 AMBA总线之AXI设计的关键问题讲解
AMBA总线之AXI设计的关键问题讲解

1、设计AXI接口IP的考虑
1.1、AXI Feature回顾
首先我们看一下针对AXI接口的IP设计,在介绍之前我们先回顾一下AXI所具有的一些feature。
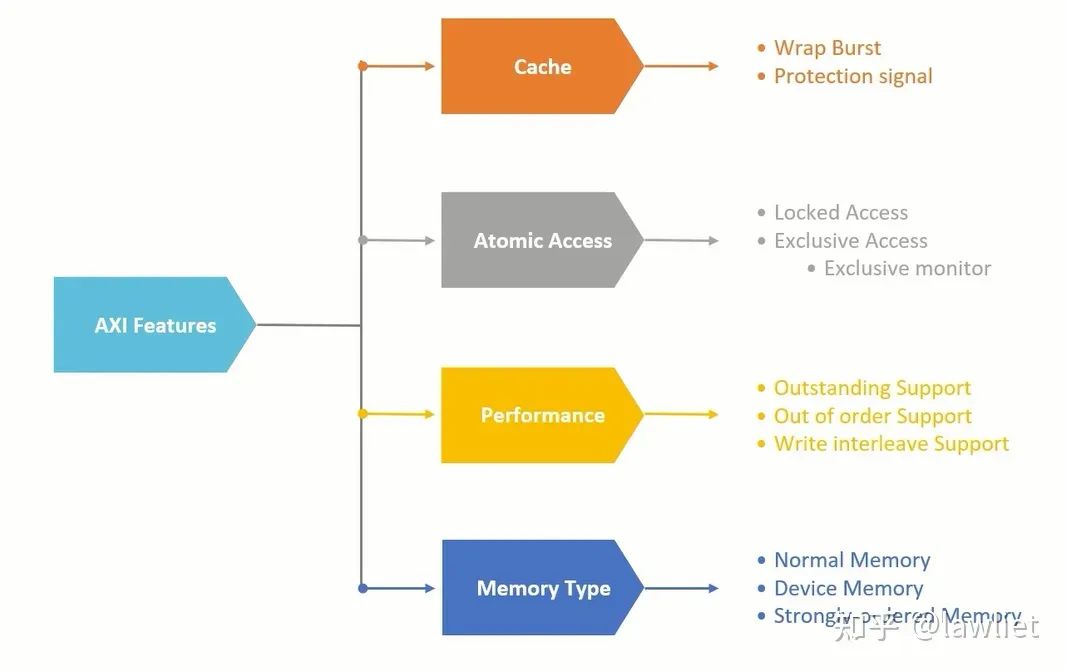
首先是Cache相关的问题,Cache是提高系统Performance的一种很好的方式,AXI通过AxCache信号来决定是否可以访问Cache,是否可以分配Cache。
然后是原子操作,原子操作我专门花了一篇文章进行讲解,大家使用的时候尽量只使用Exclusive Access,Locked Access会阻塞总线,导致带宽无法充分利用,对系统性能影响较大。其实诸如此类的设计,对性能及吞吐量敏感的地方都应该避免使用,我们称为阻塞性xxx。为了支持Exclusive Access,我们自然需要Exclusive Monitor,来满足协议的要求,如何进行设计之前的文章也有提及,不再细说。
然后我们看一下AXI是如何提高性能的,这也是面试比较喜欢问的。如上面的图所示,主要有三种方式,我称之为提高AXI性能的三板斧,排名分先后。
Outstanding对性能影响最显著,尤其是主从之间通讯需要多拍的时候,它充分利用了这段时间发起别的传输。其实就是通过这些操作去掩盖原本的访存延时。
然后是乱序(Out of Order),这个提高性能主要体现在Slave无法及时响应,就可以让后发起的请求先完成。就比如你去超市买菜,你前面的人刚好手机没电了,你是等他充好电还是先让你付款?
