 GPT-4没有推理能力吗?
GPT-4没有推理能力吗?

今年三月,OpenAI 重磅发布了 GPT-4 大模型,带来了比 ChatGPT 背后 GPT-3.5 更强的推理、计算、逻辑能力,也引发了全民使用的热潮。在各行各领域研究人员、开发者、设计师的使用过程中,「GPT-4 是最为领先的大模型」似乎已成为了公认的结果。
然而,8 月 7 日,毕业于美国麻省理工学院、现任 Dyania Health CTO的Konstantine Arkoudas 最新撰写了一篇标题为《GPT-4 Can't Reason》(GPT-4 不能推理)的预印本(指尚未在需要同行评审的科学期刊上出版的科学文献的草稿)论文,在业界引起轩然大波。
该论文指出,GPT-4 与 GPT 3.5 相比有了全面的实质性改进。然而,尽管确实取得了令人印象深刻的改进,但其有充分的理由对 GPT-4 的推理能力表示高度怀疑。这篇论文讨论了推理的本质,批评当前 NLP 界对推理问题的表述以及目前评估 LLM 推理表现的方式,同时分享了基于 GPT-4 给出的 21 个不同推理问题的集合。
最终得出结论:尽管GPT-4偶尔会闪现出分析的才华,但它目前是完全无法推理的。
一语掀起千层浪,难道此前 GPT-4 在短短几分钟之内生成一款游戏代码,难道都不算是推理吗?
什么是推理?
其实在今年一月初,论文作者 Konstantine Arkoudas 就在 Medium 平台上分享了一篇有关 ChatGPT 的非正式评估,评估涉及的学科非常广泛,包括传统 NLU、民间物理、信息检索、心理理论、空间推理、简单逻辑推理和数学。
当时其得到的主要结论是:ChatGPT 是一项开创性的突破;基于 LLM 的系统并不只是“随机鹦鹉”,而是建立了真正的抽象,并能展现创造力;这类系统将带来大量令人兴奋的新应用;尽管取得了上述的成就,但这些系统在推理能力上仍然受到严重限制。
在他看来,如今升级版的 GPT-4 依然如此,甚至完全没有推理能力。
在论文中,Konstantine Arkoudas 指出,业界关于“LLM 是否有推理能力”的争论已经持续了很长时间。
一方面,是 LLM 支持派。他们对大模型美好推理能力预测往往会依赖不断变化的“定律”,而这些所谓的“定律”,Konstantine Arkoudas 认为,实际上就是站不住脚的经验证据、大量有问题的建模假设、理解不清的概念(LLM 特性),以及甚至包含一点教条信念,即在庞大的语料库中最大限度地减少下一个标记预测的交叉熵损失,就能通过迁移学习的魔力和通用高级表征的构建,提供一个通用的推理引擎。
另一方面,则是 LLM 怀疑派。他们往往有着严谨的论据,但是这些论点大多是基于过往经验和分析,有些含糊不清(例如,LLM 缺乏“世界模型”,即关于世界如何运作的内部模型)。
基于这两方面考虑,Konstantine Arkoudas 认为,对于可靠的鲁棒 LLM 推理的合理性,最令人信服的先验(过往经验和分析)考虑是计算复杂性的结果。推理是一个非常难以计算的问题。事实上,在一般情况下(一阶或高阶逻辑),它在算法上是不可判定的。
Konstantine Arkoudas 表示,「任何 LLM,无论规模有多大,经过多么广泛和巧都无法破解任意推理问题。这与机器学习中著名的 "没有免费的午餐"定理是一致的,后者指出了模型通用性与性能之间类似的反比关系」。
因此,为了验证“GPT-4 是否具有推理能力”,首先要做的是统一理念,即什么是推理,以及判定推理能力所采用的具体方法。
对于推理的定义,Konstantine Arkoudas 表示,「推理不是不择手段地得出正确的答案,而是根据正确的理由得出正确的答案。」
