 8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理

前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。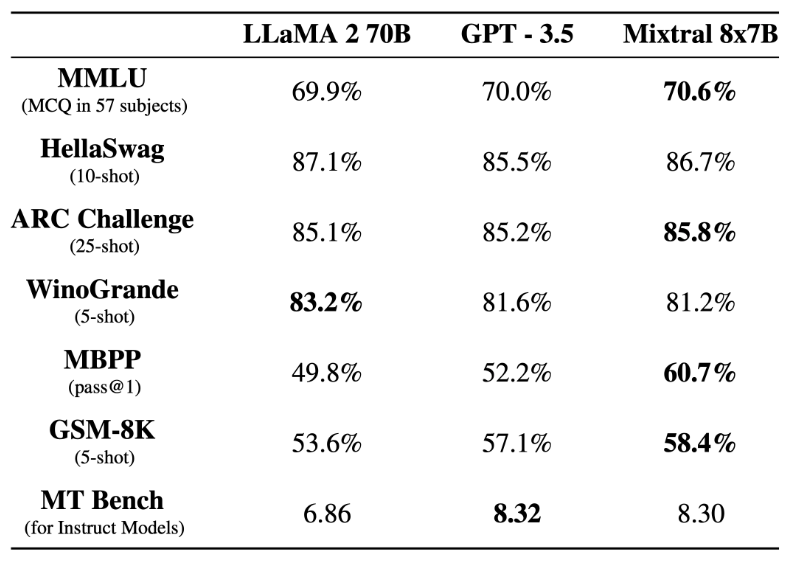
 ▲图源 https://mistral.ai/news/mixtral-of-experts/
▲图源 https://mistral.ai/news/mixtral-of-experts/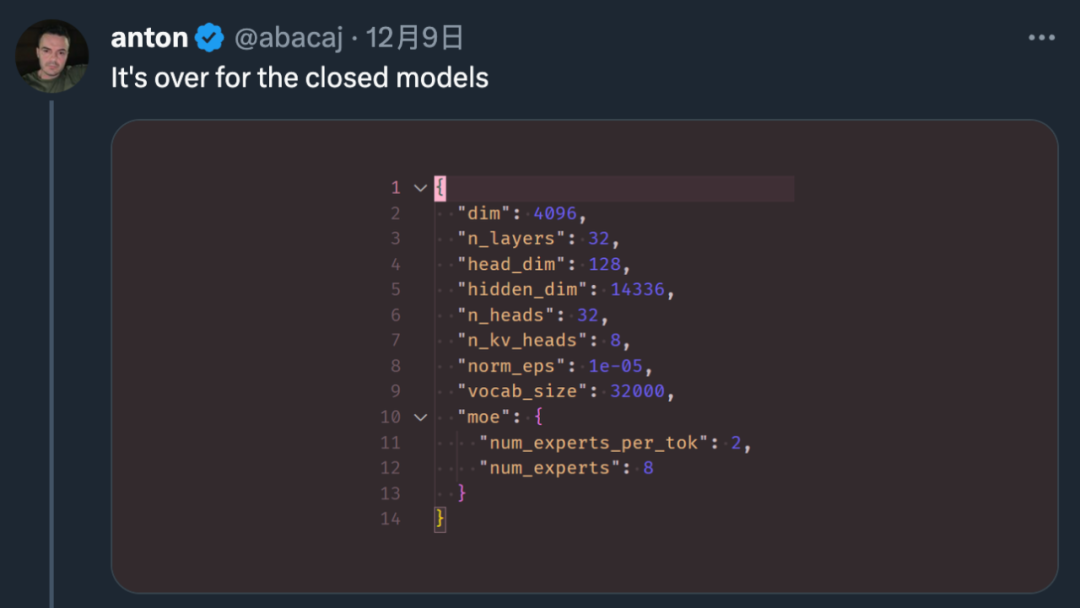
 ▲图源 https://twitter.com/reach_vb/status/1741175347821883502
▲图源 https://twitter.com/reach_vb/status/1741175347821883502 第三步是初始化 TextStreamer:
第三步是初始化 TextStreamer:
 第四步对输入进行 Token 化:
第四步对输入进行 Token 化:
 第五步生成:
第五步生成:
 当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。
当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。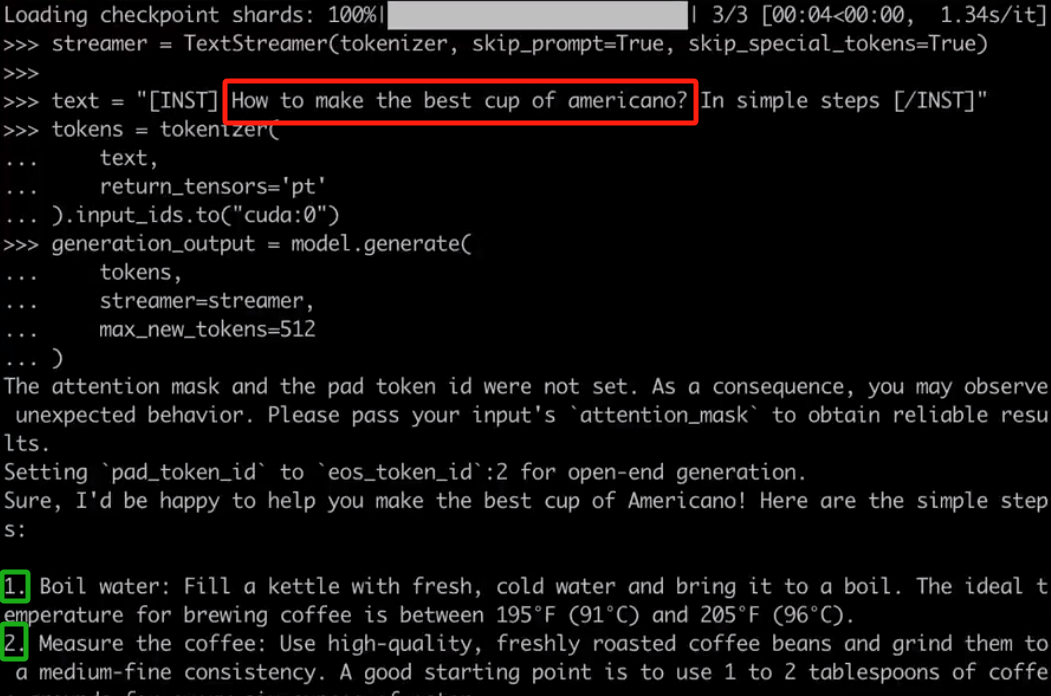


我们都知道,OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。Mistral 8x7B 的放出,无疑给广大开发者提供了一种「非常接近 GPT-4」的开源选项。
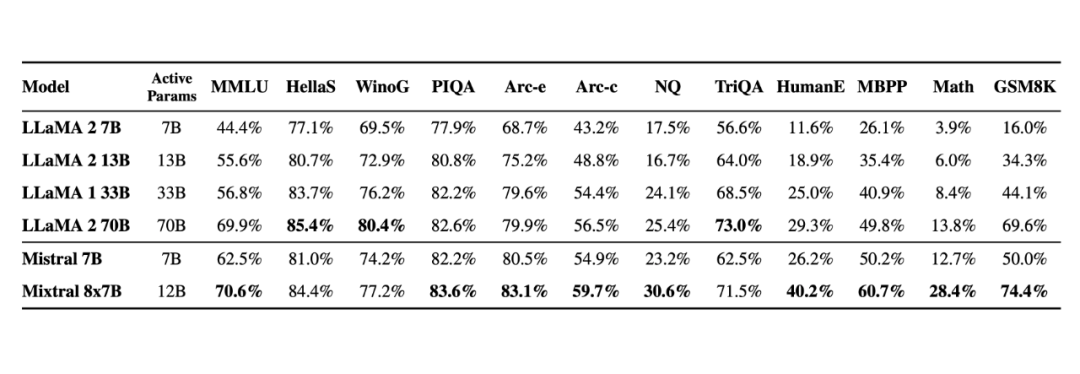
在基准测试中,Mistral 8x7B 的表现优于 Llama 2 70B,在大多数标准基准测试上与 GPT-3.5 不相上下,甚至略胜一筹。
▲图源 https://mistral.ai/news/mixtral-of-experts/随着这项研究的出现,很多人表示:「闭源大模型已经走到了结局。」
