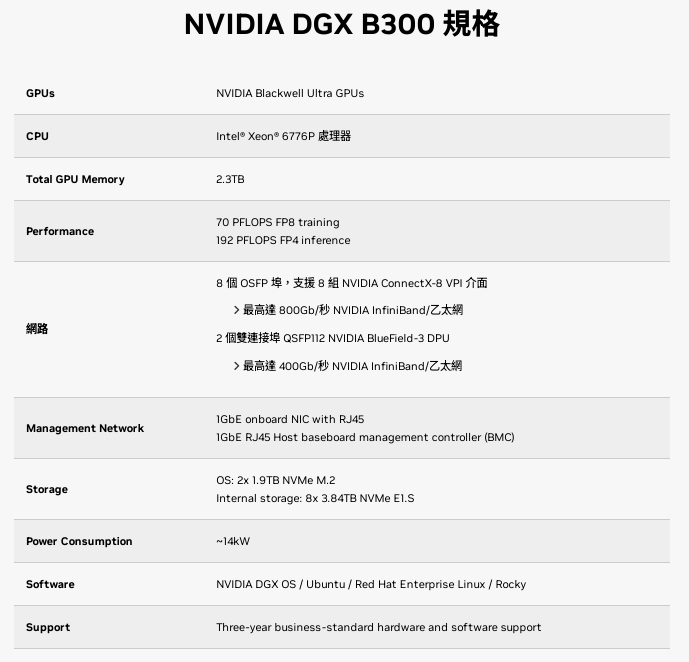
 英伟达A100和3090的区别
英伟达A100和3090的区别

英伟达A100和3090的区别
英伟达A100是一款面向数据中心的计算加速器,其主要优势是支持数据中心最新的AI、机器学习和高性能计算工作负载。它配备了专门的张量核心和加速器,可以比普通GPU更快地实现深度学习训练和推理操作,具有更高的计算精度和更大的内存容量。
英伟达A100是一款基于英伟达Ampere架构的高性能计算卡,主要面向数据中心和高性能计算领域。其拥有高达6912个CUDA核心和432个Turing Tensor核心,可以实现高达19.5 TFLOPS的FP32浮点性能和156 TFLOPS的深度学习性能。此外,它还支持NVIDIA GPU Boost技术和32GB HBM2显存,能够提供卓越的计算性能和内存宽带。英伟达A100还配备了英伟达的第三代NVLink互连技术和第二代NVSwitch交换机,可以实现高带宽、低延迟的GPU-GPU通信,提升集群中的计算效率。
英伟达3090则是一款旗舰级游戏加速器,虽然也可以用于AI和机器学习运算,但其主要优势在于游戏性能方面。它具有更高的显存容量,更多的CUDA核心和更高的时钟频率,使其在游戏和渲染应用中性能更强。
A100适用于专业数据中心的大规模计算需求,而3090适合游戏和渲染场合的高性能需求。
英伟达A100是一款面向数据中心的计算加速器,其主要优势是支持数据中心最新的AI、机器学习和高性能计算工作负载。它配备了专门的张量核心和加速器,可以比普通GPU更快地实现深度学习训练和推理操作,具有更高的计算精度和更大的内存容量。
英伟达A100是一款基于英伟达Ampere架构的高性能计算卡,主要面向数据中心和高性能计算领域。其拥有高达6912个CUDA核心和432个Turing Tensor核心,可以实现高达19.5 TFLOPS的FP32浮点性能和156 TFLOPS的深度学习性能。此外,它还支持NVIDIA GPU Boost技术和32GB HBM2显存,能够提供卓越的计算性能和内存宽带。英伟达A100还配备了英伟达的第三代NVLink互连技术和第二代NVSwitch交换机,可以实现高带宽、低延迟的GPU-GPU通信,提升集群中的计算效率。
英伟达3090则是一款旗舰级游戏加速器,虽然也可以用于AI和机器学习运算,但其主要优势在于游戏性能方面。它具有更高的显存容量,更多的CUDA核心和更高的时钟频率,使其在游戏和渲染应用中性能更强。
A100适用于专业数据中心的大规模计算需求,而3090适合游戏和渲染场合的高性能需求。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
数据中心
+关注
关注
18文章
5772浏览量
75208 -
机器学习
+关注
关注
67文章
8565浏览量
137226 -
英伟达
+关注
关注
23文章
4115浏览量
99633 -
A100
+关注
关注
0文章
28浏览量
8160 -
AI芯片
+关注
关注
17文章
2164浏览量
36869
发布评论请先 登录
相关推荐
热点推荐
SiC+GaN成核心!一文汇总英伟达800V HVDC认证厂商解决方案
电子发烧友网报道(文/梁浩斌)AI芯片的功率在算力需求迭代的基础上,不断提高,短短几年间,英伟达的GPU从A100单个TDP 为300W(40GB)和400W(80GB),到目前GB300单芯片
施耐德电气与英伟达深化合作以构建高效吉瓦级AI工厂
施耐德电气携手英伟达联合发布全新Vera Rubin参考设计,为英伟达最新机架级系统提供经过验证的供配电与冷却方案。
新思科技与英伟达多项硬核科技成果亮相GTC 2026
新思科技(Synopsys, Inc.,纳斯达克股票代码:SNPS)在英伟达 GTC 2026 大会(NVIDIA GTC 2026)上,展示了其与英伟达战略合作的最新成果,携手重塑千

