 利用 Superb AI Suite 和 NVIDIA TAO Toolkit 创建高质量的计算机视觉应用
利用 Superb AI Suite 和 NVIDIA TAO Toolkit 创建高质量的计算机视觉应用

数据标记和模型训练一直被认为是团队在构建 AI 或机器学习基础设施时所面临的最大挑战。两者都是机器学习应用开发过程中的重要步骤,如果执行不当就会导致结果不准确和性能下降。
数据标记对于所有形式的监督学习来说都是必不可少的。在监督学习中,整个数据集会被完全标记。同时,数据标记也是半监督学习的一个关键步骤。在半监督学习中,需要将较小的标记数据集与以编程方式自动标记其余数据集的算法相结合。对于最先进、最发达的机器学习领域之一的计算机视觉来说,标记至关重要。尽管数据标记十分重要,标记速度却因为需要调节分散的人力团队而十分缓慢。
与标记一样,模型训练是机器学习的另一个主要瓶颈。由于需要等待机器完成复杂的计算,训练速度很慢。它要求团队必须了解网络、分布式系统、存储、专用处理器(GPU 或 TPU)和云管理系统(Kubernetes 和 Docker)。
应用 NVIDIA TAO Toolkit 的
Superb AI Suite
Superb AI 为计算机视觉团队带来了一种既可以提供高质量训练数据集,同时又能大幅减少所需时间的途径。团队可以在大部分数据准备流程中使用 Superb AI Suite 来实现更加节省时间和成本的流程,不再依赖人工标记员。
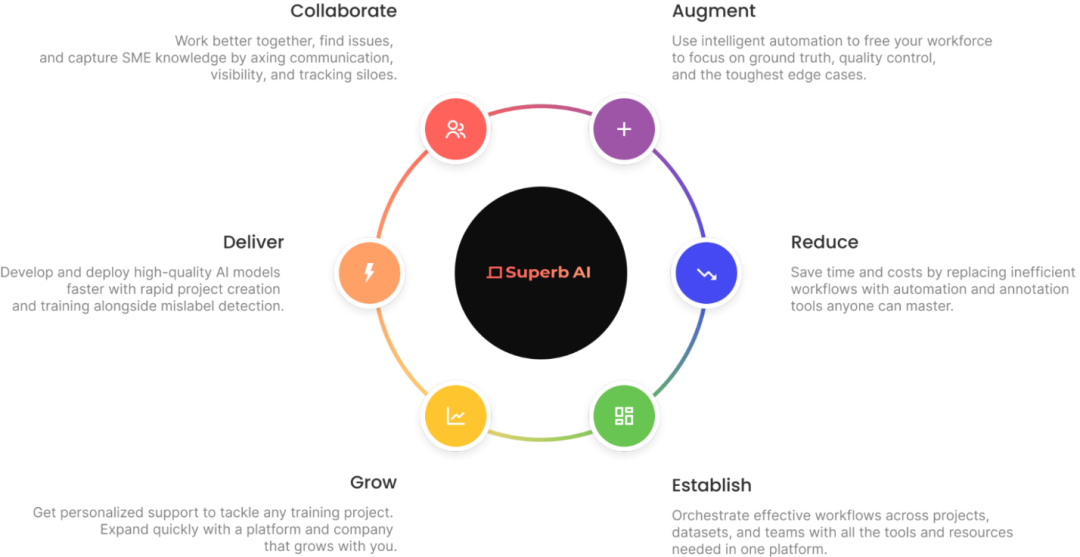
图 1. Superb AI Suite提供覆盖
整个数据生命周期的产品和服务
NVIDIA TAO Toolkit建立在 TensorFlow 和 PyTorch上,是 TAO 框架的低代码版本,能够以抽象化的方式降低框架的复杂性,加快模型的开发流程。TAO Toolkit 使用户能够借助强大的迁移学习,使用自己的数据对 NVIDIA 预先训练的模型进行微调,并对推理进行优化。
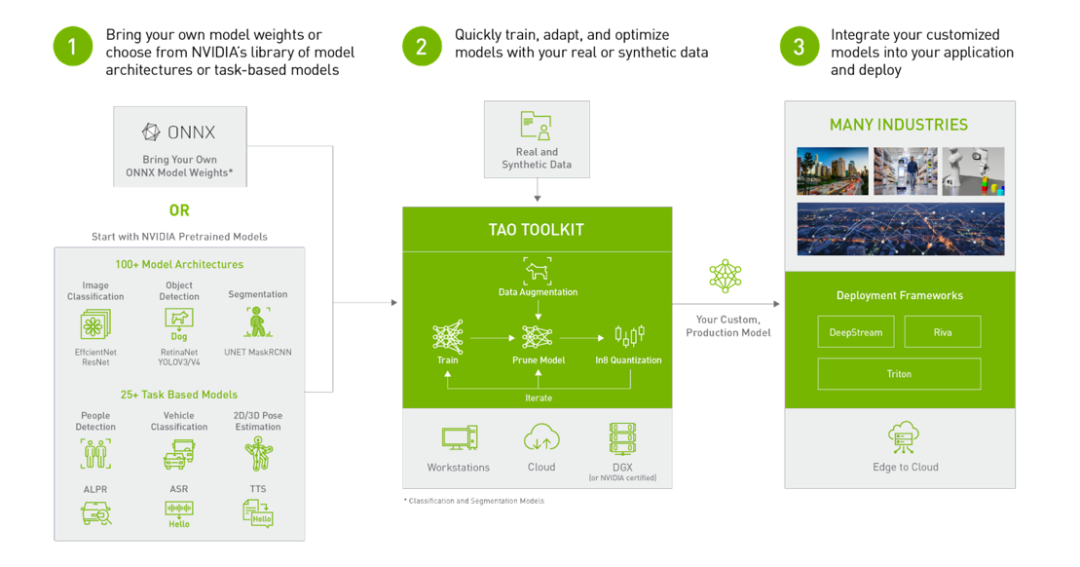
图 2. NVIDIA TAO Toolkit 4.0 一览
计算机视觉工程师可以结合使用 Superb AI Suite 和 TAO Toolkit 解决数据标记和模型训练的难题。具体就是在套件中快速生成标记的数据,并使用 TAO 训练模型来执行分类、检测、分割等特定的计算机视觉任务。
计算机视觉数据集的准备
