 【AI简报20230908期】正式亮相!打开腾讯混元大模型,全部都是生产力
【AI简报20230908期】正式亮相!打开腾讯混元大模型,全部都是生产力

1. 1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
原文:https://mp.weixin.qq.com/s/B3KycAYJ2bLWctvoWOAxHQ
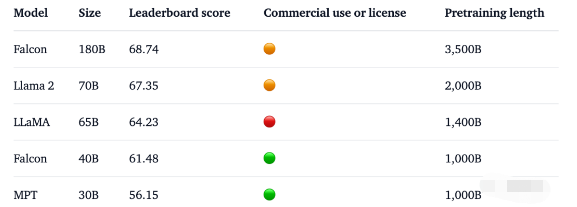
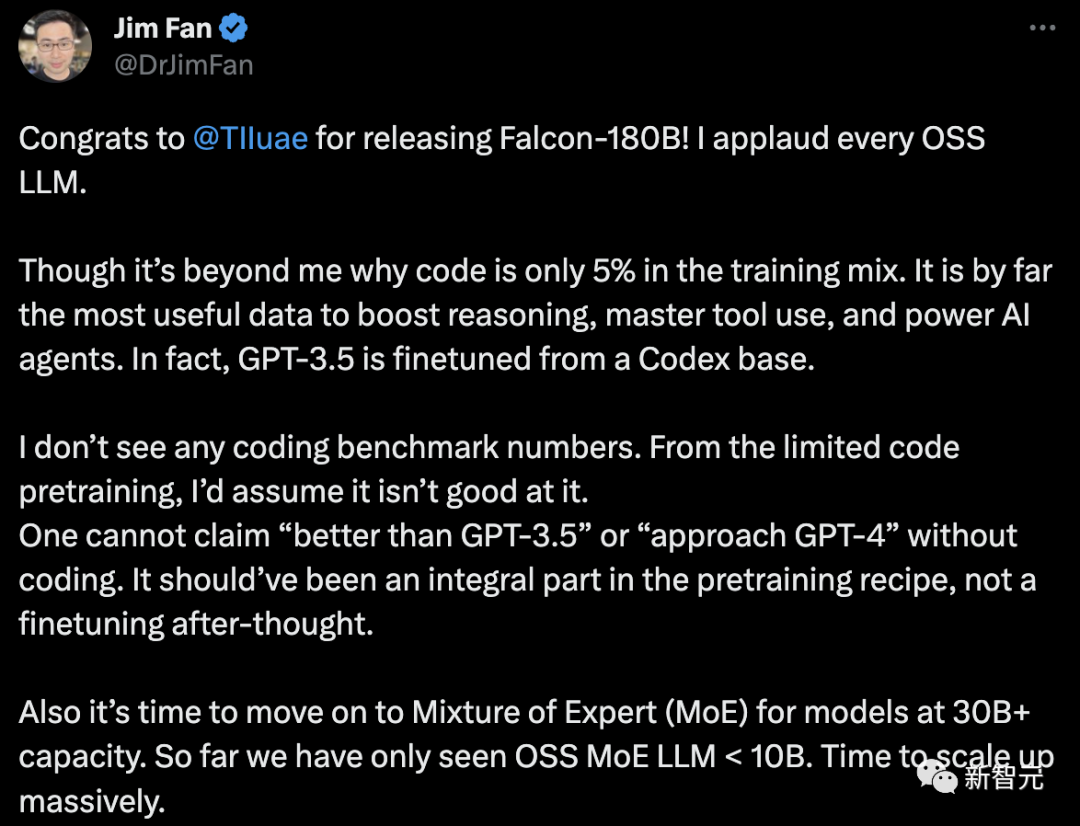
一夜之间,世界最强开源大模型Falcon 180B引爆全网!