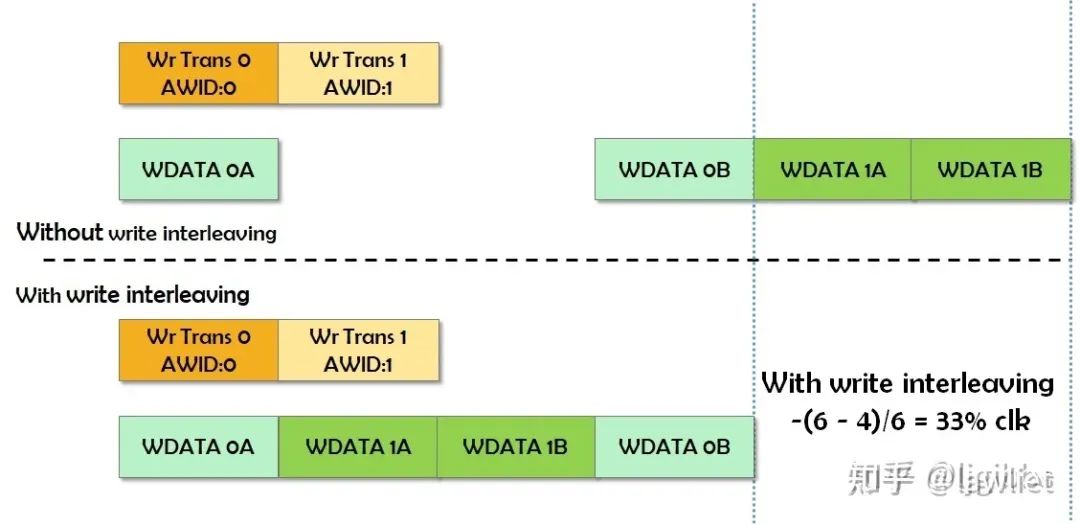
最后是Interleave,即交织读写,这个其实就是在空闲的Cycle中(气泡Cycle)插入读写事务,其实有点像乱序,可以理解成更加细粒度的乱序。当然粒度这么细,导致设计很复杂,所以在AXI4中写交织就被移除了
最后是Memory Type的不同,基于Memory类型的不同,可以决定你的读写是否可以Bufferable或者Cacheable。比如某些外设寄存器,你写完是希望直接改变系统当前的运行状态的,希望即刻生效,这种当然几不可以Cacheable也不可以Bufferable。而有些外设寄存器,比如写Flash Controller的寄存器,你写完以后,稍微延迟一些Cycle或者有乱序是可以接受的,这种情况就可以Bufferable。

1.2、Ordering consideration
首先我们看一下Write Channel和Read Channel之间的一个Order,AXI协议并没有对它们之间的Order有一个约束,如果想要实现该机制,就应该在之前的transaction收到最后的response以后才允许发起新的transaction。
你可以通过配置某个寄存器,来开启该功能。这个设计起来不是很复杂。如果你使用的是ARM或者X86或者主流的商用CPU,你可以使用memory barrier指令来确保这个顺序。

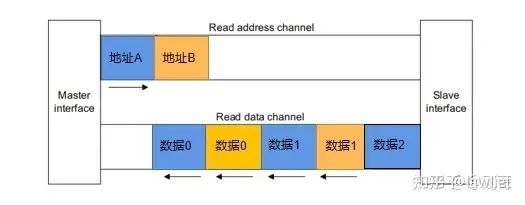
然后我们看一下对于Master而言,对于来自Slave的Response,是可以乱序的,通过ID来区分好就行。此外对于Read response而言,是可以Interleave的。读交织如下图所示。
而对于同一ID而言,即Master发出的同一AWID/ARID而言,相应的数据必须是顺序的,如果不是顺序的,怎么知道哪个数据对应于哪一个地址?