更准确地说,推理是提出论点,更重要的是证明论点的过程。一个论证包括一个结论(可以说是论证的结果)和一系列前提,结论就是由这些前提推导出来的。前提代表了为论证目的而被视为既定的信息,即使只是暂时的。结论和前提通常是陈述句,用自然语言或符号逻辑的符号来表达,可真可假,但也可以用图表等其他符号来表示。如果 S 中的所有句子都为真,则 p 为真,在这种情况下,这个论点被认为是有效的。
对于方法论,Konstantine Arkoudas 在论文中所采用的评估不是基于一个语料库或一组语料库。相反,其对 GPT-4 在广泛领域的 21 个简单推理问题上的性能进行了详细的定性分析,其中大部分是从头开始编写的,而其余的(例如 Wason 的选择任务)则经过手动调整,使模型不易识别它们,这样做的部分原因也是为了避免数据污染。
用测试问题验证 GPT-4 的推理性
基于此,Konstantine Arkoudas 从多个维度对 GPT-4 提出问题,并根据其输出进行了详尽的分析。
值得一提的是,由于 GPT-4 的属性,有时候即使用相同的“Prompt”,在不同的运行中也可能会得到不同的答案。
接下来,验证开始(以下所有测试时间多出自2023 年 7 月 5 日测试结果)。
简单算术
Konstantine Arkoudas 表示,执行基本算术运算的能力是通用推理的必要组成部分,尤其是在科学和工程应用领域。为了确保 GPT-4 不会死记硬背,他提出了让 GPT-4 在其选择的范围内随机选择两个随机整数,然后对选择的值执行操作。
KA 给出的 Prompt 是:
在 1381 和 1453 之间选择两个随机数,然后将它们相乘,并报告结果。
GPT-4 的回答是:
当然,让我们在 1381 到 1453 的范围内选取两个随机数。假设这个数字是 1405 和 1421。
要得到乘积,我们只需将这两个数字相乘:1405*1421 = 1996025
但实际上,正确答案是 1405*1421=1996505。
事实证明,GPT-4 仍然无法可靠地执行基本算术运算,如加法和乘法。
Konstantine Arkoudas 表示,也许LLM 的支持者此时可能会承认 GPT-4 不是一个图灵完备的框架,不能执行通用计算:它不能进行加、乘法或除法运算,不能对列表进行排序、不能求逆矩阵或解微分方程组、不能将任意程序编译成机器码、不能推导定理等等。
不过,这些计算能力的缺失可以通过第三方插件来弥补,如 ReAct、MRKL 框架。正是这种工作方式催生了 LangChain 和 AutoGPT 这样的系统。这里的想法是使用 LLM 作为规划器,将复杂问题递归分解为一系列子问题,通过适当的 API 将这些子问题分派给专门的代理。
然而,Konstantine Arkoudas 认为,这种方法的问题在于它的循环性。规划本身就需要推理,所以这是一个 "两难选择",即我们无法通过将问题委托给合适的代理来解决推理问题,因为找出委托的方法(如何分解问题、调用哪些代理、如何调用以及如何分解结果)本身在计算上就不可行。这不仅需要理解自然语言的能力,还需要推理先决条件和效果的能力。即使在这些过于简单化的假设下,规划的计算成本也非常高昂(PSPACE-complele),需要进行彻底的简化才能将复杂度降低到 NP-complele 的水平。在更现实的假设条件下,规划是在不完全的知识条件下进行的,在机制上是不可判定的。正如我们今天所理解的那样,期望通用 LLMs 能够成功解决规划问题是天真的想法。
简单计数
给 GPT-4 一个命题变量,在它前面有 27 个否定符号,并要求它计算否定的数量。对于人类来说,这是个很容易的任务,尤其是因为否定符号是分五块写的,每块有五个小点,最后是一对否定符号,但是 GPT-4 的表现如何呢?