1800亿参数,Falcon在3.5万亿token完成训练,直接登顶Hugging Face排行榜。
基准测试中,Falcon 180B在推理、编码、熟练度和知识测试各种任务中,一举击败Llama 2。

2. Meta的Flamera头显对增强现实有了新的愿景
原文:https://mp.weixin.qq.com/s/UepWwW7D03_jISTsSmjwnAMeta的最新原型头显Flamera像是直接从科幻动作片中来的一样,它在Siggraph 2023上引起了人们的注意 —— Flamera在那里获得了令人垂涎的Best in Show奖。据悉,Flamera原型头显展示了接近人眼分辨率和全新的"透视"真实世界的技术。该原型或许为VR、MR和AR的未来铺平了道路。头显原型展示的技术突破引发了人们的兴趣和关注。Moor Insights&Strategy副总裁兼首席分析师Ansel Sag表示:“这绝对是我见过的质量最好的(增强现实)实现透视真实世界的全新方法。”

3. 腾讯混元大模型正式亮相,我们抢先试了试它的生产力
原文:https://mp.weixin.qq.com/s/xuk77KHJHhoh6kWkf-4AKg上个星期,国内首批大模型备案获批,开始面向全社会开放服务,大模型正式进入了规模应用的新阶段。在前期发布应用的行列中,有些科技巨头似乎还没有出手。很快到了 9 月 7 日,在 2023 腾讯全球数字生态大会上,腾讯正式揭开了混元大模型的面纱,并通过腾讯云对外开放。作为一个超千亿参数的大模型,混元使用的预训练语料超过两万亿 token,凭借多项独有的技术能力获得了强大的中文创作能力、复杂语境下的逻辑推理能力,以及可靠的任务执行能力。