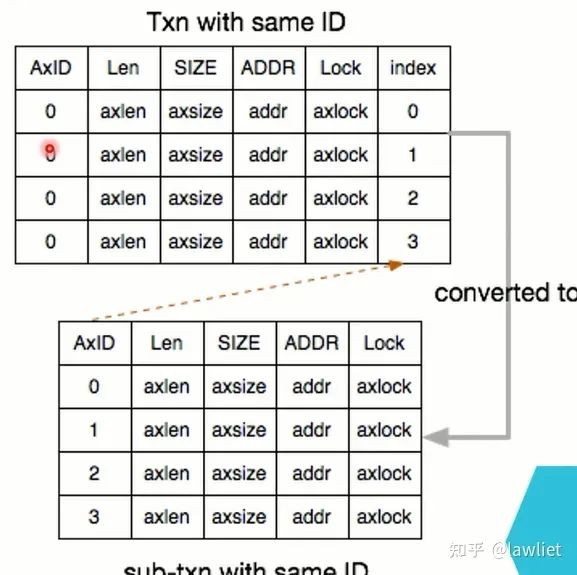
我们看一下Slave的实现,Slave想实现Order Model,比Master要复杂的多。我们想象一下这样的一个例子,一个Master去访问一个Slave,而这个Slave有很多不同的Memory Type,比如既有访问较快的寄存器,也有相对慢一点的SRAM,甚至还有DDR/FLASH。比如你去写一个DDR Controller,你去写它的配置寄存器,很快,你去写DDR,其实也要走这个DDR Controller,这样一次访问就非常非常的慢。
但是,由于是同一个Master的访问,其ID是相同的,相同ID要保序,那难不成每次写DDR,都要等着数据回来?显然非常的不合理,那么在其内部就可以做一个转换表,如下图所示,来的时候是同样的ID,但Slave可以将其转换成不同的ID,这样就可以Outstanding了,也可以乱序了,非常的Amazing啊。注意,Slave内部是可以Out of Order返回的,但你返回给Master还是得顺序的。需要一块额外的存储空间来缓存这些需要返回的数据及相关信息,当来了,你就返回给Master。
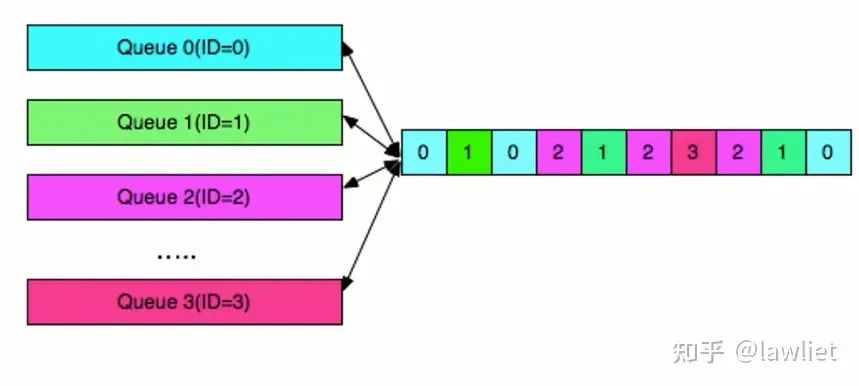
我们再看一下Master的实现,当Master有多个Engine,比如DMA。每个DMA发出的ID是不一样的,当发出多个Outstanding的请求,Slave也相应的根据请求把数据拿回来了。相应的准备若干个Queue,当ID为0的返回的时候送给Queue0,当ID为0的最后一笔返回的时候即RLAST拉高的时候,做相应的处理返回给发出请求的Engine。其实就是需要一定的缓冲机制,来避免接不到数据等情况。
Master需要数据queue来支持out of order;