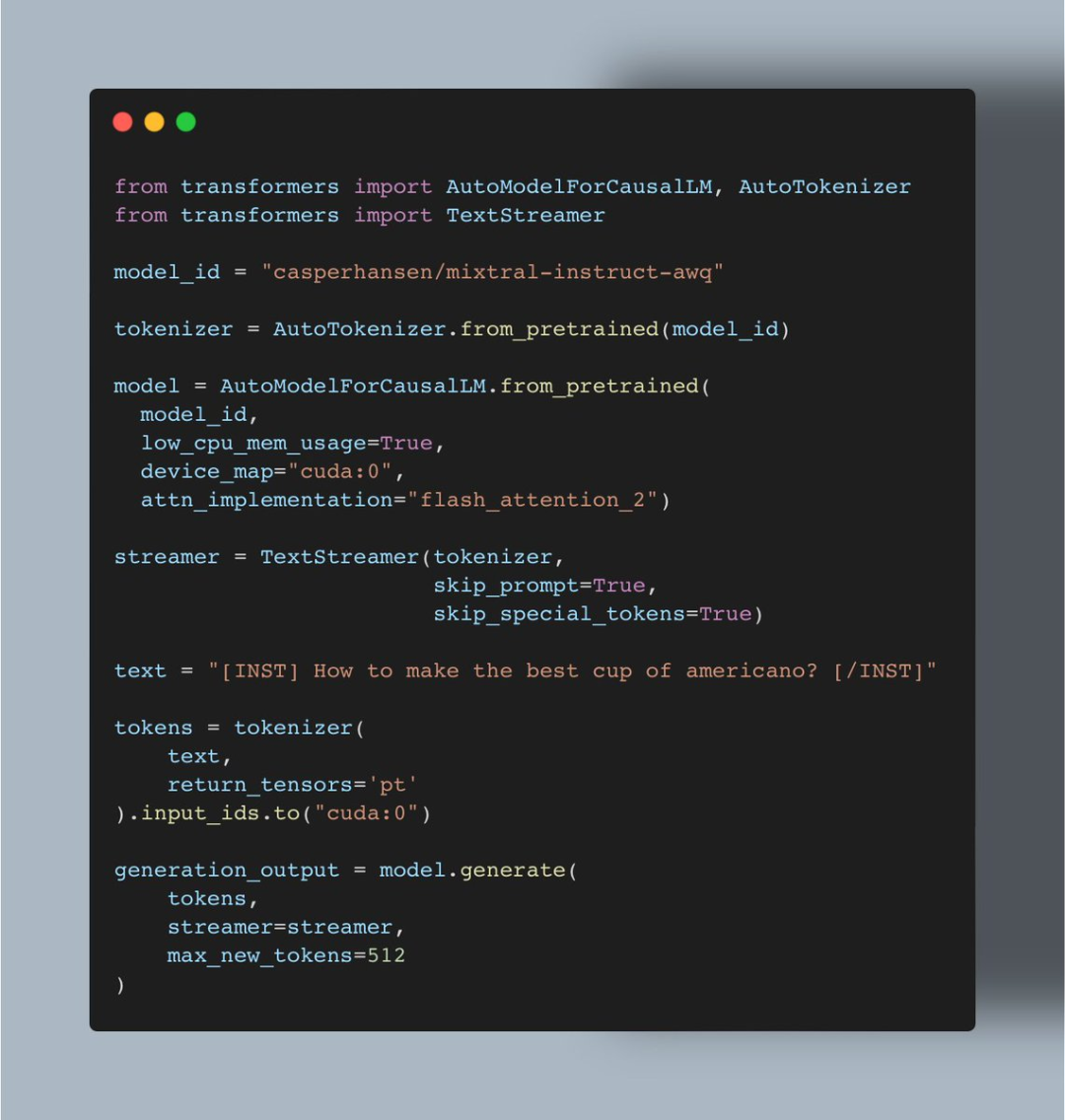
短短几周的时间,机器学习爱好者 Vaibhav (VB) Srivastav 表示:随着 AutoAWQ(支持 Mixtral、LLaVa 等模型的量化)最新版本的发布,现在用户可以将 Mixtral 8x7B Instruct 与 Flash Attention 2 结合使用,达到快速推理的目的,实现这一功能大约只需 24GB GPU VRAM、不到十行代码。
▲图源 https://twitter.com/reach_vb/status/1741175347821883502
AutoAWQ地址:
https://github.com/casper-hansen/AutoAWQ 操作过程是这样的: 首先是安装 AutoAWQ 以及 transformers:
pipinstallautoawqgit+https://github.com/huggingface/transformers.git
第二步是初始化 tokenizer 和模型:
第三步是初始化 TextStreamer:
第四步对输入进行 Token 化:
第五步生成:
当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。
项目中使用的代码:
Srivastav 表示上述实现也意味着用户可以使用 AWQ 运行所有的 Mixtral 微调,并使用 Flash Attention 2 来提升它们。 看到这项研究后,网友不禁表示:真的很酷。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
代码
+关注
关注
30文章
4976浏览量
74378 -
GPT
+关注
关注
0文章
372浏览量
16965 -
OpenAI
+关注
关注
9文章
1249浏览量
10279
原文标题:8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
AT89C51RD2/ED2:高性能8位Flash微控制器的深度剖析
