一个个任务,这也是“工具链”名称的由来。一般工具链的研发,大致与通用应用程序生命周期一致,分为五个阶段,如下图1所示,图中包括每个阶段对应的工具等[1]。
 图1 工具链研发模型
图1 工具链研发模型(1)EDA工具链[2]:
EDA 是 Electronic Design Automation 的简称,即电子设计自动化,是指利用计算机辅助设计软件,完成超大规模集成电路芯片的功能设计、综合、验证、物理设计等流程的设计方式。在集成电路应用的早期阶段,集成电路集成度较低,设计、布线等工作由设计人员手工完成。1970 年代中期开始,随芯片集成度的提高,设计人员开始尝试将整个设计工程自动化。
1980 年发表的论文《超大规模集成电路系统导论》提出通过编程语言来进行芯片设计,是电子设计自动化发展的重要标志,EDA 工具也在这个时期开始走向商业化。21 世纪以来,EDA 工具快速发展,并已贯穿集成电路设计、制造、封测的全部环节,从而加速集成电路产业的技术革新。
EDA行业市场集成度较高,如下图2所示,全球 EDA 行业主要由楷登电子、新思科技和西门子EDA 垄断,上述三家公司属于具有显著领先优势的第一梯队。国内起步较晚,虽然发展迅速,但最高只能做到第二梯队,有很大发展空间。
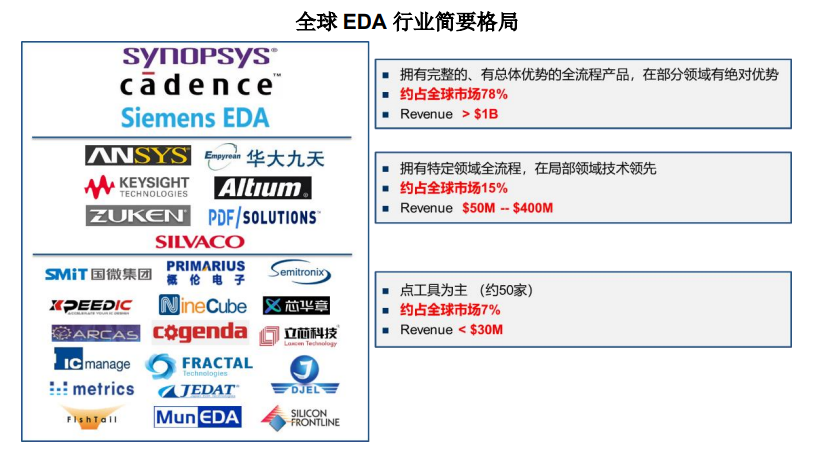 图2 全球EDA简要格局
图2 全球EDA简要格局(2)人工智能编译工具链[3]:
由于人工智能算法的不断突破,其模型尺寸和算力需求飞速增长,从而导致算法与芯片之间存在巨大的算力“鸿沟”。首先每个模型的算力利用率低,甚至小于10%,其次算子库没有统一的标准,每个芯片的制作流程中都要耗费巨大的人力物力来维护庞大算子库。而人工智能编译器是发挥硬件算力的保障,可以解决以上问题,如下图3为人工智能编译器常用设计架构概述。
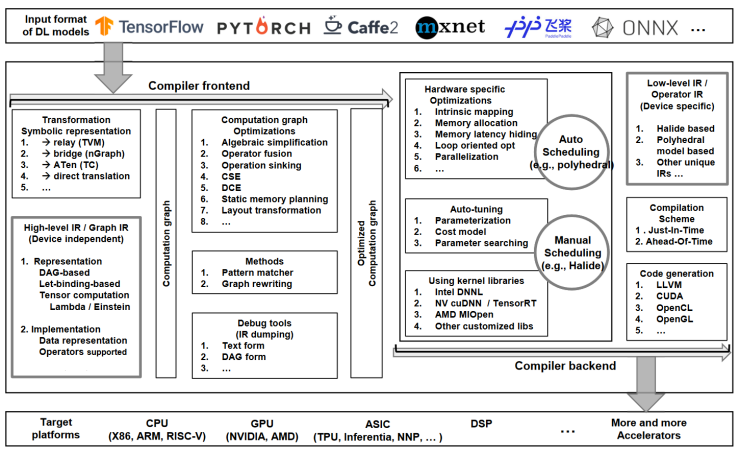 图3 深度学习编译器常用设计架构概述
图3 深度学习编译器常用设计架构概述人工智能编译器在早期只是一个从计算图(数据流图)到算子库的映射器。许多深度学习编程框架(TensorFlow和PyTorch等)将模型表示成计算图,而计算图的执行通过调用第三方算子库完成。编译器将计算图映射到算子库,是人工智能框架和算子库中间的桥梁。此后,为了优化模型性能,各框架都引入了计算图编译器,进行计算图级优化。然而人工智能编译器的研究是我们的短板,例如谷歌的XLA编译器可以将性能最高提升十倍以上,而国产人工智能芯片的峰值算力高,但实际代码的利用率低,因此研究人工智能芯片的配套软件工具链刻不容缓。
人工智能编译工具链和存内计算芯片联系密切,在存内计算芯片从设计到生产的全流程中,工具链的设计是非常重要的环节,其能够将深度学习框架中的不同模型作为输入,根据硬件设计产生高效的输出代码,实现深度学习模型到硬件设备的部署。然而,当前神经网络模型在存内计算芯片上可移植性低,部署成本高,大大阻碍了存内计算技术在深度学习领域的大规模应用。因此,面向存内计算芯片的人工智能编译工具链也是亟待研发的。
综上所述,当前芯片设计、人工智能等工具链发展较为成熟,但存内计算相关工具链还有很大的发展空间。目前,存内计算相关工具链还存在着缺乏成熟的标准单元库与快速组装工具、缺乏成熟的功能与性能仿真验证工具、缺乏建模和误差评估工具等问题,都等待着从业人员去攻克解决。
二.存内计算相关工具链发展现状