Master需要buffer来支持outstading;
1.3、Debugging
大多数的时候,都认为各自是遵循总线协议的,但还是需要一定的能力,来做Debugging,毕竟某些IP会不遵守协议,会出错。
使用counter来监视发起了多少次传输事务(transaction),以Master那边为例,当发出一次outstading请求,相应的counter+1,当收到最后的response,counter-1。这样系统挂死以后,发现某个Master的monitor记录counter不为0,这样就可以快速定位错误;
axvalid&axready=1,cnt+1
对于写,当bvalid&bready=1,cnt-1
对于读,当rvalid&rready&rlast,cnt-1
还可以记录transfer数量
还可以记录更多的信息,如axlen、axid、axsize等;
使用timeout机制;
2、Interconnect拓扑结构
假设基于AXI的Master和Slave已经设计好了,如何对它们进行连接呢?当多个Master和Slave进行通信的时候,就需要Interconnect。
Interconnect的拓扑结构多种多样,基于AXI的Interconnect一般采用Crossbar,如ARM-NIC400,这里我们也只讲这种方式。
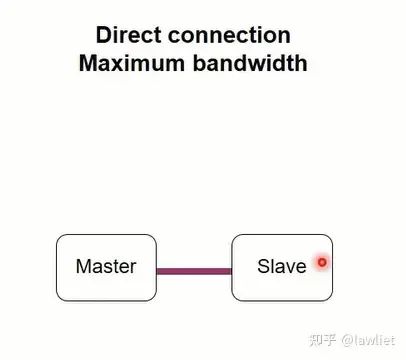
我们看一下基于Crossbar的方式,首先是最简单的点对点方式,这种情况比较少见,比较典型的如ACP接口,Master需要直接访问Slave的cache(此时CPU作为Slave,并且是唯一的Slave),这种情况就可以点对点,而不用走多对多的总线。
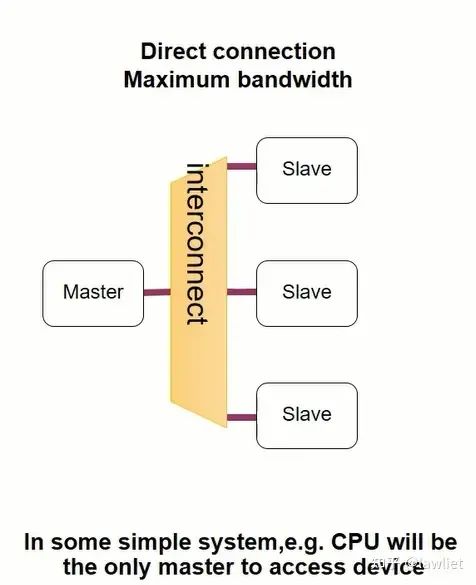
