 详细分析算力网络的发展
详细分析算力网络的发展

2023年12月底,由国家发展改革委、国家数据局、中央网信办、工业和信息化部、国家能源局五部门联合印发的《关于深入实施“东数西算”工程 加快构建全国一体化算力网的实施意见》正式公布。
算力网络是未来数字经济发展的核心基础设施。要想实现算力网络的伟大愿景,还有非常多的底层技术挑战需要解决。
接下来若干篇系列文章,“软硬件融合”公众号将从技术的视角,详细分析算力网络的发展。
本篇是系列文章的第一篇,算力提升综述。
01.宏观算力综述
算力和性能的区别在哪里?性能是一个微观话题,通常的说法是“芯片的性能”,较少说“芯片的算力”(随着算力的概念深入人心,也有不少人采用单芯片算力的算法)。同时,算力是一个宏观概念,比如评价一个数据中心,通常则采用“算力”这个说法,很少会用“性能”这个说法。
总之,算力和性能本质上是一体的,区别在于性能是微观概念,算力是宏观概念。那么算力和性能之间的联系是什么?
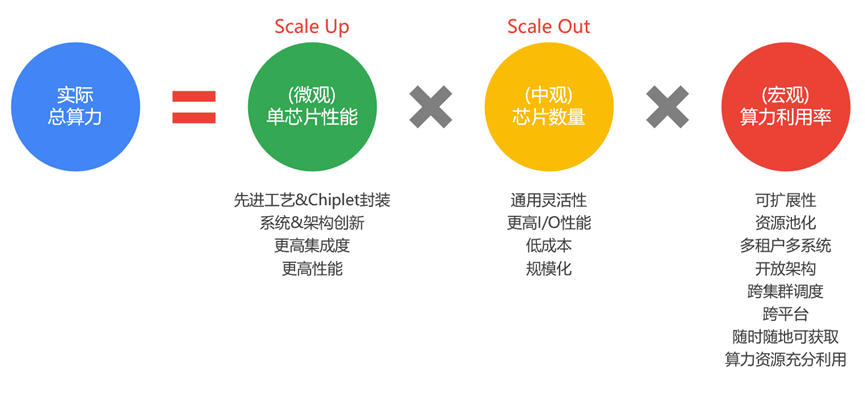
如上图所示,我们定性分析,可以在性能和算力之间构建一个关联的公式。从上述公式可以看到,要想提升宏观的实际总算力,可以通过三个方法:
方法一,Scale Up方式,提升单芯片的性能。一方面底层先进工艺和Chiplet封装支撑,另一方面越来越多的大算力场景需求,都驱动着在系统架构和微架构方面的创新,来实现单芯片层次更高的性能。这是算力提升最本质的做法。
方法二,Scale Out方式,提升芯片落地的规模/数量。通过增加芯片落地规模的方式提升总算力,比较好理解。挑战在于,如何让芯片更好地增加数量?芯片要想大规模落地:需要覆盖非常多的业务场景和业务迭代,这就需要芯片具有非常高的通用性;此外,芯片需要支持更大规模的集群计算。
方法三,则是提高算力利用率。提升算力利用率有很多方法,例如,资源扩展性、资源池化、开放架构等等。算力网络,是提升算力利用率的综合解决方案。
本系列文章聚焦算力网络,因此,篇幅分配会有很大不同。本篇文章中,将简要介绍提升算力的三种方式。
02.如何提升单芯片性能?

