 基于YOLOv8实现自定义姿态评估模型训练
基于YOLOv8实现自定义姿态评估模型训练

前言
Hello大家好,今天给大家分享一下如何基于YOLOv8姿态评估模型,实现在自定义数据集上,完成自定义姿态评估模型的训练与推理。
01tiger-pose数据集
YOLOv8官方提供了一个自定义tiger-pose数据集(老虎姿态评估),总计数据有263张图像、其中210张作为训练集、53张作为验证集。
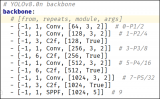
其中YOLOv8-pose的数据格式如下:
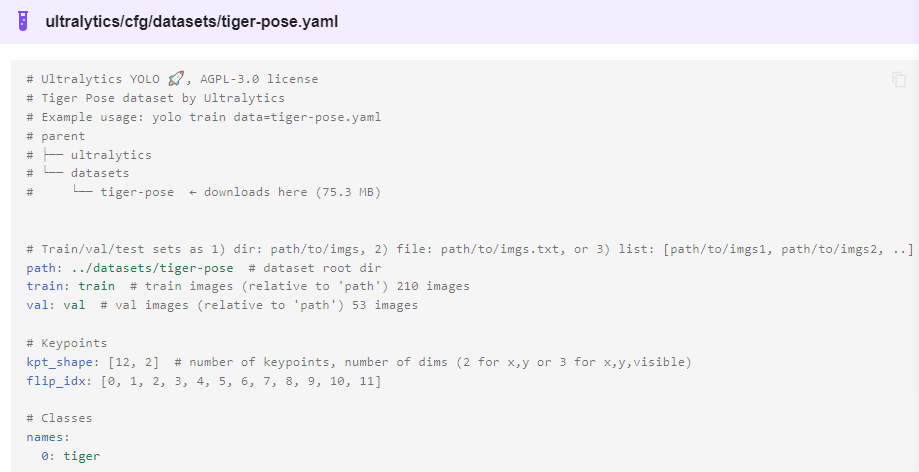
解释一下:
Class-index 表示对象类型索引,从0开始 后面的四个分别是对象的中心位置与宽高 xc、yc、width、height px1,py1表示第一个关键点坐标、p1v表示师傅可见,默认填2即可。 kpt_shape=12x2表示有12个关键点,每个关键点是x,y
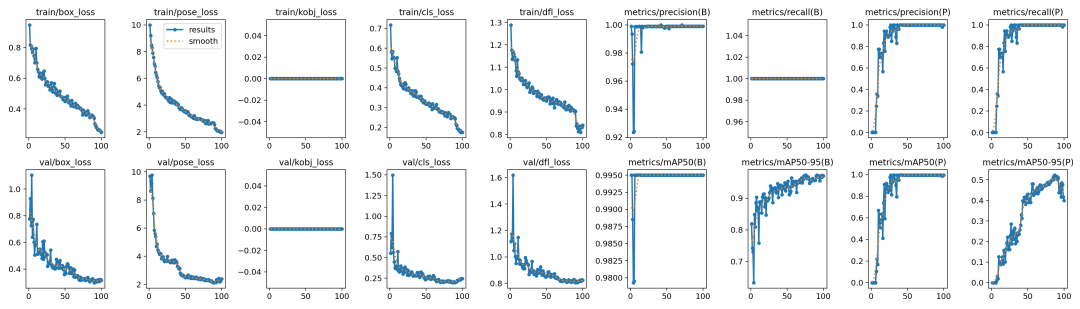
02模型训练
跟训练YOLOv8对象检测模型类似,直接运行下面的命令行即可:
yolotrainmodel=yolov8n-pose.ptdata=tiger_pose_dataset.yamlepochs=100imgsz=640batch=1
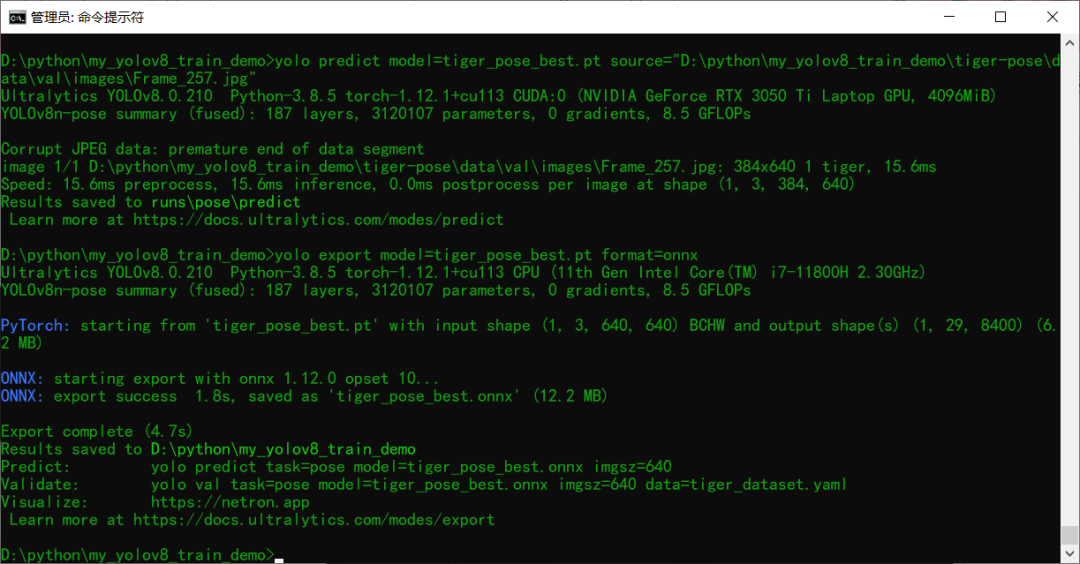
03模型导出预测
训练完成以后模型预测推理测试 使用下面的命令行:
yolo predict model=tiger_pose_best.pt source=D:/123.jpg
导出模型为ONNX格式,使用下面命令行即可
yolo export model=tiger_pose_best.pt format=onnx
04部署推理
基于ONNX格式模型,采用ONNXRUNTIME推理结果如下:
ORT相关的推理演示代码如下:
def ort_pose_demo():
# initialize the onnxruntime session by loading model in CUDA support
model_dir = "tiger_pose_best.onnx"
session = onnxruntime.InferenceSession(model_dir, providers=['CUDAExecutionProvider'])
# 就改这里, 把RTSP的地址配到这边就好啦,然后直接运行,其它任何地方都不准改!
# 切记把 yolov8-pose.onnx文件放到跟这个python文件同一个文件夹中!
frame = cv.imread("D:/123.jpg")
bgr = format_yolov8(frame)
fh, fw, fc = frame.shape
start = time.time()
image = cv.dnn.blobFromImage(bgr, 1 / 255.0, (640, 640), swapRB=True, crop=False)
# onnxruntime inference
ort_inputs = {session.get_inputs()[0].name: image}
res = session.run(None, ort_inputs)[0]
# matrix transpose from 1x8x8400 => 8400x8
out_prob = np.squeeze(res, 0).T
result_kypts, confidences, boxes = wrap_detection(bgr, out_prob)
for (kpts, confidence, box) in zip(result_kypts, confidences, boxes):
cv.rectangle(frame, box, (0, 0, 255), 2)
cv.rectangle(frame, (box[0], box[1] - 20), (box[0] + box[2], box[1]), (0, 255, 255), -1)
cv.putText(frame, ("%.2f" % confidence), (box[0], box[1] - 10), cv.FONT_HERSHEY_SIMPLEX, .5, (0, 0, 0))
cv.circle(frame, (int(kpts[0]), int(kpts[1])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[2]), int(kpts[3])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[4]), int(kpts[5])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[6]), int(kpts[7])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[8]), int(kpts[9])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[10]), int(kpts[11])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[12]), int(kpts[13])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[14]), int(kpts[15])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[16]), int(kpts[17])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[18]), int(kpts[19])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[20]), int(kpts[21])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[22]), int(kpts[23])), 3, (255, 0, 255), 4, 8, 0)
cv.imshow("Tiger Pose Demo - gloomyfish", frame)
cv.waitKey(0)
cv.destroyAllWindows()
审核编辑:汤梓红
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
模型
+关注
关注
1文章
3811浏览量
52257 -
数据集
+关注
关注
4文章
1240浏览量
26261 -
命令行
+关注
关注
0文章
83浏览量
10778
原文标题:【YOLOv8】自定义姿态评估模型训练
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
请问如何在imx8mplus上部署和运行YOLOv5训练的模型?
我正在从事 imx8mplus yocto 项目。我已经在自定义数据集上的 YOLOv5 上训练了对象检测模型。它在 ubuntu 电脑上运
发表于 03-25 07:23
TensorRT 8.6 C++开发环境配置与YOLOv8实例分割推理演示
对YOLOv8实例分割TensorRT 推理代码已经完成C++类封装,三行代码即可实现YOLOv8对象检测与实例分割模型推理,不需要改任何代码即可支持
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型
《在 AI 爱克斯开发板上用 OpenVINO 加速 YOLOv8 分类模型》介绍了在 AI 爱克斯开发板上使用 OpenVINO 开发套件部署并测评 YOLOv8 的分类模型,本文将