然后是一对多的情况,如下图所示,这种情况也很常见,比如一个CPU要去访问多个Slave外设。
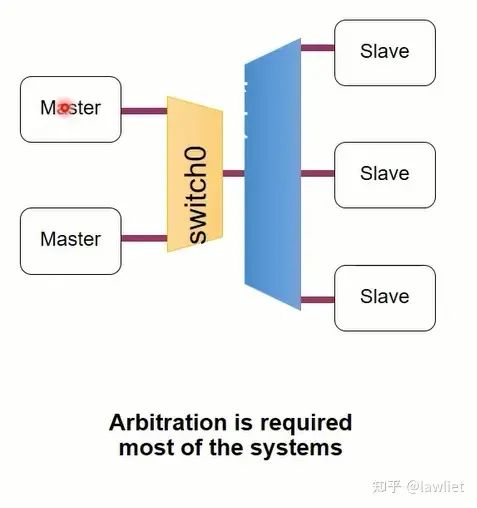
然后是多个Master访问多个Slave,这种情况就需要引入仲裁逻辑了,相对的设计也会更加复杂,此时多个Master共享Interconnect,相应的会影响到带宽。
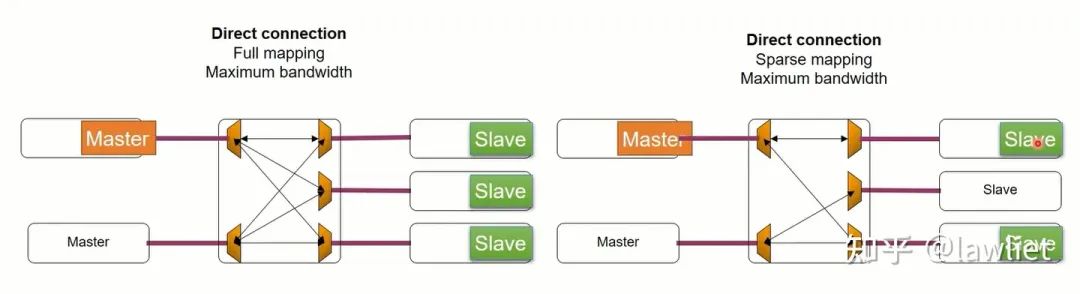
然后我们看一下下面的例子,左边是完全映射,即Master可以访问所有的Slave。右图则是部分映射,可以看到一个Master只能访问指定的Slave。部分映射可以简化逻辑设计,节约面积,让能跑的主频更高一点。实际上也不需要每个Master都能访问每个Slave。根据自己的需求来就行。
接下来我们看一下如果想设计一个好的互连,需要满足以下的特点:
支持多个Master和多个Slave
扩展灵活,可复用性强
时序好,从Interconnect本身去解决timing violation的问题
3、仲裁和时序收敛问题
接下来我们看一下仲裁相关的问题。仲裁本身是个很复杂的问题,这里只简单介绍。当多个Master需要访问同一个Slave的时候,这个时候就需要选择其中的一个。这里讲两种仲裁机制,Least Recently Granted和Round Robin仲裁机制。
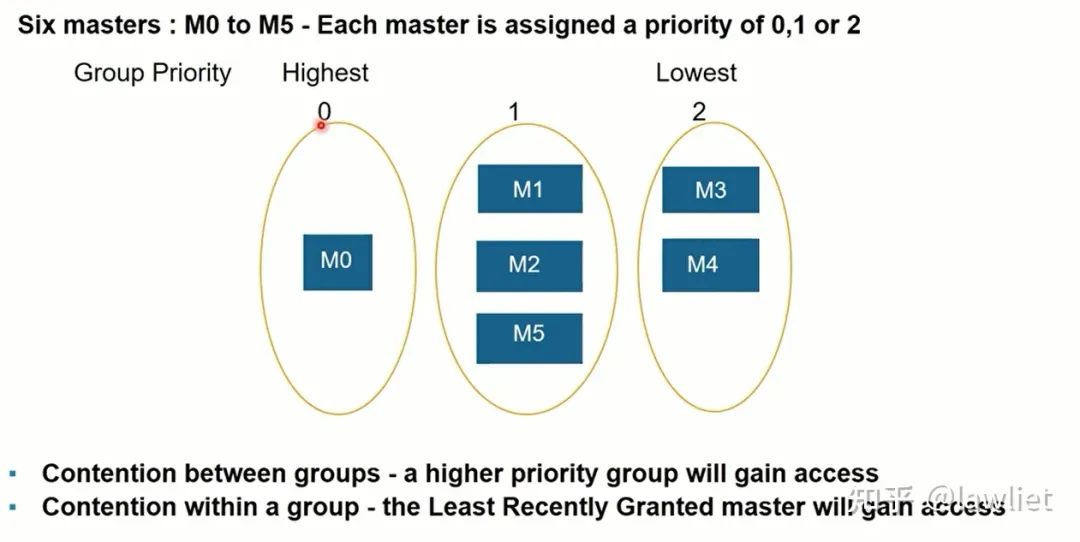
首先看一下Least Recently Granted仲裁:这个和Cache替换中的LRU差不多,我们一开始会分好组,组和组之间是有固定优先级区别的,高优先级的总是会获得仲裁。对于同一个组的而言,我们会让最近没有被授权的Master获得仲裁权,因此我们需要有一个寄存器去记录历史信息,也可以用状态机实现。