KA:
在下面的公式中,p 被否定了多少次:
~~~~~ ~~~~~ ~~~~~ ~~~~~ ~~~~~ ~~ p
GPT-4 的回答是:
GPT-4:你给出的公式在命题变量 "p "前面包含了 28 个否定符号("∼")。在逻辑学中,否定符号将语句的真值改变为它的相反值。如果一个语句为真,那么它的否定就是假的,反之亦然。双重否定,如"∼ ∼ p",等价于 "p",因为对一个命题否定两次,它就恢复到原来的真值。
如果有余数,那么就有一个否定。如果没有,那么就没有否定。
28 除以 2 是 14,没有余数,也就是说没有否定。因此,实际上在给定的公式中,变量 "p "并没有被否定。它只相当于 "p"。
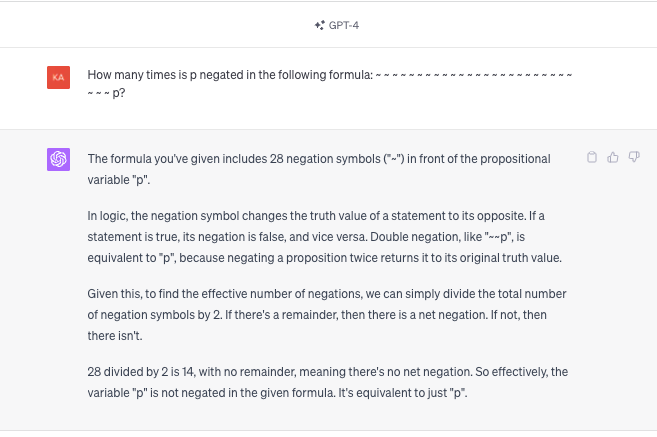
Konstantine Arkoudas 发现,GPT-4 多数了一个否定符号带来的差别似乎并不严重,直到我们意识到它在逻辑输入上的所有差别,正如 GPT-4 自己(不请自来)的解释所强调的那样。即使在明确告诉 GPT-4 要慢慢来、仔细数的情况下,多次重复这个实验也得到了大相径庭的结果。
常识性问题
紧接着 Konstantine Arkoudas 又提出:“Mable 上午 9 点的心率是 75bom,下午 7 点的血压是 120/80。她于晚上 11 点死亡。她中午还活着吗?”

GPT-4:
根据所提供的信息,我们无法确定 Mable 中午是否还活着。所提供的数据点(上午 9 点的心率和下午 7 点的血压)都表明她当时还活着。但是,如果没有更多关于她下午 7 点到 11 点之间或者具体到中午的情况信息,我们就无法确定她中午时的状况。
请记住,医疗信息可能是复杂而微妙的。要了解一个人的健康状况,通常需要进行全面的检查,并应由专业医护人员进行。如果这是一个假设性问题,请记住现实生活中需要更完整的信息。
在目前的情况下,其实可以将常识论证视为从给定信息加上未说明的前提得出的直接推导结论,这些前提构成了普遍接受的背景知识。在这种特殊情况下,这种常识性知识就是 "人在死前是活着的,死后就不会再活着 "这样的命题。在论文中,Konstantine Arkoudas 认为,GPT-4 给出"这是一个复杂的问题,请务必向专业人士咨询 "的说法似乎具有讽刺意味。
Wason 选择问题
Wason 选择任务是推理心理学的主要内容。
KA:
桌上放着七张扑克牌,每张扑克牌的一面都有一个数字,另一面有一个单色的图案。牌面分别显示 50、16、红、黄、23、绿、30。如果一张牌上显示的是 4 的倍数,那么反面的颜色就是黄色,你需要翻哪张牌来检验这个命题的真伪?