4. GitHub热榜登顶:开源版GPT-4代码解释器,可安装任意Python库,本地终端运行
原文:https://mp.weixin.qq.com/s/TiSVeZOeWourVJ60yyyygwChatGPT的代码解释器,用自己的电脑也能运行了。刚刚有位大神在GitHub上发布了本地版的代码解释器,很快就凭借3k+星标并登顶GitHub热榜。不仅GPT-4本来有的功能它都有,关键是还可以联网。
- 3小时只能发50条消息
- 支持的Python模块数量有限
- 处理文件大小有限制,不能超过100MB
- 关闭会话窗口之后,此前生成的文件会被删除

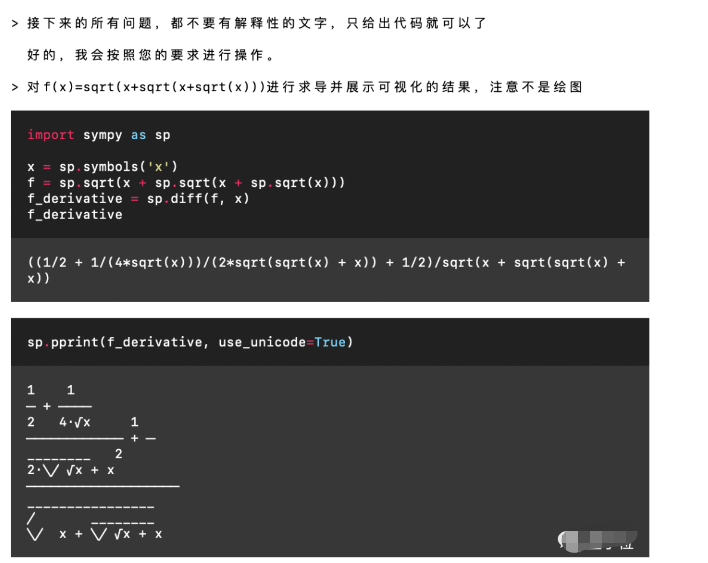
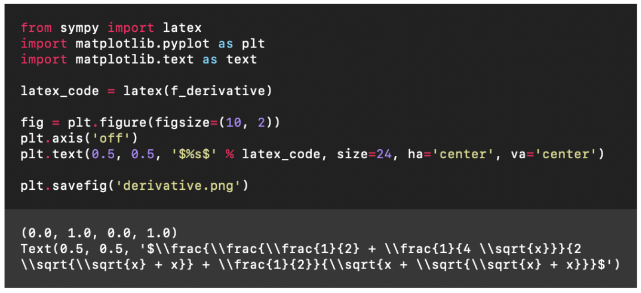
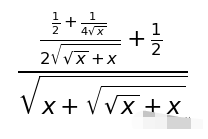
结果是正确的!接下来就要进入重头戏了,来看看这个代码解释器的联网功能到底是不是噱头:比如我们想看一下最近有什么新闻。更多的内容请点击原文,谢谢。
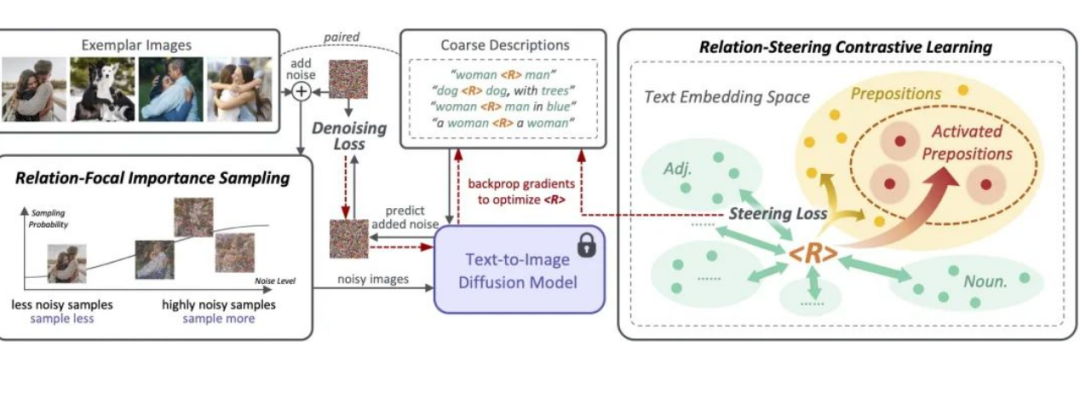
5. ReVersion|图像生成中的Relation定制化
原文:https://mp.weixin.qq.com/s/7W80wWf2Bj68MnC8NEV9cQ新任务:Relation Inversion今年,diffusion model和相关的定制化(personalization)的工作越来越受人们欢迎,例如DreamBooth,Textual Inversion,Custom Diffusion等,该类方法可以将一个具体物体的概念从图片中提取出来,并加入到预训练的text-to-image diffusion model中,这样一来,人们就可以定制化地生成自己感兴趣的物体,比如说具体的动漫人物,或者是家里的雕塑,水杯等等。