英伟达重磅出手!AI 推理存储全面觉醒
电子发烧友网报道(文/黄晶晶)近日,有消息称,英伟达将以大约200亿美元收购人工智能芯片初创公司Groq,这将是英伟达迄今为止规模最大的一笔收购。但

黄仁勋:英伟达AI芯片订单排到2026年 英伟达上季营收加速增长62%再超预期
AI芯片总龙头英伟达的财报终于带来了惊喜;英伟达公司发布财报数据显示,上季营收加速增长62%;再超华尔街预期。业界都比较振奋,英伟
新手小白必看!关于A100云主机租用,你想知道的一切都在这!
“我想租一台A100云主机来跑我的模型,但完全不知道从何下手。”——这是我们听到最多的来自AI新手的声音。A100,这个听起来就“高大上”的名词,背后其实是一套清晰、可操作的流程。今天,我们就用

NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备
给大家分享一些NVIDIA新闻: 英伟达10亿美元入股诺基亚 在当地时间10月28日,英伟达正式宣布将以10亿美元入股诺基亚;据悉英伟
英伟达最新B30A芯片曝光:算力角逐中的新变数
在全球AI芯片市场风云变幻之际,英伟达再次成为焦点。据路透社8月19日报道,两位知情人士透露,英伟达正在为中国市场开发一款基于其最新Blackwell架构的新型人工智能芯片——B30
