 芯原股份DC8200显示处理器IP助力赛昉科技RISC-V架构SoC
芯原股份DC8200显示处理器IP助力赛昉科技RISC-V架构SoC

芯原股份宣布,赛昉科技成功将芯原的先进显示处理器IP DC8200应用于其基于RISC-V架构的量产SoC昉·惊鸿-7110中。JH-7110 SoC以其卓越的性能、低功耗和安全性,为众多领域如云计算、工业控制、网络附加存储等提供了全面的智能视觉处理方案。
DC8200 IP作为芯原的核心技术,具备出色的图像质量增强能力,能够为用户带来无与伦比的视觉享受。其高度可配置的特性,使得DC8200能够灵活适应不同应用需求,提供最优解决方案。此外,通过芯原独有的压缩技术,DC8200有效降低了DDR带宽,进一步提升了系统效率。
值得一提的是,DC8200还支持双操作系统,与RISC-V CPU协同工作,满足了市场对产品多样性的需求。同时,它能够与芯原的其他视频和图像处理IP无缝集成,形成功能强大的子系统,为用户带来清晰锐利的图像、细腻逼真的细节以及丰富生动的色彩,营造沉浸式的视觉体验。
此次合作不仅展现了芯原在显示处理器领域的深厚实力,也为RISC-V架构的广泛应用注入了新的活力。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
处理器
+关注
关注
68文章
20395浏览量
255745 -
赛昉科技
+关注
关注
3文章
185浏览量
15652 -
芯原股份
+关注
关注
0文章
49浏览量
2749
发布评论请先 登录
相关推荐
热点推荐
赛昉科技 × Computex 2026 | RISC-V全栈方案即将登场!
2026台北国际电脑展(Computex2026),赛昉科技将精彩亮相,展示一系列基于RISC-V的IP、芯片与解决方案,期待您的莅临与交流!时间:6月2日-5日地点:台北南港展览馆一

北极芯微最新dToF深度感测SoC采用Andes晶心科技RISC-V处理器
科技(Andes Technology)的 N25F以及N225 RISC-V 处理器 IP,为智能感测与机器人应用提供高效能、低功耗且具高度弹性的运算平台。
赛昉科技2025:引领RISC-V驶入数据中心深水区
2025年,是RISC-V从技术走向场景的关键一年。赛昉科技始终相信:唯有落地,才能创造真实价值。我们以规模化商用为锚点,推动RISC-V深入数据中心核心、走进千行百业。在此,向您呈上

重磅合作!Quintauris 联手 SiFive,加速 RISC-V 在嵌入式与 AI 领域落地
SoC 开发流程,帮开发者省时间;
优化下一代 RISC-V 设计的性能和能效,进一步拉高性能上限;
把 RISC-V 打造成能和传统专有处理器架
发表于 12-18 12:01
RISC-V实现数据中心应用突破,赛昉科技BMC芯片重磅亮相
生态大会上,记者就曾经现场看到过,并了解这款产品的特性。 现场工作人员介绍,JH-B100是上海赛昉科技推出的业界首颗基于 RISC-V 架构的国产 BMC芯片,其

2025 RISC-V产业发展大会 | 赛昉科技全景展示规模化商用成果
2025年11月24日,RISC-V产业发展大会在珠海开幕。赛昉科技以“推动RISC-V规模化商用”为核心主题,重点展示了面向数据中心、边缘计算及智能终端的全栈产品与成熟应用,全面呈现
赛昉科技重磅发布新产品,RISC-V实现数据中心规模化商用突破
2025年11月14日,中国香港——赛昉科技隆重发布首款基于RISC-V架构的数据中心管理芯片“狮子山芯”。作为一款具有里程碑意义的产品,“
首款RISC-V BMC芯片荣获“中国芯”,赛昉科技产品连续三年入选
2025年11月14日,“中国芯”集成电路产业促进大会暨第二十届“中国芯”优秀产品征集结果发布仪式在珠海横琴举行。赛昉科技推出的业界首款基于RISC
易灵思Sapphire SoC中RISC-V平台级中断控制器深度解析
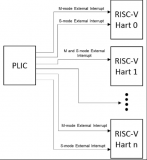
随着 RISC -V处理器在 FPGA 领域的广泛应用,易灵思 FPGA 的 Sapphire RISC-V 内核凭借软硬核的灵活支持,为开发者提供多样选择。本文深入探讨 Sapph
全球首款RiSC-V企业级模拟平台,跃昉科技LeapEMU正式亮相
9月19日,广东跃昉科技在珠海举办的“RISC-V软件生态研讨会上”,公司正式发布了全球首款支持超128核RiSC-V RVA23企业级模拟平台LeapEMU。跃昉科技创始人兼CEO江

赛昉科技入驻RuyiSDK开发者社区,双平台协同推进RISC-V生态
赛昉科技(StarFive)正式入驻RuyiSDK开发者社区,携手推动RISC-V技术创新。后续,赛昉科技的技术突破与生态进展将同步在RVs
赛昉科技徐滔:以精准场景牵引,RISC-V抢滩数据中心百万颗市场
7月16-19日,第五届RISC-V中国峰会在上海张江科学会堂成功举办。国内领先的RISC-V厂商赛昉科技携多款重磅产品亮相,集中展示自研创新技术和成果。峰会期间,
赛昉科技联合合见工软实现国产一致性NoC IP与RISC-V核在大规模网络中的适配
的一致性片上网络(NoC)IP——昉·星路-700(StarNoC-700)已成功适配赛昉科技昉·天枢(Dubhe)系列
睿思芯科携灵羽处理器亮相2025 RISC-V中国峰会
第五届RISC-V中国峰会于16日在上海张江开幕,会上睿思芯科展示了中国首款全自研高性能RISC-V服务器处理器——灵羽
“核心技术突破+关键应用支撑”,赛昉加速RISC-V生态突围
核心技术护城河1.首款适配RISC-V核的国产一致性NoCIP——StarNoC-700在高性能计算分论坛上,赛昉科技IP产品线总经理周杰宣布,公司自主研发的大规模一



评论