 Google Cloud 推出 TPU v5p 和 AI Hypercomputer: 支持下一代 AI 工作负载
Google Cloud 推出 TPU v5p 和 AI Hypercomputer: 支持下一代 AI 工作负载

以下文章来源于谷歌云服务,作者 Google Cloud
Amin Vahdat
ML、系统与 Cloud AI 副总裁/总经理
Mark Lohmeyer
计算与 ML 基础设施副总裁/总经理
生成式 AI 模型正在迅速发展,提供了前所未有的精密性和功能。这项技术进展得以让各行各业的企业和开发人员能够解决复杂的问题,开启新的机遇之门。然而,生成式 AI 模型的增长也导致训练、调整和推理方面的要求变得更加严苛。过去五年来,生成式 AI 模型的参数每年增长十倍,如今的大模型具有数千亿甚至上万亿项参数,即使在最专业的系统上仍需要相当长的训练时间,有时需持续数月才能完成。此外,高效的 AI 工作负载管理需要一个具备一致性能、优化的计算、存储、网络、软件和开发框架所组成的集成 AI 堆栈。
为了应对这些挑战,我们很高兴宣布推出 Cloud TPU v5p,这是 Google 迄今为止功能、可扩展性、灵活性最为强大的 AI 加速器。长期以来,TPU 一直是训练和服务 AI 支持的产品的基础,例如 YouTube、Gmail、Google 地图、Google Play 和 Android。事实上,Google 刚刚发布的功能最强大的通用 AI 模型 Gemini 就是使用 TPU 进行训练和服务的。
此外,我们也宣布推出 Google Cloud AI Hypercomputer,这是一种突破性的超级计算机架构,采用集成系统,并结合了性能优化的硬件、开放软件、领先的 ML 框架和灵活的消费模式。传统方法通常是以零碎的组件级增强来解决要求严苛的 AI 工作负载,这可能会导致效率不佳和性能瓶颈。相比之下,AI Hypercomputer 采用系统级协同设计来提高 AI 训练、调整和服务的效率和生产力。
01
探索 Cloud TPU v5p
Google Cloud 目前功能最强大
可扩展能力最佳的 TPU 加速器
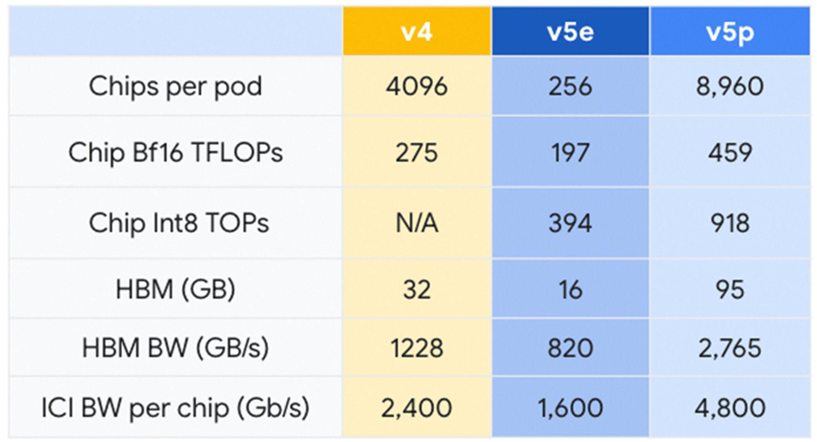
上个月,我们宣布全面推出 Cloud TPU v5e。相较于上一代 TPU v41,TPU v5e 的性价比提高了 2.3 倍,是我们目前最具成本效益的 TPU。而 Cloud TPU v5p 则是我们目前功能最强大的 TPU。每个 TPU v5p pod 由 8,960 个芯片组成,采用了我们带宽最高的芯片间互连 (Inter-chip Interconnect, ICI) 技术,以 3D 环形拓扑结构实现每芯片 4,800 Gbps 的速率。与 TPU v4 相比,TPU v5p 的每秒浮点运算次数 (FLOPS) 提高 2 倍以上,高带宽内存 (High-bandwidth Memory, HBM) 则增加 3 倍。
TPU v5p 专为性能、灵活性和可扩展性设计,相较于上一代 TPU v4,TPU v5p 训练大型 LLM 的速度提升 2.8 倍。此外,若搭配第二代 SparseCores,TPU v5p 训练嵌入密集模型的速度比 TPU v42 快 1.9 倍。
