 基于DL Streamer与YOLOv8模型实现多路视频流实时分析
基于DL Streamer与YOLOv8模型实现多路视频流实时分析

作为众多 AI 应用场景的基座,基于流媒体的视觉分析一直是传统 AI 公司的核心能力之一。但想要搭建一套完整的视频分析系统其实并不容易,其中会涉及多个图像处理环节的开发工作,例如视频流拉取、图像编解码、AI 模型前后处理、AI 模型推理,以及视频流推送等常见任务模块。其中每一个模块都需要领域专家在指定的硬件平台进行开发和优化,并且如何高效地将他们组合起来也是一个问题。在这篇文章中,我们将探讨如何利用 Intel 的 DL Streamer 工具套件打造一套支持多路视频流接入的视频分析系统,利用 OpenVINO 部署并加速 YOLOv8 推理任务。
(复制链接到浏览器打开)
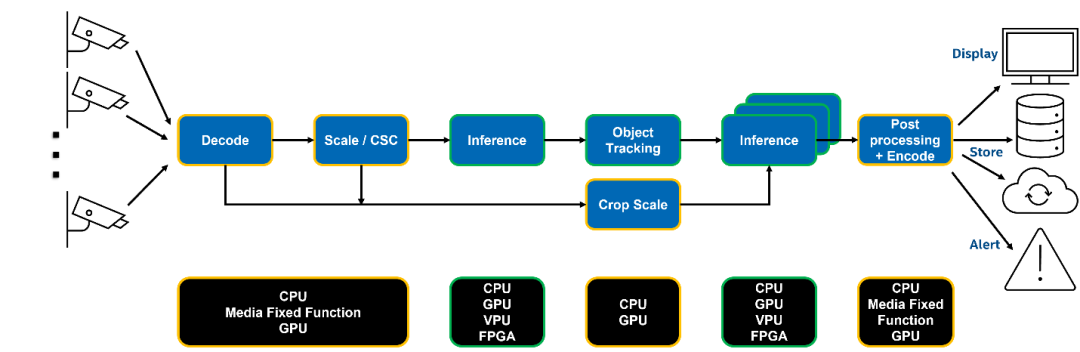
图1:典型的视频分析系统流水线
Intel DL Streamer 工具套件
DL Streamer 是一套开源的流媒体分析系统框架,它基于著名的 GStreamer 多媒体框架所打造,可以帮助开发者快速构建复杂的媒体分析流水线。开发者只需要通过命令行的方式就可以轻松完成一套支持多路的分析系统搭建。此外,在这个过程中,DL Streamer 会帮助我们将每个模块部署在指定的硬件加速平台,以获得更好的性能与更高的资源利用率。
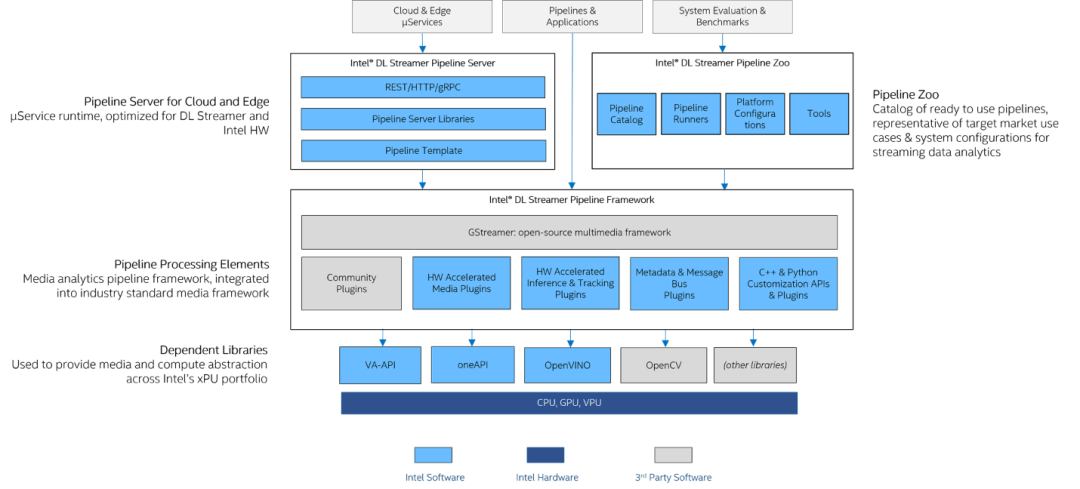
图2:DL Streamer 架构图
01Intel DL Streamer Pipeline Framework 用于构建最基础的视频分析流水线,其中利用 VA-API 库提升 GPU 的硬件编解码能力,基于 OpenVINO 实现对于 AI 推理任务的加速。此外还支持 C++和 Python API 接口调用方式,便于开发者与自有系统进行集成。
02Intel DL Streamer Pipeline Server 可以将构建好的视频分析流水线以微服务的方式部署在多个计算节点上,并提供对外的 REST APIs 接口调用。
03Intel DL Streamer Pipeline Zoo 则被作为性能评估与调式的工具,其中集成了一些即开即用的示例,方便开发者测试。
本文中分享的 demo 是一个基于 DL Streamer 的最小化示例,仅使用Intel DL Streamer Pipeline Framework 进行任务开发。
开发流程
1、YOLOv8 模型优化与转换
首先我们需要对模型进行性能优化,这里我们才利用量化技术来压缩模型体积。由于目前 Ultralytics 库已经直接支持 OpenVINO IR 格式的模型导出,所以我们可以直接调用以下接口将 YOLOv8 预训练权转化为OpenVINO IR,并通过 NNCF 工具进行后训练量化。
det_model = YOLO(f"../model/{DET_MODEL_NAME}.pt")
out_dir = det_model.export(format="openvino", dynamic=True, half=True)
左滑查看更多
此外由于我们需要使用 vaapi-surface-sharing backend,来实现从解码-前处理-推理在 GPU 设备上的 zero-copy,标准 YOLOv8 模型的部分前处理任务没有办法支持 vaapi-surface-sharing
因此我们需要将部分前处理任务以模型算子的形式提前集成到模型结构中,这里可以利用 OpenVINO 的 Preprocessing API 来进行前处理任务中转置和归一化操作的集成。具体方法如下:
input_layer = model.input(0)
model.reshape({input_layer.any_name: PartialShape([1, 3, 640, 640])})
ppp = PrePostProcessor(model)
ppp.input().tensor().set_color_format(ColorFormat.BGR).set_layout(Layout("NCHW"))
ppp.input().preprocess().convert_color(ColorFormat.RGB).scale([255, 255, 255])
model = ppp.build()
左滑查看更多
2、 集成 YOLOv8 后处理任务
由于 DLStreamer 目前没有直接支持 YOLOv8 的后处理任务,所以我们需要在其源码中新增 YOLOv8 后处理任务的 C++ 实现。