AT89C51RD2/ED2:高性能8位Flash微控制器的深度剖析 在电子设计领域,微控制器是众多项目的核心。今天我们要深入探讨的是AT89C51RD
海光DCU完成阶跃星辰基座模型Step 3.5 Flash推理适配
近日,海光DCU正式完成对阶跃星辰旗舰开源基座模型Step 3.5 Flash的全流程适配与深度调优。得益于新一代海光DCU原生支持FP8精度、超越主流旗舰产品的更大显存等核心优势,高效完成Step 3.5 Flash FP
海光DCU完成Qwen3.5多模态MoE模型全量适配
近日,海光DCU完成Qwen3.5-397B MoE旗舰多模态模型、Qwen3.5-35B-A3B MoE多模态模型全量适配、精度对齐与推理
C8051F52x/F53x 8/4/2 kB ISP Flash MCU Family:高性能混合信号MCU的深度剖析
C8051F52x/F53x 8/4/2 kB ISP Flash MCU Family:高性能混合信号MCU的深度剖析 在电子设计领域,微
阶跃星辰开源Step 3.5 Flash,多家国产芯片厂商完成适配
。 Step 3.5 Flash模型聚焦于实时Agent工作流场景,采用稀疏MoE架构,总参数量高达1960亿,不过每个token仅激活约110亿参数。这种设计旨在兼顾推理速度与使用成本,为智能体(Agent)提供稳定可靠且
如何正确配置AG32 MCU,实现FLASH或者代码加密?
的SDK资料:海振远科技为客户提供丰富的开发资料和多款开发板可以选择,方便用户快速上手设计。
2、开发板资源:
二、如何正确配置AG32 MCU,实现FLASH或者
发表于 01-22 15:01
今日看点:小米正式发布并开源新模型 MiMo-V2-Flash;磷酸铁锂开启涨价潮
(激活15B)的 MoE 模型,通过引入 Hybrid 注意力架构创新 及 多层 MTP 推理加速,在多个 Agent 测评基准上进入全球开源模型 Top 2;
Qwen3-VL 4B/8B全面适配,BM1684X成边缘最佳部署平台!
算能BM1684X上完成Qwen3-VL4B/8B模型的适配,推理速度13.7/7.2tokens/s,使其成为边缘部署多模态大模型的最佳选择。近日,阿里千问正式开源Qwen3-VL系