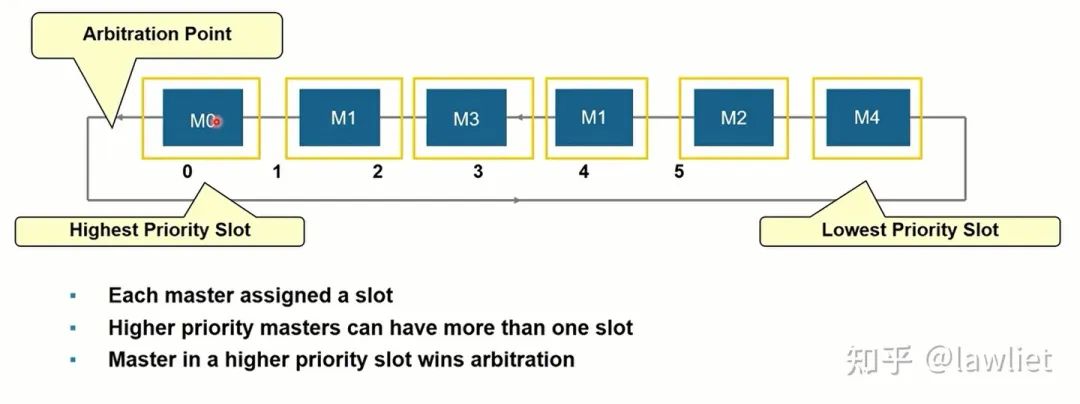
然后是Round Robin仲裁机制,这种仲裁机制下所有的Master的优先级都是相同的,采用轮询的方式进行仲裁,相应的也要进行记录历史信息,以决定如何获得仲裁。如下图所示,我们甚至可以用移位寄存器实现,下图是带Weight的Round Robin,可以看到M1占据了2个SLOT。因此使用频率是其它Master的两倍。
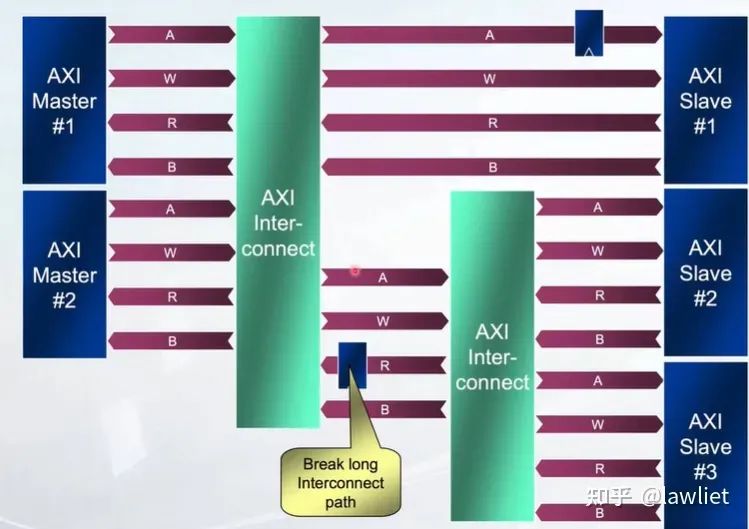
我们再看一下时序如何收敛,因为AXI本身采用握手机制,因此实际上非常灵活,晚了一个周期早了一个周期都无所谓,只要满足基本的各通道间依赖关系即可。没有AHB和APB那样的硬性1T Cycle delay的要求。因此我们可以在critical path上插入寄存器,以优化时序。
一般是有三种方式,打断Valid,打断Ready或者都打断。在IC设计中,无论使用的是否是AXI总线,只要用Valid和Ready握手机制来传递数据,都可以使用该方法让时序收敛,不一定是局限于某个总线协议。大家完全可以将其用在模块内部和模块与模块间的流传输。
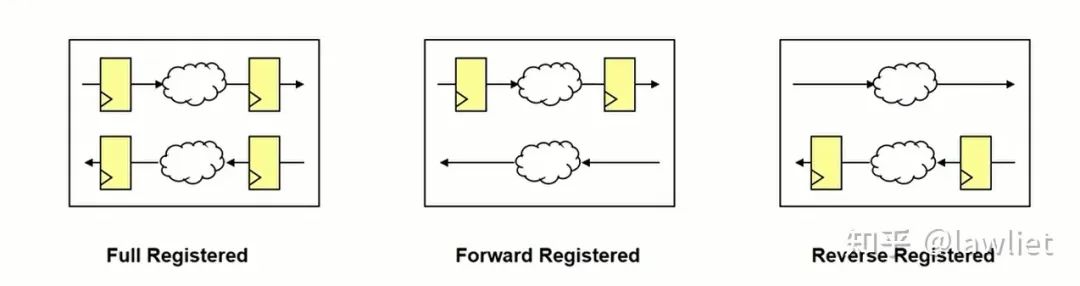
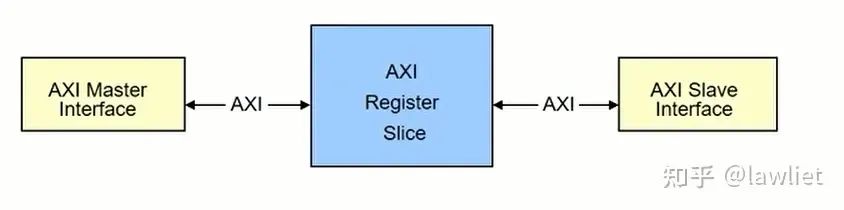
上面这种机制用在总线上,一般称之为Register Slice。先说说Slice的作用,在SoC中,如果Master和Slave的距离比较远,那么它们之间的bus信号要满足timing就可能有点困难,比如AXI中的 ARADDR、ARVALID这些信号从Master出来,要去很远的Slave,那么中间就要加很多的buffer,这引入的buffer delay就可能导致我们希望的timing不满足。这个时候就需要插入slice,给每个控制信号在中间加一级寄存器,把较长的走线缩短。当然插入的slice依然要保持bus的协议标准。简单来说,一个slice就是下面中间的那个模块。