并重新编译 DLStreamer 源码。相较之前 YOLO 系列的模型,YOLOv8 模型的原始输出会一些特殊,他的输出数据结构为(1, 84, 8400),其中8400代表识别对象的数量,84 代表 4 个坐标信息 +80 种类别,而通常情况下坐标信息和类别信息都是在最后一个维度里,所以为了在 C++ 应用中更方便的地模型输出进行遍历,我们首先需要做一个维度转置的操作,将其输出格式变为(1, 8400, 84),接下来就可以通过常规 YOLO 模型的后处理方式,来解析并过滤 YOLOv8 模型输出。
cv::Mat outputs(object_size, max_proposal_count, CV_32F, (float *)data); cv::transpose(outputs, outputs);
左滑查看更多
3、构建 DL Streamer Pipeline
其实 DL Streamer Pipeline 的构建非常简单,我们只需要记住每一个 element 模块的功能,并按从“输入 -> 解码 -> 推理 -> 编码/输出”的次序将他们组合起来就可以了,以下就是一个单通道的示例。
gst-launch-1.0 filesrc location=./TownCentreXVID.mp4 ! decodebin ! video/x-raw(memory:VASurface) ! gvadetect model=./models/yolov8n_int8_ppp.xml model_proc=./dlstreamer_gst/samples/gstreamer/model_proc/public/yolo-v8.json pre-process-backend=vaapi-surface-sharing device=GPU ! queue ! meta_overlay device=GPU preprocess-queue-size=25 process-queue-size=25 postprocess-queue-size=25 ! videoconvert ! fpsdisplaysink video-sink=ximagesink sync=false
左滑查看更多
除推理部分的任务外,DL Streamer 中大部分的模块都是复用 GStreamer 的element,这里需要特别注意的是,为了实现在 GPU 硬解码和推理任务之间的 zero-copy,解码的输出需要为video/x-raw(memory:VASurface)格式,并且推理的任务的前处理任务需要调用 vaapi-surface-sharing backend ,以此来将前处理的任务负载通过 GPU 来进行加速。
此外这边也会用到 DL Streamer 2.0 API 中新增的meta_overlay 模块将结果信息,以 bounding box 的形态添加在原始视频流中,并利用 fpsdisplaysink 模块统计实时 FPS 性能后,一并作为结果可视化进行输出展示。如果本机不支持可视化播放,我们也可以通过拼接以下指令:
vaapih264enc ! h264parse ! mpegtsmux ! rtpmp2tpay ! udpsink host=192.168.3.9 port=5004
将结果画面编码后,通过 udp 协议推流,并用例如 VLC 这样的工具,在另一台设备播放。
如果不需要可视化呈现,我们也可以通过 gvametapublish 模块将原始结果输出到一个 json 文件中,或通过 MQTT 协议推送这些原始的结果数据。gvametapublish模块的使用方法可以查询:
https://dlstreamer.github.io/elements/gvametapublish.html(复制链接到浏览器打开)
4、多通道 Pipeline 优化
为了方便多通道任务同屏展示,我们通过 compositor模块将多个通道的检测结果进行拼接。在多路推理性能优化方面,可以利用以下指令,将多个同一时刻内的多个 stream 输入,打包为一个 batch,送入 GPU 进行推理,以激活 GPU 在吞吐量上的优势,而 infer request 的数量则会根据接入视频的通道数动态调整。
nireq=$((${STREAM}*2)) gpu-throughput-streams=${STREAM} batch-size=${NUM_PANES} model-instance-id=1
左滑查看更多
此外,为了避免重复创建模型对象,可以将每个通道里的model-instance-id都设为统一值,这样 OpenVINO 只会为我们初始化一个模型对象。
如何运行示例