存内计算工具链可以认为是辅助开发人员将软件设计部署到存内计算硬件上的工具。存内计算从原理上对神经网络中常见的乘累加运算具有良好的支持,使得存内计算在人工智能领域具有巨大潜力。因此,存内计算工具链可以在狭义上认为是将神经网络部署到存内计算芯片中,使其在片上运行的工具。
为了更方便地使用神经网络模型,许多通用神经网络框架已经被提出,如TensorFlow、PyTorch、Caffe、MXNet、CNTK等,它们提供了一系列打包好的网络层等工具,方便用户编写自己的神经网络模型。神经网络模型在硬件上的运行依赖于神经网络编译工具链,如TVM、MLIR、nGraph、XLA等。[5]然而,存内计算作为一种新型计算范式,将存储单元和计算单元融合,其存储和计算特性不同于传统硬件,使得现有神经网络工具链并不适用于存内计算。[6]
学术研究中,由于研究的重点往往是存内计算硬件设计,并且工具链需要对软件算法模型、编译工具、电路等多个相关的特定领域知识有着深入理解,受限于高校的科研资源,该部分的研究往往作为存内计算硬件研究的附属工作,实际使用中神经网络的部署工作大多由研究者手动完成。同时,当前国内神经网络工具链存在峰值算力高,但是实际代码利用率低的问题。[7]
部分科研人员针对存内计算编译器相关问题开展研究,并已经取得了一定的研究成果。例如,PUMA是一种基于忆阻器的机器学习推理加速器,它支持ISA指令集,并且具有转换将高级语言为ISA代码的编译器,编译器对计算图进行分区,并优化指令调度和寄存器分配,以便为在数千个空间内核上运行的大型复杂工作负载生成代码。[8]但是,该编译器采用的启发式权重复制和核心映射方法(heuristic weight replicating and core mapping method)难以保证高性能;此外,PUMA的层间流水线是以推理为粒度的,即不同层处理不同的推理数据,这种处理方式在低延迟场景下对性能同样产生较大影响。[6]
然而,工具链是连接开发者与硬件的桥梁,是吸引开发者,丰富硬件平台算法环境的重要一环,是企业节省开发成本的重要手段。因此,在商业领域中,工具链的作用不容忽视,如国内存内计算企业知存科技和后摩智能,已经提出了适配自身硬件的工具链。
根据后摩智能官网信息,后摩大道™软件平台是服务后摩鸿途™H30芯片硬件的自研软件开发平台,主要由模型开发SDK、算子开发SDK、系统及中间件等组件构成,可以兼容不同硬件平台的底层异构计算框架,易于跨平台迁移;自带预编译参考模型,方便用户直接使用;使用适配存算一体架构的并行数据开发语言,同时支持C/C++编程;推理引擎支持自动融合流水、自动内存分配等编译优化技术。[9]
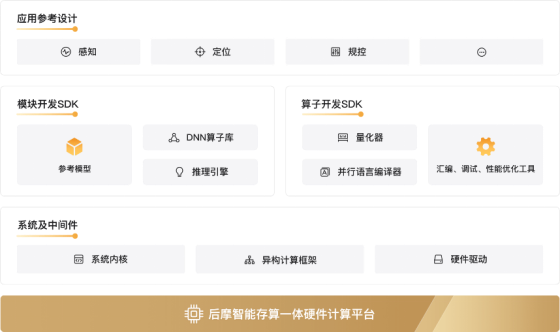 图4 后摩智能存算一体平台
图4 后摩智能存算一体平台
根据知存科技官网信息,WITIN_MAPPER是知存科技自研的用于神经网络映射的编译软件栈,可以将量化后的神经网络模型映射到WTM2101 MPU加速器上,是一种包括RISC-V和MPU的完整解决方案,可以完成算子和图级别的转换和优化,将预训练权重编排到存算阵列中,极大地缩短模型移植的开发周期并提高算法开发的效率[10]。工具链配备五种可选的优化策略:参数放大、权重复制、高比特稀疏、多点卷积优化、正负(PN)优化,实际应用中,用户可根据权重大小、输入数据类型、精度要求、速度要求等多方面自行选择,一般来讲,权重复制+正负(PN)优化+多点卷积优化就可以满足大部分要求。[11]
 图 5 WTM2101软件栈-witin_mapper[10]