YOLOv8版本升级支持小目标检测与高分辨率图像输入
YOLOv8版本最近版本又更新了,除了支持姿态评估以外,通过模型结构的修改还支持了小目标检测与高分辨率图像检测。原始的YOLOv8
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型
《在AI爱克斯开发板上用OpenVINO加速YOLOv8分类模型》介绍了在AI爱克斯开发板上使用OpenVINO 开发套件部署并测评YOLOv8的分类模型,本文将介绍在AI爱克斯开发板

教你如何用两行代码搞定YOLOv8各种模型推理
大家好,YOLOv8 框架本身提供的API函数是可以两行代码实现 YOLOv8 模型推理,这次我把这段代码封装成了一个类,只有40行代码左右,可以同时支持

三种主流模型部署框架YOLOv8推理演示
深度学习模型部署有OpenVINO、ONNXRUNTIME、TensorRT三个主流框架,均支持Python与C++的SDK使用。对YOLOv5~YOLOv8的系列模型,均可以通过C+
基于YOLOv8的自定义医学图像分割
YOLOv8是一种令人惊叹的分割模型;它易于训练、测试和部署。在本教程中,我们将学习如何在自定义数据集上使用YOLOv8。但在此之前,我想告

如何基于深度学习模型训练实现圆检测与圆心位置预测
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现圆检测与圆心位置预测,主要是通过对YOLOv8姿态

如何基于深度学习模型训练实现工件切割点位置预测
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现工件切割点位置预测,主要是通过对YOLOv8姿态

RV1126 yolov8训练部署教程
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的基于YOLOV5进行更新的 下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,鉴于Yolov5的良好表现,
使用ROCm™优化并部署YOLOv8模型
://github.com/ultralytics/ultralytics/tree/main YOLOv8模型的卓越性能使其在多个领域具有广泛的应用前景,如自动驾



评论