定性的分析,一个芯片的性能有三个维度:
维度一,指令复杂度。依据指令复杂度,典型的处理器引擎分为CPU、协处理器、GPU、FPGA、DSA和ASIC六大类。理论上,指令复杂度越高,性能越好。但实际上,需要考虑系统的通用性,以及目标工作任务的灵活性特征,来选择合适的处理器引擎。
维度二,运行频率。运行频率提升,主要是先进工艺,以及更复杂的流水线设计。
维度三,并行度。提高并行度比较好理解,并行也主要有同构并行、(两个处理器的)异构并行和(三个以上)更多异构的并行。
这三个维度里,指令复杂度提升和运行频率提升,都受到到各种因素的制约,真正对性能影响最大的则是并行度。提升并行度,不是简单的复制,而是需要全面考虑系统工作任务特征,寻找合适的处理引擎,实现复杂的并行计算:
同构并行,仅指CPU同构并行(其他处理器无法单独存在,需要CPU协助),摩尔定律已经失效,CPU并行性能有局限。
异构并行,指CPU+其他加速处理器的并行计算,异构并行是两类处理器的协同计算。
异构融合并行,指的是CPU+两种以上不同类型或子类型的处理器组成的计算架构。因为处理器增多,则需要考虑各个处理器之间的协同问题。因此,异构融合计算,中心在于处理器之间的深度协作和融合。
03.如何提升芯片的落地规模?
通用灵活性
芯片只有大规模落地,才能显著地提升宏观算力;不能落地芯片,即使性能再高,与宏观算力的提升也毫无意义。芯片要想大规模落地,一定是要覆盖非常多的业务场景,以及非常多的业务迭代。这样,势必需要芯片具有非常高的通用灵活性。 同时,芯片大规模落地,成本也是一个非常重要的因素。跟小芯片相比,大算力芯片的成本主要是前期的研发投入的均摊成本,芯片实际的生产成本反而占比相对较少。只有实现了相对通用的芯片设计,才能覆盖更多的场景和迭代,才能摊薄成本。成本下降之后,反过来,进一步促进芯片的大规模落地。
高性能网络
与此同时,大算力芯片,需要支持大规模集群和跨集群的计算。更多计算节点组成的集群/跨集群计算,内部流量占据绝大部分。 以目前流行的大模型计算集群为例,其东西向(内部)流量占比超过96%,南北向(外网)流量占比仅有3%左右。并且,随着集群规模的进一步扩大,南北向流量占比仍在进一步减少。 此外,随着系统规模的扩大,南北向的流量也是逐渐增加的。两相叠加,需要个体的芯片的网络带宽指数级提升,同时需要支持高效的内网和外网高性能网络。 总之,只有实现了足够的通用灵活性,以及高性能网络,才能支撑更高性能更高效率的超大规模的集群/跨集群计算,才能真正支撑宏观算力的显著提升,与此同时降低算力的成本。
04.如何提升算力利用率?
如果每个计算节点都是孤岛,即使某一个节点算力利用率很高,但更多的节点可能处于闲置或者低利用率状态,宏观地看,其算力利用率必然很低。要想真正提升算力利用率,首先势必需要把计算节点池化,形成算力资源池,才好谈高利用率的问题。
我们来系统分析一下如何有效地提升算力利用率。
资源可扩展性
资源可扩展性是一个非常重要的前提条件。 以CPU为例,通过虚拟化,一个物理的CPU核可以分为数以百计的逻辑CPU核,一个逻辑核可以当作CPU的最小粒度;同时,一个CPU芯片有数十个甚至上百个CPU核,常见的服务器通常有1-8个CPU芯片,并且还有众多服务器组成的计算集群。因此,CPU是可以从1个逻辑核扩展到成千上万的逻辑核的。这就是CPU极致可扩展性的体现。 其他的资源,如各类GPU、DSA等各类加速器计算资源、内存(Memory)资源、网络I/O资源、存储(Storage)I/O资源等。这些资源,也需要像CPU一样,具有非常好的扩展性。
资源池化
资源具有足够好的可扩展性,物理的资源通过合适粒度进行逻辑切分,并且跨物理资源、跨芯片、跨计算节点,甚至跨集群的资源资源可以组成一个整体,最终形成统一的宏观资源池。只有形成足够好的可扩展性才能支持灵活的资源池化和资源的灵活分配。
多租户多系统
多租户多系统是云计算非常重要的特征,通过多租户多系统实现资源的共享和成本分摊,以此来提高算力利用率和降低成本。
开放架构
随着CPU的性能瓶颈,越来越多的异构算力成为算力提升的主力。即使某个处理器具有足够高的可扩展性,但一种架构的资源,就意味着一个独立的资源池。这样,多样性的异构算力,会导致架构和生态的碎片化。通过开放架构,可以尽可能地实现架构的收敛,才能最大化地发挥资源池化的价值。
跨集群调度
算力网络,最核心的价值在于把非常多的各种计算集群连接到一起。因此跨集群的资源共享和业务调度是必然要支持的能力。算力网络,需要实现跨不同的集群、跨不同的数据中心、跨云网边端。
跨平台
随着异构的资源越来越多,从一个计算阶段迁移到本集群或者其他集群其他计算节点的时候,它的资源种类不一定和当前节点资源一致。这样,对业务能力跨不同架构处理器运行提出了更高的要求。比如,业务可以跨x86、ARM和riscv CPU处理器运行,业务还可以跨CPU、GPU、DSA处理器运行,等等。
便利性,随时随地可获取
相比传统自建机房,云计算已经实现了算力的方便获取。但还不够。随着AI大模型、自动驾驶、元宇宙XR等各类大算力场景越来越多,对算力的多样性要求也越来越大,云端算力、多层次的边缘算力,甚至更加便利的终端算力,都需要纳入算力网络的范畴,提供宏观的算力资源整合方案,方便用户随时随地轻松获取。 总结一下。通过上述这些方式,以及其他可能的上面没有提到的方式,来实现宏观算力资源的充分利用,从而为客户提供极致成本的海量算力。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
20415浏览量
255929 -
芯片
+关注
关注
463文章
54819浏览量
472106 -
网络
+关注
关注
14文章
8404浏览量
95836 -
算力
+关注
关注
2文章
1833浏览量
16892
原文标题:算力网络系列文章(一):算力提升综述
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录




评论