图 5 WTM2101软件栈-witin_mapper[10]同时,知存科技提供WITMEM STUDIO集成开发环境、SPI Moniter工具、开发板等开发工具。其中,集成开发环境包含客户识别的SDK推送功能,SDK包自动更新下载安装功能,内核自动识别语法高亮编辑器,面向不同功能的个性化工程创建功能,以及常规IDE所具有的项目工程管理,文件编辑、编译、调试等功能。[10]
 图6 WTM2101-ZT1开发板
图6 WTM2101-ZT1开发板
以上知存科技相关资料来自于知存科技打造的“存内计算芯片开发者中心”(开发者社区 知存科技 全球领先的存内计算芯片企业:http://www.witintech.com/),其中有知存科技打造的一套完整的芯片开发工具和IDE环境,在此中心中,知存科技将持续分享和更新针对存内计算芯片的软件、编译工具链、算法资源、开发教程等等,为工程师、研究人员和技术爱好者提供工具和灵感。
三.存内计算工具链未来展望
在上文中,我们介绍了当前存内计算工具链遇到的困难、存内计算工具链发展现状等等,对于未来存内计算工具链的发展,我们有如下几点展望。
由于存内计算芯片的设计与常规芯片有较大差异,我们需要适配于存内计算芯片设计的相关EDA软件,他们需要包含以下必需工具:
1.标准单元库与快速组装工具。由于存内计算芯片设计的单元结构不唯一,采用不同存储介质的存内芯片核设计起来缺少标准单元库,且较大的存算阵列也缺少快速组装工具,目前这两点往往是靠设计者手动绘制完成,效率较低。
2.功能验证与仿真验证工具。当前EDA软件没有面向存内计算场景进行优化的功能仿真验证工具,仿真时大规模的存算阵列会增加仿真难度与时间。
3.建模与误差评估工具。当前软件缺少面向存内计算芯片的电路噪声建模与误差评估工具,这些可以帮助开发者在设计阶段对方案进行评估并及时调整。[12]
此外,由于存内计算在人工智能、深度学习层面运用广泛,设计面向存算一体芯片的深度学习编译工具链也是未来存内计算工具链发展的重要一环,针对人工智能与深度学习,我们希望工具链能达成:
1,由于深度学习算法与存算一体电路间可移植性低,部署成本高,我们需要设计一套工具链实现前端网络模型转换及优化的策略、后端硬件映射及优化的方法,从而构建一套高性能的存算一体软硬件结合系统。
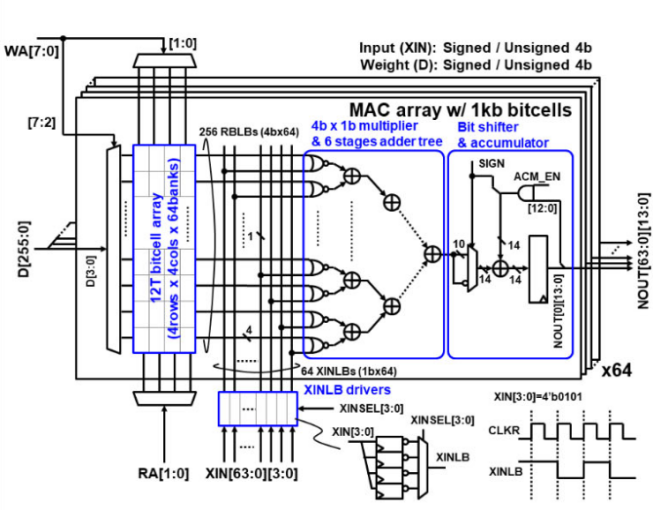
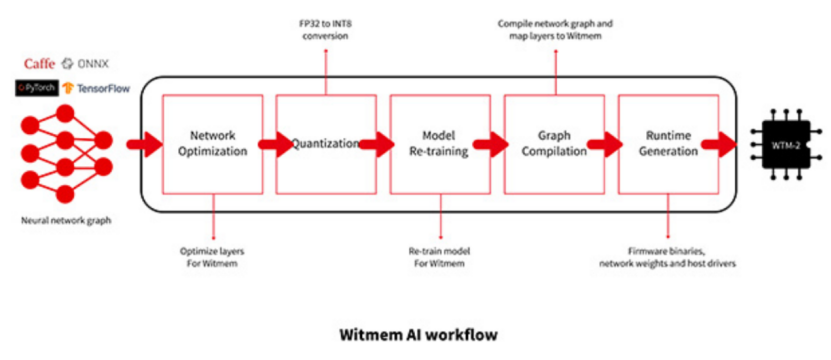 图 7 神经网络模型部署至WTM2101的一套编译工具链[13]
图 7 神经网络模型部署至WTM2101的一套编译工具链[13]
2,由于存内计算芯片中有众多存算核,未来若要在存内计算芯片上部署大模型,那么多核之间的资源调度便十分重要;权重在核中怎么存、计算资源如何调度、多核之间如何协同等等问题,都需要我们设计出一套工具链来解决。
总而言之,为推动存内计算规模应用,相关EDA软件、配套的开发环境、编译平台的建立将成为存内计算芯片设计中的必然诉求,它们需要业界共同发力,共同搭建面向存内计算的编程框架,健全仿真和编译工具,完善算法设计与开发生态。相信在不久的将来,存内计算芯片相关工具链将迎来井喷式发展,让我们一同分享、一同创造,一起见证存内计算芯片的生态繁荣时代。
参考资料
[1]持续交付工具前景 ·詹姆斯·鲍曼 (jamesbowman.me).
[2]北京华大九天科技股份有限公司招股说明书.
[3]第二十届全国容错计算学术会议-过敏意-面向人工智能芯片的编译新技术.