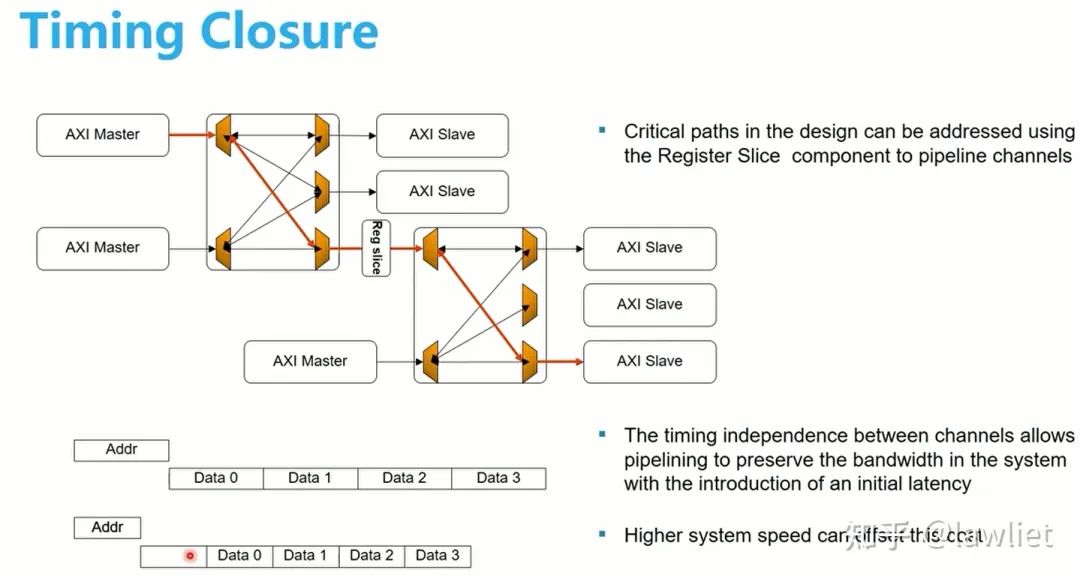
我们看一下在Register插入的位置,可以如下图所示(其实有很多可以插入的位置)。一般AXI各个通道是分开的,我们在哪个通道加入register slice,相应的就会晚了一拍,实际上晚了一拍完全不影响逻辑功能。
审核编辑:刘清
-
寄存器
+关注
关注
31文章
5625浏览量
130694 -
DDR
+关注
关注
11文章
764浏览量
69690 -
Cache
+关注
关注
0文章
130浏览量
29835 -
ACP
+关注
关注
0文章
9浏览量
8131 -
AXI总线
+关注
关注
0文章
68浏览量
14795
原文标题:深入理解AMBA总线之AXI设计的关键问题
文章出处:【微信号:Rocker-IC,微信公众号:路科验证】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AMBA总线概述
学习架构-AMBA AXI简介
AMBA3.0 AXI总线接口协议的研究与应用
AXI 总线交互分为 Master / Slave 两端
AMBA3.0 AXI总线接口协议的研究与应用
AMBA 3.0 AXI总线接口协议的研究与应用
基于AMBA总线介绍
深度解读AMBA、AHB、APB、AXI总线介绍及对比
介绍AMBA2.0总线
Xilinx FPGA AXI4总线(一)介绍【AXI4】【AXI4-Lite】【AXI-Stream】

漫谈AMBA总线-AXI4协议的基本介绍
NVMe简介之AXI总线



评论