现有的定制化方法主要集中在捕捉物体外观(appearance)方面。然而,除了物体的外观,视觉世界还有另一个重要的支柱,就是物体与物体之间千丝万缕的关系(relation)。目前还没有工作探索过如何从图片中提取一个具体关系(relation),并将该relation作用在生成任务上。为此,我们提出了一个新任务:Relation Inversion。
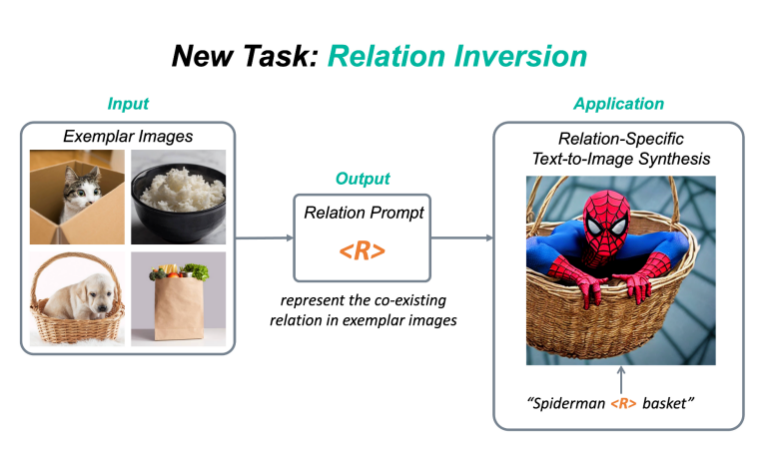

论文:https://arxiv.org/abs/2303.13495代码:https://github.com/ziqihuangg/ReVersion主页:https://ziqihuangg.github.io/projects/reversion.html视频:https://www.youtube.com/watch?v=pkal3yjyyKQDemo:https://huggingface.co/spaces/Ziqi/ReVersionReVersion框架作为针对Relation Inversion问题的首次尝试,我们提出了ReVersion框架:
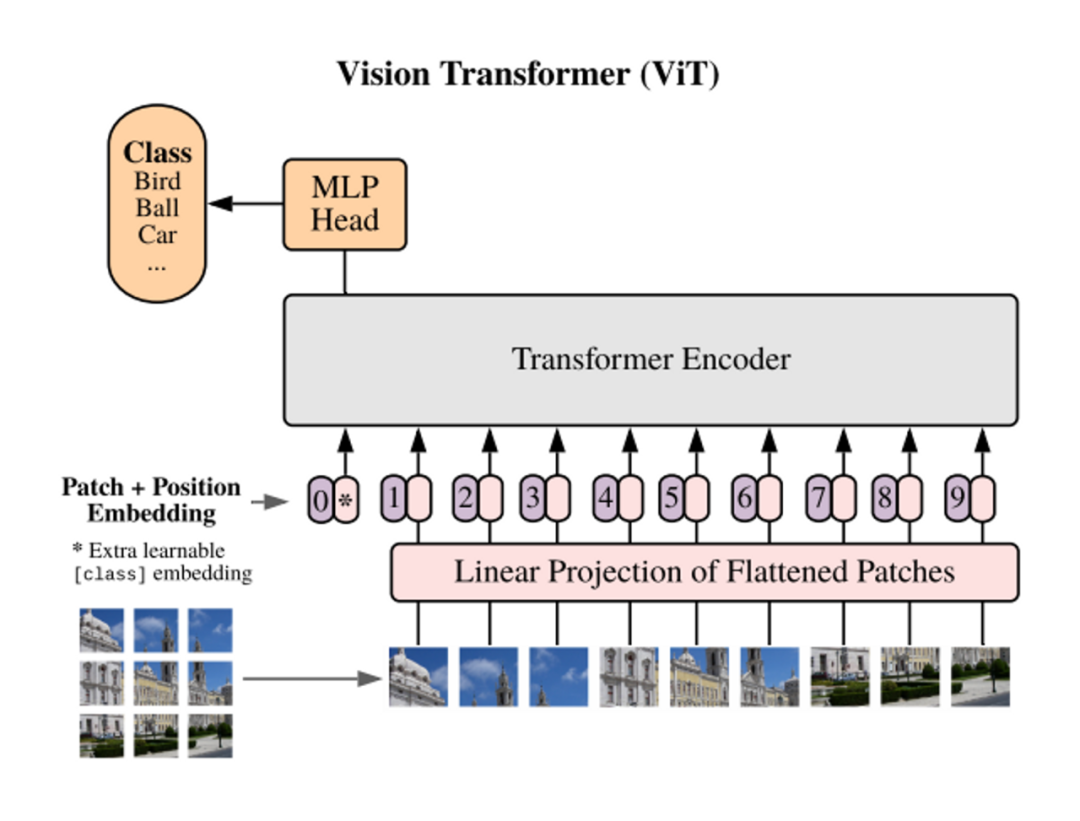
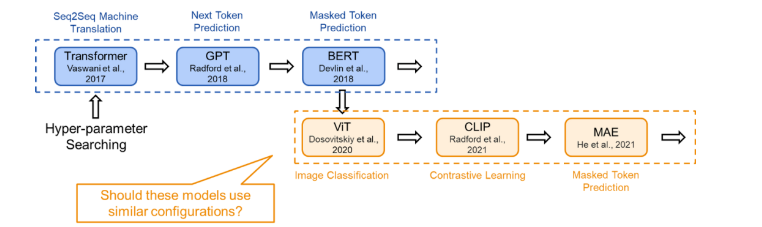
6. 神经网络大还是小?Transformer模型规模对训练目标的影响
原文:https://mp.weixin.qq.com/s/el_vtxw-54LVnuWzS1JYDw