[4] Li M, Liu Y, Liu X, et al. The deep learning compiler: A comprehensive survey[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(3): 708-727.
[5] Li M, Liu Y, Liu X, et al. The deep learning compiler: A comprehensive survey[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(3): 708-727.
[6] Sun X, Wang X, Li W, et al. PIMCOMP: A Universal Compilation Framework for Crossbar-based PIM DNN Accelerators[C]//2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023: 1-6.
[7] 第二十届全国容错计算学术会议-过敏意教授报告-面向人工智能芯片的编译新技术
[8] Ankit A, Hajj I E, Chalamalasetti S R, et al. PUMA: A programmable ultra-efficient memristor-based accelerator for machine learning inference[C]//Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. 2019: 715-731.
[9] 后摩智能官网(houmoai.com)
[10] 知存科技开发文档(开发者社区 知存科技 全球领先的存内计算芯片企业:http://www.witintech.com/)
[11] Bai T, Mao W, Wang G, et al. An End-to-End In Memory Computing System Based On A 40nm eFlash-Based IMC SoC: Circuits, Toolchains, and Systems Co-Design Framework[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024.
[12] 详细解读存算一体技术路线 - 电子发烧友(elecfans.com)
[13] 存内计算芯片开发者中心 - (开发者社区 知存科技 全球领先的存内计算芯片企业:http://www.witintech.com/)
-
eda
+关注
关注
72文章
3140浏览量
183665 -
开发工具链
+关注
关注
0文章
28浏览量
1838 -
IC芯片设计
+关注
关注
0文章
7浏览量
1318 -
知存科技
+关注
关注
0文章
72浏览量
5555 -
存内计算
+关注
关注
0文章
35浏览量
1674
发布评论请先 登录
存内计算芯片研究进展及应用
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究


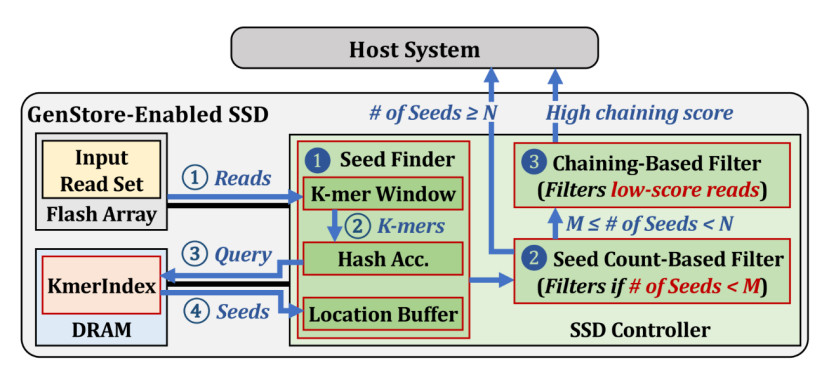
存内计算WTM2101编译工具链 资料
什么是存内计算
浅谈存内计算生态环境搭建以及软件开发



评论