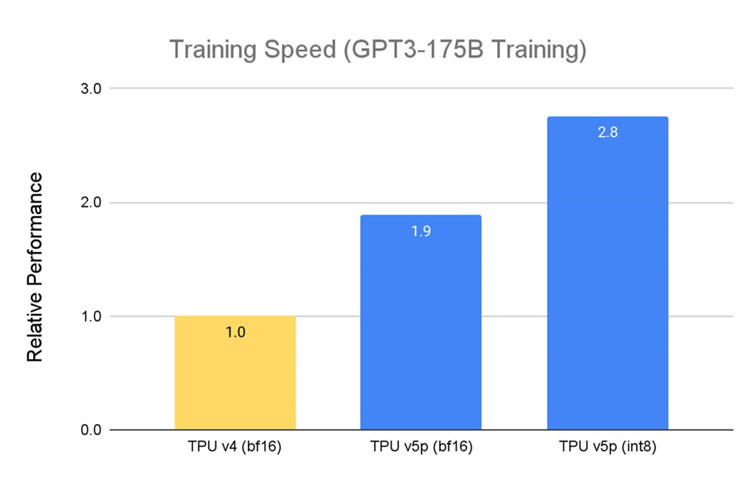
资料来源: Google 内部数据。截至 2023 年 11 月,GPT-3 1750 亿参数模型的所有数据均按每芯片 seq-len=2048 为单位完成标准化。
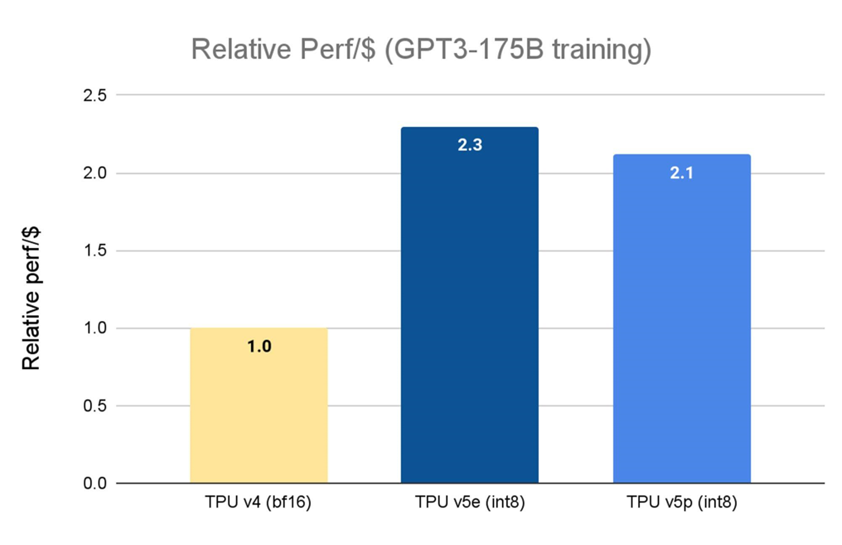
资料来源: TPU v5e 数据来自 MLPerf 3.1 Training Closed 的 v5e 结果;TPU v5p 和 v4 基于 Google 内部训练运行。截至 2023 年 11 月,GPT-3 1750 亿参数模型的所有数据均按每芯片 seq-len=2048 为单位完成标准化。并以 TPU v4:3.22 美元/芯片/小时、TPU v5e:1.2 美元/芯片/小时和 TPU v5p:4.2 美元/芯片/小时的公开定价显示每美元相对性能。
TPU v5p 不仅性能更佳,就每 Pod 的总可用 FLOPS 而言,TPU v5p 的可扩展能力比 TPU v4 高 4 倍,且 TPU v5p 的每秒浮点运算次数 (FLOPS) 是 TPU v4 的两倍,并在单一 Pod 中提供两倍的芯片,可大幅提升训练速度相关性能。
02
Google AI Hypercomputer
大规模提供顶尖性能和效率
实现规模和速度是必不可少的,但并不足以满足现代 AI/ML 应用程序和服务的需求。软硬组件必须组合相辅相成,组成一个易于使用、安全可靠的集成计算系统。Google 已针对此问题投入数十年的时间进行研发,而 AI Hypercomputer 正是我们的心血结晶。此系统集结了多种能协调运作的技术,能以最佳方式来执行现代 AI 工作负载。

性能优化硬件: AI Hypercomputer 以超大规模数据中心基础设施为基础构建,采用高密度足迹、水冷技术和我们的 Jupiter 数据中心网络技术,在计算、存储和网络功能上均能提供最佳性能。所有这一切都基于以效率为核心的各项技术,利用清洁能源和对水资源管理的坚定承诺,助力我们迈向无碳未来。
开放软件: AI Hypercomputer 使开发人员能够通过使用开放软件来访问我们性能优化的硬件,利用这些硬件调整、管理和动态编排 AI 训练和推理工作负载。
-
广泛支持主流 ML 框架 (例如 JAX、TensorFlow 和 PyTorch) 且提供开箱即用。如要构建复杂的 LLM,JAX 和 PyTorch 均由 OpenXLA 编译器提供支持。XLA 作为基础设施,支持创建复杂的多层模型。XLA 优化了各种硬件平台上的分布式架构,确保针对不同的 AI 场景高效开发易于使用的模型。
-
提供开放且独特的 Multislice Training 及 Multihost Inferencing 软件,分别使扩展、训练和提供模型的工作负载变得流畅又简单。若要处理要求严苛的 AI 工作负载,开发人员可将芯片数量扩展至数万个。
-