【「DeepSeek 核心技术揭秘」阅读体验】基于MOE混合专家模型的学习和思考-2
= F.softmax(self.gate(x), dim=-1) # 这就是公式中的 p_i^c
# 2. 计算每个专家的输出
expert_outputs = []
for expert
发表于 08-23 17:00
杭州灵汐类脑智算集群实现大模型快速推理
据悉,“杭州灵汐类脑智算集群”已于7月底实现了大模型快速推理API的企业服务试运行。该集群由杭州灵汐类脑科技有限公司牵头搭建运营,中国电信、中国电子科技南湖研究院以及脑启社区作为合作方
华为宣布开源盘古7B稠密和72B混合专家模型
关键一步,为全球开发者、企业及研究人员提供了强大的技术支撑。 华为此次开源行动涵盖三大核心板块:盘古Pro MoE 72B模型权重与基础推理代码已率先上线开源平台;基于昇腾的超大规
华为正式开源盘古7B稠密和72B混合专家模型
关键举措,推动大模型技术的研究与创新发展,加速推进人工智能在千行百业的应用与价值创造。 盘古Pro MoE 72B模型权重、基础推理代码,已
具有载波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4 和 B7) skyworksinc
电子发烧友网为你提供()具有载波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4 和
发表于 06-19 18:35

润和软件StackRUNS异构分布式推理框架的应用案例
江苏润和软件股份有限公司(以下简称“润和软件”)自主研发的StackRUNS异构分布式推理框架已在实际场景中取得显著成效,成功应用于大型园区多模态模型演练及高校满血版DeepSeek-MoE 671B的运行,有效推动了大模型技术

代码革命的先锋:aiXcoder-7B模型介绍
国内开源代码大模型 4月9日aiXcoder宣布正式开源其7B模型Base版,仅仅过去一个礼拜,aiXcoder-7B在软件源代码托管服务平台GitHub上的Star数已超过




评论