GPT-4:
命题是:"如果一张牌上的数字是 4 的倍数,那么另一面的颜色是黄色"。为了验证这个命题,你必须翻开下面的牌:
扑克牌"16":根据命题,另一面的颜色应该是黄色。通过翻开这张牌,你可以检查命题的这一部分是否成立。
扑克牌"黄色":翻开这张牌,你就可以检查对面的数字是否是 4 的倍数。
扑克牌"50"和"30":虽然这两张卡片上的数字不是 4 的倍数,但还是要检查一下,以确保另一面的颜色不是黄色。如果另一面是黄色,那么就推翻了“只有 4 的倍数的另一面是黄色”的命题。
你不需要翻开卡片"23"、"红色 "或 "绿色"。卡片"23"不是 4 的倍数,所以根据给定的命题,另一面是什么颜色并不重要。如果 "红色 "和 "绿色 "卡片的另一面的数字是 4 的倍数,它们也不会推翻命题,因为命题并没有说明黄色是唯一可以出现在数字是 4 的倍数的卡片的另一面的颜色。
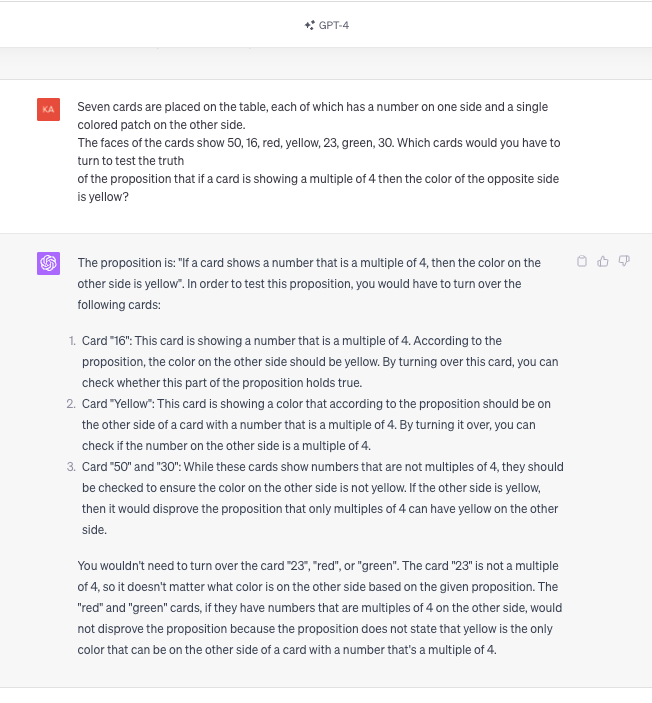
事实上,只有 16、红色和绿色需要翻转。因此,在精确度方面,这些回答再次表明,GPT-4 并不理解物质条件式的语义。
当 GPT-4 说扑克牌 "50 "和 "30 "必须翻过来时,它似乎把 if 错当成了 if and only if:「当这些卡片上显示的数字不是 4 的倍数,它们应检查以确保另一面的颜色不是黄色。如果另一面是黄色,那么就会推翻 "只有 4 的倍数的另一面是黄色 "这一命题」。当然,所检验的命题并不要求只有 4 的倍数的另一面是黄色;它只是要求,如果一张牌的另一面是 4 的倍数,那么另一面一定是黄色;或者换句话说,如果一张牌的正面不是黄色,那么另一面的数字就不是 4 的倍数。
但要注意的是,即使是将规则错误地解释为一个双重条件,也没有得到一致的遵守。如果 GPT-4 将被测试的规则理解为一个双重条件,因而不得不翻转 50 和 30,那么它就应该对 23 做同样的事情。但它没有这样做。
事实上,它明确地说,扑克牌 "23 "不是 4 的倍数,因此根据给定的命题,另一面是什么颜色并不重要,这与它用来作为翻转 50 和 30 的理由的二条件解释相矛盾。这再次说明了这些例子中出现的另一个重要主题:GPT-4 的回答,无论对错,往往都存在内在的不一致。
除此之外,Konstantine Arkoudas 还在论文中验证了空间推理、熵、简单编译器的正确性、时间推理等能力。
因篇幅问题,我们在本文中只选取以上几个示例加以说明。
结论
最终种种验证无疑证明了 GPT-4 推理能力的惨淡画面。
结果表明,该模型存在内部不一致性、不能正确应用基本推理技术和缺乏对推理中起基础性作用的概念(如物质条件)的理解等问题。
但是现实中,这些问题往往归纳为大模型带来的误差与“幻觉”,实则其实是它不具备推理能力。
鉴于 GPT-4 是目前最有能力的 LLM,Konstantine Arkoudas从这些发现中得出三个主要结论:
在软件开发(或一般的科学和工程)中使用生成式人工智能来完成乏味的任务(作为一种针对知识密集型编码问题的涡轮增压自动补全)之外的任何任务都充满了严重的风险。正确性的规范标准是至关重要的,在这些领域,目前的 LLM 不能满足这样的标准。就像生成人工智能已经开始用糟糕的广告污染网络一样,它有可能大规模地增加 Bug 代码。
如果 LLM 推理继续改进,严格的证明检查就可能变得越来越重要。对于应用程序来说,对系统推理的正确性有信心是必不可少的,尤其是在科学、医学和工程领域,而验证检查是一种能够提供这种信任的技术。这种方法可以通过要求 LLMS 将其推理正规化(用易于验证检查的符号表示法来表示),或者可能通过培训其他 LLMS 检查用自然语言表示的一段推理来实现。
就目前情况来看,反乌托邦的场景涉及一个让人类屈服的流氓人工智能,甚至其他人类使用人工智能来达到邪恶的目的,是非常牵强的。当最先进的人工智能系统在空间推理过程中甚至无法区分左右时,行业中还有那么多呼吁制定政策和机构来保护人类免受其 AI 侵害的做法显然是不成熟的。
争议
在 Konstantine Arkoudas 看来,当前的生成式 AI 还处于发展的早期,距离推理能力以及 AGI 时代还有很远的距离。
此篇论文一经发布,也在 HN 上吸引了很多人的关注与讨论,难道过去 5 个月间,我们都被骗了吗?