与 Google Kubernetes Engine (GKE) 和 Google Compute Engine 深度集成,实现高效的资源管理、一致的操作环境、自动扩展、自动配置节点池、自动检查点、自动恢复和及时的故障恢复。
灵活的消费模式: AI Hypercomputer 提供多种灵活动态的消费方案。除了承诺使用折扣 (Committed Used Discunts, CUD)、按需定价和现货定价等经典选项外,AI Hypercomputer 还通过 Dynamic Workload Scheduler 提供针对 AI 工作负载量身定制的消费模式。Dynamic Workload Scheduler 包含两种消费模式: Flex Start 模式可实现更高的资源获取能力和优化的经济效益;Calendar 模式则针对作业启动时间可预测性更高的工作负载。
03
利用 Google 的丰富经验
助力 AI 的未来发展
Salesforce 和 Lightricks 等客户已在使用 Google Cloud 的 TPU v5p 以及 AI Hypercomputer 来训练和服务大型 AI 模型——并发现了其中的差异:
G
C
"我们一直在使用 Google Cloud 的 TPU v5p 对 Salesforce 的基础模型进行预训练,这些模型将作为专业生产用例的核心引擎,我们看到训练速度获得了显著提升。事实上,Cloud TPU v5p 的计算性能比上一代 TPU v4 高出至少 2 倍。我们还非常喜欢使用 JAX 顺畅地从 Cloud TPU v4 过渡到 v5p。我们期待能通过 Accurate Quantized Training (AQT) 库,运用 INT8 精度格式的原生支持来优化我们的模型,进一步提升速度。"
——Salesforce 高级研究科学家
Erik Nijkamp
G
C
"凭借 Google Cloud TPU v5p 的卓越性能和充足内存,我们成功地训练了文本到视频的生成模型,而无需将其拆分成单独进程。这种出色的硬件利用率大大缩短了每个训练周期,使我们能够迅速开展一系列实验。能在每次实验中快速完成模型训练的能力加快了迭代速度,为我们的研究团队在生成式 AI 这个竞争激烈的领域带来宝贵优势。"
——Lightricks 核心生成式 AI 研究团队主管
Yoav HaCohen 博士
G
C
"在早期使用过程中,Google DeepMind 和 Google Research 团队发现,对于 LLM 训练工作负载,TPU v5p 芯片的性能比 TPU v4 代提高了 2 倍。此外,AI Hypercomputer 能为 ML 框架 (JAX、PyTorch、TensorFlow) 提供强大的支持和自动编排工具,使我们能够在 v5p 上更高效地扩展。搭配第二代 SparseCores,我们也发现嵌入密集型工作负载 (embeddings-heavy workloads) 的性能得到显著提高。TPU 对于我们在 Gemini 等前沿模型上开展最大规模的研究和工程工作至关重要。"
—— Google DeepMind 和 Google Research
首席科学家 Jeff Dean