为了方便在不同硬件平台进行移植,同时降低部署门槛,这里我们已经将所有的示例代码打包进了 docker 镜像内,大家可以通过以下几条简单的指令,快速复现整个方法。
1、初始化环境
这一步主要为了可以在容器内访问 host 的 GPU 资源,以及开启视频流展示的权限,如果当前硬件中存在多个 GPU 设备,我们可以通过修改 GPU driver 的编号来调整映射到容器内的 GPU 资源,例如这可以把renderD128修改为 renderD129
$ xhost local:root $ setfacl -m user:1000:r ~/.Xauthority $ DEVICE=${DEVICE:-/dev/dri/renderD128} $ DEVICE_GRP=$(ls -g $DEVICE | awk '{print $3}' | xargs getent group | awk -F: '{print $3}')
左滑查看更多
2、拉取 docker 镜像
$ docker pull snake7gun/dlstreamer-yolov8-2023.0:latest
左滑查看更多
3、运行容器
将之前设置 host 环境映射到容器内,并初始化容器内环境。
$ docker run -it --rm --net=host -e no_proxy=$no_proxy -e https_proxy=$https_proxy -e socks_proxy=$socks_proxy -e http_proxy=$http_proxy -v ~/.Xauthority:/home/dlstreamer/.Xauthority -v /tmp/.X11-unix -e DISPLAY=$DISPLAY --device $DEVICE --group-add $DEVICE_GRP snake7gun/dlstreamer-yolov8-2023.0 /bin/bash $ source /home/dlstreamer/dlstreamer_gst/scripts/setup_env.sh
左滑查看更多
4、执行多路示例
运行示例,这里可以将 shell 脚本后的视频文件替换为 IP 摄像头 RTSP 地址,或是 webcam 的编号。由于gvawatermark模块在 iGPU 上的性能表现要优于meta_overlay ,而在 dGPU 上则相反,因此这里准备了两套 pipeline,分别为pipeline-igpu.sh 以及pipeline-dgpu.sh ,大家可以根据自己的硬件环境进行切换。
$ cd dlstreamer_gst/demo/ $ ./pipeline-igpu.sh ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4
左滑查看更多
效果展示
本方案已经在2023 年度的 Intel Innovation 大会上进行了展示,该 demo 基于英特尔第 12 代酷睿 处理器的 iGPU 平台,在 9 路 1080p h.265 摄像头输入的情况下,保证每路的实时分析性能可以达到 15fps,也就是大部分摄像头的帧率上限。
审核编辑:汤梓红
-
英特尔
+关注
关注
61文章
10321浏览量
181079 -
视频
+关注
关注
6文章
2013浏览量
75191 -
AI
+关注
关注
91文章
41101浏览量
302580 -
模型
+关注
关注
1文章
3818浏览量
52265 -
OpenVINO
+关注
关注
0文章
118浏览量
818
原文标题:基于 DL Streamer 与 YOLOv8 模型实现多路视频流实时分析 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于YOLOv8实现自定义姿态评估模型训练

单板挑战4路YOLOv8!米尔瑞芯微RK3576开发板性能实测
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型

YOLOv8版本升级支持小目标检测与高分辨率图像输入
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型

教你如何用两行代码搞定YOLOv8各种模型推理

三种主流模型部署框架YOLOv8推理演示
YOLOv8实现任意目录下命令行训练
基于YOLOv8的自定义医学图像分割

基于OpenCV DNN实现YOLOv8的模型部署与推理演示
使用NVIDIA JetPack 6.0和YOLOv8构建智能交通应用
使用ROCm™优化并部署YOLOv8模型



评论