不过,他的这一独特的看法,也得到了不少 AI 学者的认同。
人工智能领域内的“叛逆者”、纽约大学心理学和神经科学荣誉教授Gary Marcus 发推文表示:“如果这是真的——正如我早就说过的——我们距离通用人工智能还差得很远。可能需要进行大量的重新校准:没有推理就不可能拥有通用人工智能。”
@SiSafLtd首席人工智能官 Nikos Tzagarakis 表示,“深度学习算法是为了根据感知进行预测而构建的。他们可能会伪造推理,但实际上这是感知。”
不过,也有网友提出质疑:
我浏览了这些资料,并尝试重现了一些报告的故障,从中得出了两个结论。
1. 作者不善于 Prompt。有很多方法可以减少幻觉,为模型提供更好的思考路径。
2. 作者使用的是 ChatGPT 的 GPT-4,导致他将 "GPT-4 "与 "ChatGPT "混为一谈。虽然你可以认为这是 OpenAI 的共同失误,但由于 OpenAI 的沟通不畅,任何认真评估这些模型的人都会知道,你需要做的第一件事就是使用 API 并锁定模型版本。就作者而言,他应该使用 gpt-4-0314 或 gpt-4-0613。我怀疑他只是使用了 ChatGPT 的 GPT-4,而且很可能是默认模型。(任何人都不应该使用默认模式。这是性能优化最差的模型,在推理任务上的表现比 Plugins 模型更差,甚至在上下文大小的任务上也是如此)。
如果作者一直在认真地评估模型,那么说明模型是他要做的第一件事。也许他应该解释一下他的理由。
至此,你怎么看?
审核编辑:刘清
-
机器学习
+关注
关注
67文章
8570浏览量
137421 -
GPT
+关注
关注
0文章
376浏览量
17016 -
OpenAI
+关注
关注
9文章
1262浏览量
10327 -
ChatGPT
+关注
关注
31文章
1608浏览量
10433 -
LLM
+关注
关注
1文章
351浏览量
1412
原文标题:GPT-4 其实没有推理能力?!
文章出处:【微信号:AI科技大本营,微信公众号:AI科技大本营】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
EB GPT PIT1跑飞的原因?如何解决?
请教RTD GPT 配置问题
商汤开源SenseNova-MARS:突破多模态搜索推理天花板
LLM推理模型是如何推理的?

基于NVIDIA Alpamayo构建具备推理能力的辅助驾驶汽车
GPT-5.1发布 OpenAI开始拼情商
NVIDIA TensorRT LLM 1.0推理框架正式上线
什么是AI模型的推理能力
【RA4M2-SENSOR】3、使用GPT定时器-PWM输出
NVIDIA从云到边缘加速OpenAI gpt-oss模型部署,实现150万TPS推理

微软企业级应用AI能力全面升级
OpenAI或在周五凌晨发布GPT-5 OpenAI以低价向美国政府提供ChatGPT
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代



评论