论文链接:https://arxiv.org/abs/2205.1050501 TL;DR本文研究了 Transformer 类模型结构(configration)设计(即模型深度和宽度)与训练目标之间的关系。结论是:token 级的训练目标(如 masked token prediction)相对更适合扩展更深层的模型,而 sequence 级的训练目标(如语句分类)则相对不适合训练深层神经网络,在训练时会遇到 over-smoothing problem。在配置模型的结构时,我们应该注意模型的训练目标。一般而言,在我们讨论不同的模型时,为了比较的公平,我们会采用相同的配置。然而,如果某个模型只是因为在结构上更适应训练目标,它可能会在比较中胜出。对于不同的训练任务,如果没有进行相应的模型配置搜索,它的潜力可能会被低估。因此,为了充分理解每个新颖训练目标的应用潜力,我们建议研究者进行合理的研究并自定义结构配置。02 概念解释下面将集中解释一些概念,以便于快速理解:2.1 Training Objective(训练目标)
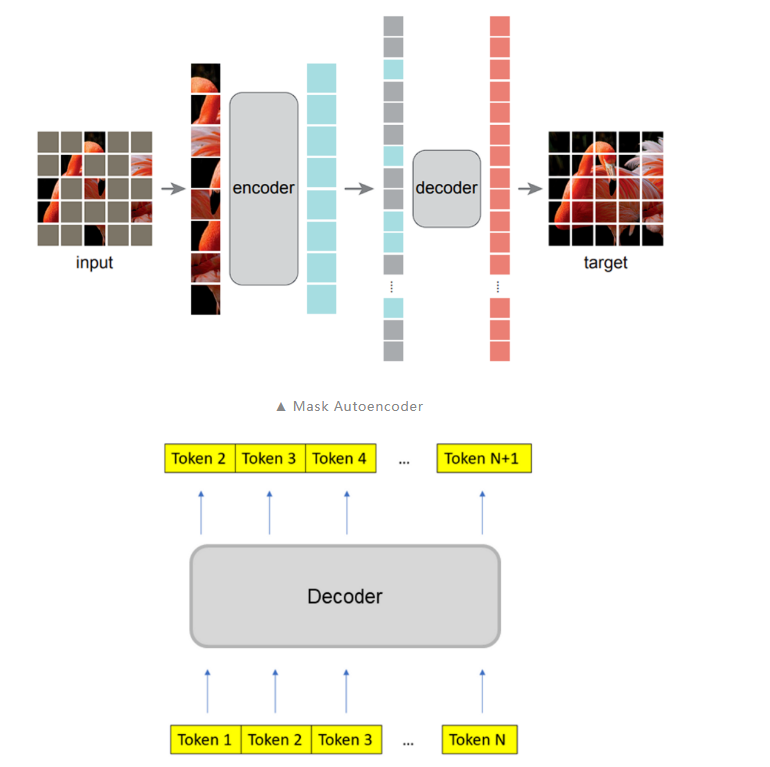 训练目标是模型在训练过程中完成的任务,也可以理解为其需要优化的损失函数。在模型训练的过程中,有多种不同的训练目标可以使用,在此我们列出了 3 种不同的训练目标并将其归类为 token level 和 sequence level:
训练目标是模型在训练过程中完成的任务,也可以理解为其需要优化的损失函数。在模型训练的过程中,有多种不同的训练目标可以使用,在此我们列出了 3 种不同的训练目标并将其归类为 token level 和 sequence level:- sequence level:
-
- classification 分类任务,作为监督训练任务。简单分类(Vanilla Classification)要求模型对输入直接进行分类,如对句子进行情感分类,对图片进行分类;而 CLIP 的分类任务要求模型将图片与句子进行匹配。
- token level:(无监督)
-
- masked autoencoder:masked token 预测任务,模型对部分遮盖的输入进行重建
- next token prediction:对序列的下一个 token 进行预测
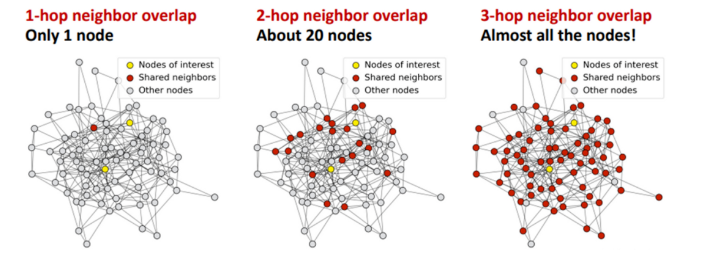
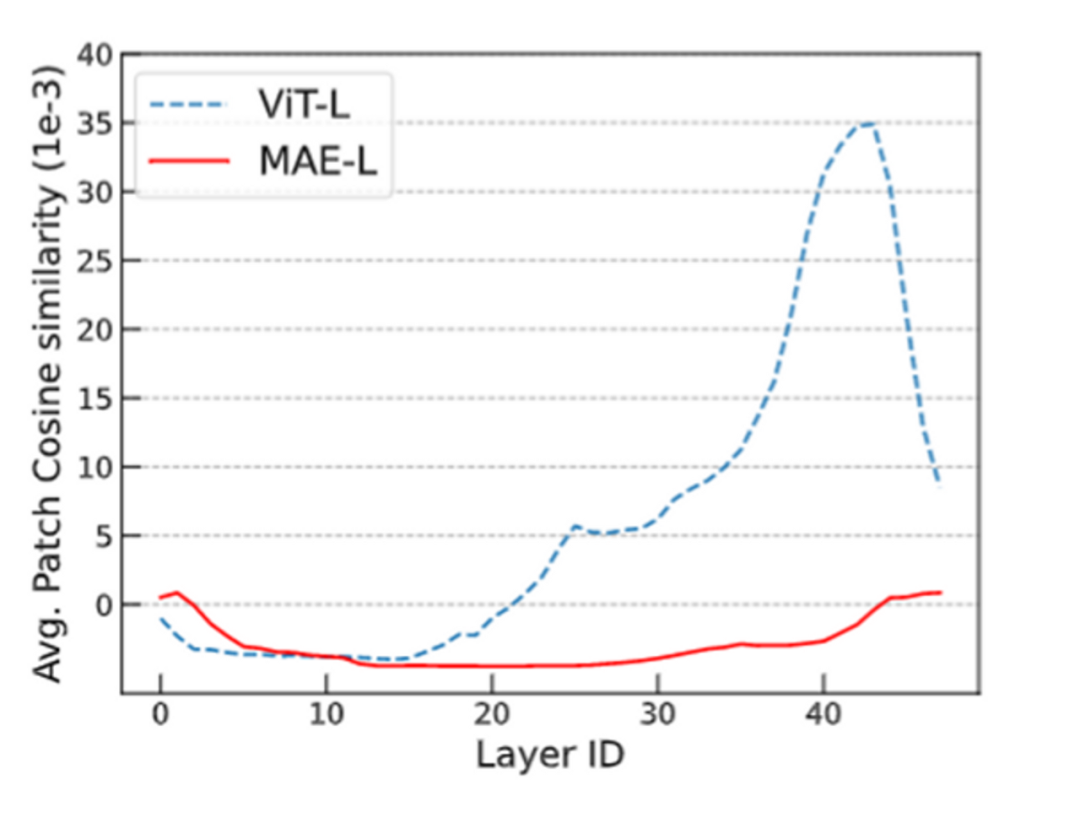
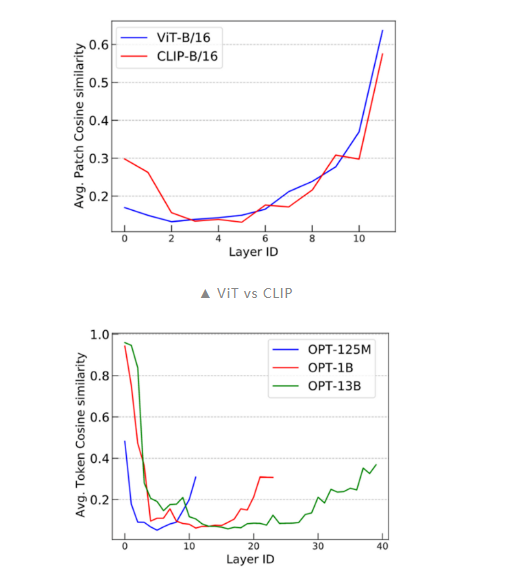
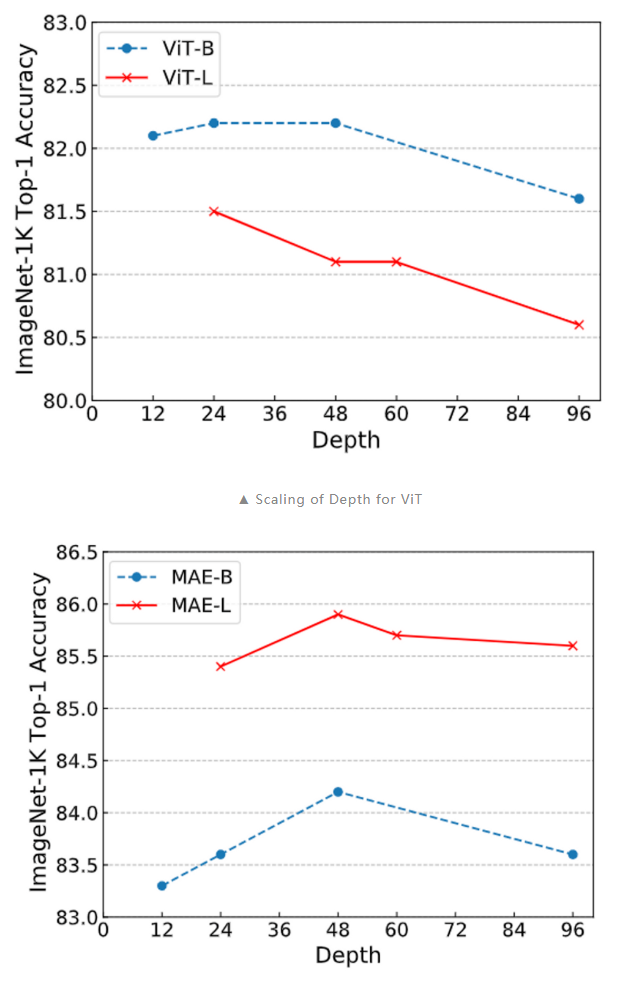
- 现有的 Transformer 模型在加深模型深度时会发生 over-smoothing 问题,这阻碍了模型在深度上的拓展。
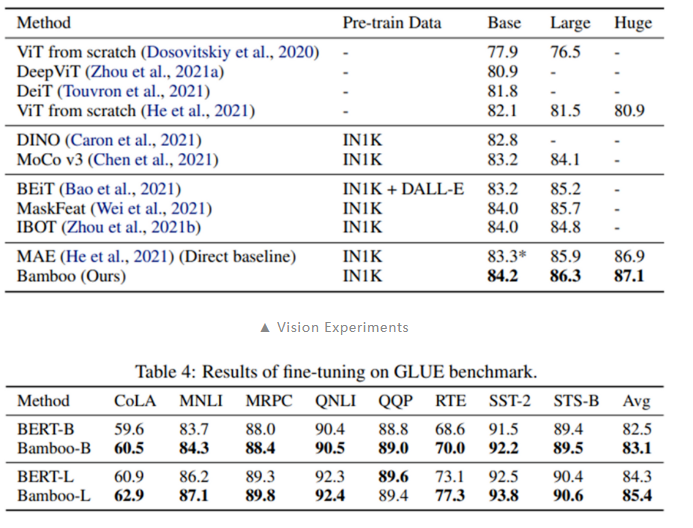
- 相较于简单分类训练目标,MAE 的掩码预测任务能够缓解 over-smoothing。(进一步地,token 级别的训练目标都能够一定程度地缓解 over-smoothing)
- MAE 的现有模型结构继承于机器翻译任务上的最佳结构设置,不一定合理。
———————End———————
点击阅读原文进入官网
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