传英伟达自研HBM基础裸片
电子发烧友网综合报道,据台媒消息,传闻英伟达已开始开发自己的HBM基础裸片,预计英伟达的自研HBM基础裸片采用3nm工艺制造,计划在2027年下半年进行小批量试产。并且这一时间点大致对
外媒:英伟达正开发新款中国特供芯片B30A 或为旗舰AI芯品B300的阉割版
我们看到英伟达的旗舰新品 B300备受关注;但是受限于美国实施出口限制措施,英伟达不会出货,就像此前英伟
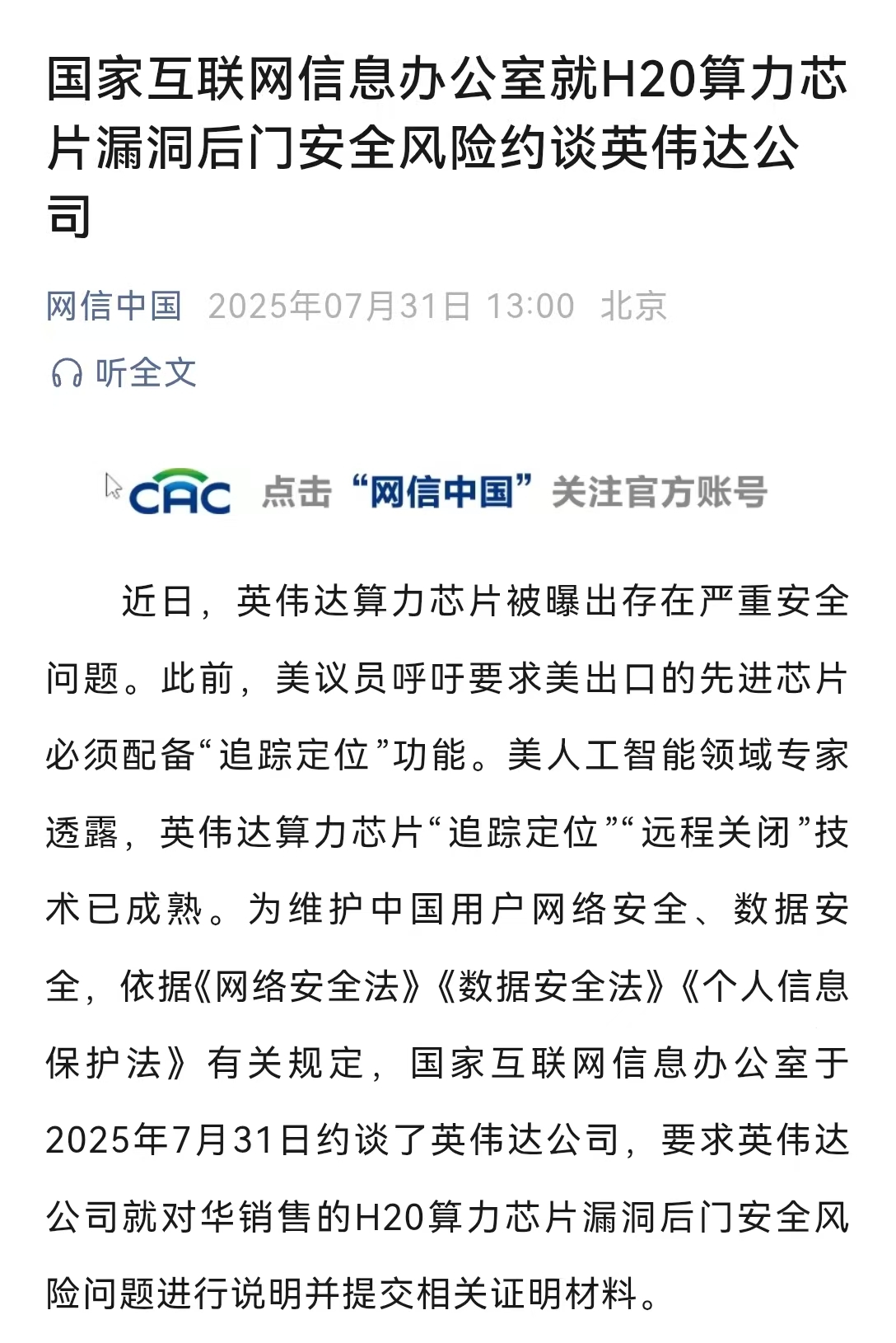
国家网信办约谈英伟达
近日,英伟达算力芯片被曝出存在严重安全问题。此前,美议员呼吁要求美出口的先进芯片必须配备“追踪定位”功能。美人工智能领域专家透露,英伟达算力芯片“追踪定位”“远程关闭”技术已成熟。为维
GPU 维修干货 | 英伟达 GPU H100 常见故障有哪些?
ABSTRACT摘要本文主要介绍英伟达H100常见的故障类型和问题。JAEALOT2025年5月5日今年,国家政府报告提出要持续推进“人工智能+”行动,大力发展人工智能行业,市场上对算力的需求持续



评论