 TextBind:在开放世界中多轮交织的多模态指令跟随
TextBind:在开放世界中多轮交织的多模态指令跟随

摘要
拥有指令跟随能力的大型语言模型已经彻底改变了人工智能领域。这些模型通过其自然语言界面展现出卓越的通用性,能够应对各种现实世界任务。
然而,它们的性能在很大程度上依赖于高质量的示例数据,通常难以获得。当涉及到多模态指令跟随时,这一挑战进一步加剧。
我们介绍了TextBind,这是一个几乎无需注释的框架,用于赋予更大型的语言模型多轮交织的多模态指令跟随能力。
我们的方法仅需要图像描述对,并从语言模型生成多轮多模态指令-响应对话。我们发布了我们的数据集、模型和演示,以促进未来在多模态指令跟随领域的研究。
数据
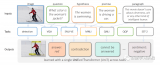
TextBind提供了处理和生成任意交织的图像和文本内容的示例,使语言模型能够在开放世界场景中与用户进行自然互动。

模型
我们的模型包括一个图像编码器、一个图像解码器、一个语言模型,以及连接它们的桥接网络,支持多轮交织的多模态指令跟随。它可以生成并处理任意交织的图像和文本内容。
demo
语言模型能够执行各种任务,包括根据一组图像创作引人入胜的故事,比较多个图像中的共同和不同之处,用生动的图像解释概念,生成带有插图的长篇连贯故事等等。最有趣的是,我们模型的核心创新在于其能够在广泛的真实场景中与用户自然互动。欢迎访问我们的demo[1]。
例子
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
编码器
+关注
关注
45文章
4011浏览量
143349 -
图像
+关注
关注
2文章
1096浏览量
42438 -
语言模型
+关注
关注
0文章
575浏览量
11343
原文标题:TextBind:在开放世界中多轮交织的多模态指令跟随
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
话:基于历史回答图中女孩头发和衣服分别是什么颜色
上一次我们详细讲解在RK3576上部署多模态模型的案例,这次将继续讲解多轮对话的部署流程。整体流程基于 rknn-llm 里的
发表于 09-05 17:25

多文化场景下的多模态情感识别
自动情感识别是一个非常具有挑战性的课题,并且有着广泛的应用价值.本文探讨了在多文化场景下的多模态情感识别问题.我们从语音声学和面部表情等模态
发表于 12-18 14:47
•0次下载
多模态上下文指令调优数据集MIMIC-IT
然而,一个理想的 AI 对话助手应该能够解决涉及多种模态的任务。这需要获得一个多样化和高质量的多模式指令跟随数据集。比如,LLaVAInstruct-150K 数据集(也被称为 LLa

VisCPM:迈向多语言多模态大模型时代
可以大致分为两类: 1. 在图生文(image-to-text generation)方面,以 GPT-4 为代表的多模态大模型,可以面向图像进行开放域对话和深度推理; 2.

更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」
当前学界和工业界都对多模态大模型研究热情高涨。去年,谷歌的 Deepmind 发布了多模态视觉语言模型 Flamingo ,它使用单一视觉语言模型处理多项任务,

基于Transformer多模态先导性工作
多模态(Multimodality)是指在信息处理、传递和表达中涉及多种不同的感知模态或信息来源。这些感知模态可以包括语言、视觉、听觉、触觉

智谱 GLM-PC 开放体验,多模态 Agent 升级
1月23日,北京智谱华章科技有限公司宣布旗下智谱GLM-PC开放体验,标志着自主操作电脑的多模态Agent迎来重要升级。 GLM-PC是基于智谱多模



评论