在 Google,我们一直坚信 AI 能够帮助解决棘手问题。截至目前,大规模训练与提供大型基础模型对于许多企业来说都过于复杂且昂贵。现在,通过 Cloud TPU v5p 和 AI Hypercomputer,我们很高兴能将我们在 AI 和系统设计领域数十年的研究成果与我们的用户分享,以便他们能够更快、更高效、更具成本效益地运用 AI 加速创新。
1: MLPerf v3.1 Training Closed 的结果多个基准如图所示。资料日期:2023 年 11 月 8 日。资料来源:mlcommons.org。结果编号:3.1-2004。每美元性能并非 MLPerf 的评估标准。TPU v4 结果尚未经 MLCommons 协会验证。MLPerf 名称和标志是 MLCommons 协会在美国和其他国家的商标,并保留所有权利,严禁未经授权的使用。更多信息,请参阅 www.mlcommons.org。
2: 截至 2023 年 11 月,Google TPU v5p 内部资料:E2E 执行时间 (steptime)、搜索广告预估点击率 (SearchAds pCTR)、每个 TPU 核心批次大小为 16,384、125 个 vp5 芯片。
 点击屏末|阅读原文|即刻查看详细内容
点击屏末|阅读原文|即刻查看详细内容


原文标题:Google Cloud 推出 TPU v5p 和 AI Hypercomputer: 支持下一代 AI 工作负载
文章出处:【微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
-
谷歌
+关注
关注
27文章
6245浏览量
110269
原文标题:Google Cloud 推出 TPU v5p 和 AI Hypercomputer: 支持下一代 AI 工作负载
文章出处:【微信号:Google_Developers,微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI眼镜或成为下一代手机?谷歌、苹果等巨头扎堆布局
安森美SiC器件赋能下一代AI数据中心变革
Microchip推出下一代Switchtec Gen 6 PCIe交换芯片
vivo携手Google Cloud推动智能手机迈入AI新时代
《AI芯片:科技探索与AGI愿景》—— 深入硬件核心的AGI指南
传音携手Google Cloud打造下一代AI智能生态
是德科技与Heavy Reading合作发布2025年AI集群网络报告
安森美携手英伟达推动下一代AI数据中心发展
NVIDIA 采用纳微半导体开发新一代数据中心电源架构 800V HVDC 方案,赋能下一代AI兆瓦级算力需求
光庭信息推出下一代整车操作系统A²OS
Google推出第七代TPU芯片Ironwood
谷歌第七代TPU Ironwood深度解读:AI推理时代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大规模思考与推理的 AI 模型新引擎
NetApp与Google Cloud合作,简化云端高性能工作负载的扩展
Arm技术助力Google Axion处理器加速AI工作负载推理





 工商网监
工商网监
评论