RT-Thread
+关注
关注
32文章
1540浏览量
44274
原文标题:【AI简报20230908期】正式亮相!打开腾讯混元大模型,全部都是生产力
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
Arm率先适配腾讯混元开源模型,助力端侧AI创新开发
本周初,腾讯混元宣布开源四款小尺寸模型(参数分别为 0.5B、1.8B、4B、7B),可无缝运行于消费级显卡上。作为全球应用范围最为广泛的计算平台,Arm 在开源首日就已率先实现适配,
硬件与应用同频共振,英特尔Day 0适配腾讯开源混元大模型
于OpenVINO™ 构建的 AI 软件平台的可扩展性,英特尔助力ISV生态伙伴率先实现应用端Day 0 模型适配,大幅加速了新模型的落地进程,彰显了 “硬件 + 模型 + 生态” 协

摩尔线程率先支持腾讯混元-A13B模型
近日,腾讯正式开源基于专家混合(MoE)架构的大语言模型混元-A13B。同日,摩尔线程团队凭借技术前瞻性,率先完成该模型在全功能GPU的深度
AI与云端生产力结合应用场景及技术解析(2025)
AI与云端生产力结合应用场景及技术解析(2025) 一、核心技术架构 云原生与智能算力网络 采用容器化、微服务等云原生技术实现应用敏捷开发与弹性扩展,支撑工业大模型训练、城市级数据

腾讯元宝升级:深度思考模型“腾讯混元T1”全量上线
近日,腾讯元宝迎来了又一次重要更新,深度思考模型“腾讯混元T1”已全面上线。此次更新不仅进一步丰富了腾讯
DLP6500FLQ WIN11不显示投影内容,Firmware里面内容全部都是×,为什么?
换了主机后,WIN11系统连接可以连接HDMI线,会被认定为外接显示器。
但是另外一个USB口识别不出,打开GUI软件后,在视频模式和图案模式都不能打开,Firmware里面内容全部都是
发表于 02-20 08:15
腾讯AI助手“腾讯元宝”重大更新:支持深度思考功能
近日,腾讯AI助手“腾讯元宝”再次迎来了重大更新,为用户带来了更加智能、高效的使用体验。此次更新中,腾讯元宝新增了深度思考功能,这一功能由混
腾讯元宝AI产品更新,正式接入DeepSeek R1模型
近日,腾讯元宝AI产品在应用商店迎来了重要更新,正式接入了DeepSeek R1模型,并宣布该模型已联网且以满血状态上线。这一更新标志着腾讯
腾讯混元3D AI创作引擎正式发布
近日,腾讯公司宣布其自主研发的混元3D AI创作引擎已正式上线。这一创新性的创作工具将为用户带来前所未有的3D内容创作体验,标志着腾讯在
腾讯混元3D AI创作引擎正式上线
近日,腾讯公司宣布其自主研发的混元3D AI创作引擎已正式上线。这一创新性的创作工具,标志着腾讯在3D内容生成领域迈出了重要一步。
胡瀚接棒腾讯多模态大模型研发
腾讯的杰出科学家和混元大模型技术团队的核心成员,曾在推动腾讯在人工智能领域的发展中发挥了重要作用。然而,去年11月,有消息称刘威已从
腾讯混元大模型开源成绩斐然,GitHub Star数近1.4万
近日,在2024年12月24日举办的开放原子开发者大会暨首届开源技术学术大会上,腾讯云副总裁、腾讯混元大模型负责人刘煜宏发表了重要演讲。他强
腾讯混元文生图登顶智源FlagEval评测榜首
近日,北京智源人工智能研究院(BAAI)发布了最新的FlagEval大模型评测排行榜,其中多模态模型评测榜单的文生图模型引起了广泛关注。结果显示,腾讯





 工商网监
工商网监
评论