接下来将为您演示如何使用 Superb AI Suite 准备一个兼容 TAO Toolkit 的高质量计算机视觉数据集。我们将介绍如何下载数据集、在 Suite 上创建新项目、通过 Suite SDK 将数据上传到项目中、使用 Superb AI 的自动标记功能快速标记数据集、导出已标记的数据集,以及设置 TAO Toolkit 配置以使用这些数据。
第 1 步:从使用 Suite SDK 开始
首先,在superb-ai.com 创建一个帐户,然后按照快速入门指南安装并验证 Suite CLI。您应该能够安装最新版本的 spb-cli,并获取用于身份验证的 Suite 账户名/ 访问密钥。
第 2 步:下载数据集
本教程使用的是 COCO 数据集。这个大型对象检测、分割和字幕数据集在计算机视觉研究界深受欢迎。
您可以使用此链接中的代码片段下载该数据集 (https://github.com/Superb-AI-Suite/spb-example/blob/main/create-coco-project/download-coco.sh)。将其保存在一个名为 download-coco.sh 的文件中,并从终端运行 bash download-coco.sh,创建一个存储 COCO 数据集的 data/ 目录。
下一步是将 COCO 转换成 Suite SDK 格式,以便对 COCO validation 2017 数据集中的五个最频繁使用的数据类别进行采样。本教程只处理边界框注释,但 Suite 也可以处理多边形和关键点。
您可以使用此链接中的代码片段执行转换 (https://github.com/Superb-AI-Suite/spb-example/blob/main/create-coco-project/convert.py)。将其保存在一个名为 convert.py 的文件中,并从终端运行 python convert.py。这将创建一个用于存储图像名称和注释信息的 upload-info.json 文件。
第 3 步:在 Suite SDK 中创建一个项目
通过 Suite SDK 创建项目的功能目前仍在开发中。在本次教学中,我们根据 Superb AI 项目创建指南在网络上创建一个项目。请按照下图进行设置:
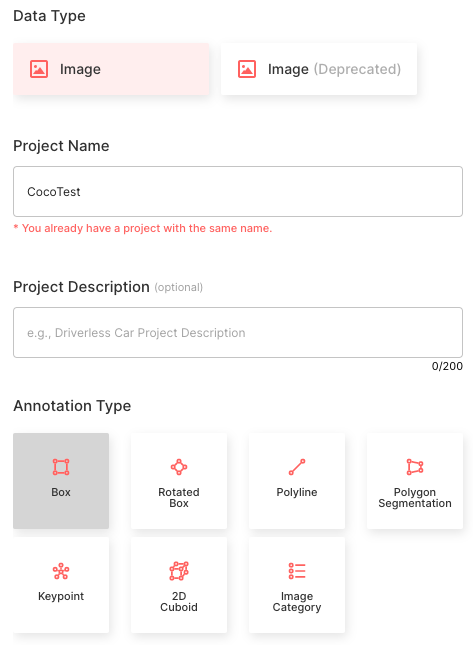
图 3. Superb AI 项目创建菜单
-
选择图像数据类型
-
将项目名称设置为 CocoTest
-
注释类型选择“边界框”
-
创建五个匹配 COCO 类名称的对象类:['person'、'car'、'chair'、'book'、'bottle']
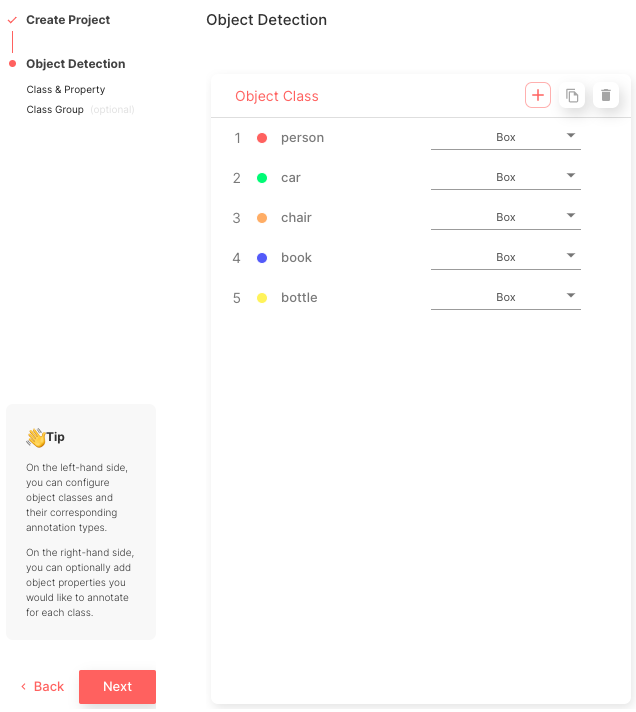
图 4. 在创建流程的这一步选择和定义项目的对象类
如图 5 所示,完成该流程后,您可以查看项目的主页面。
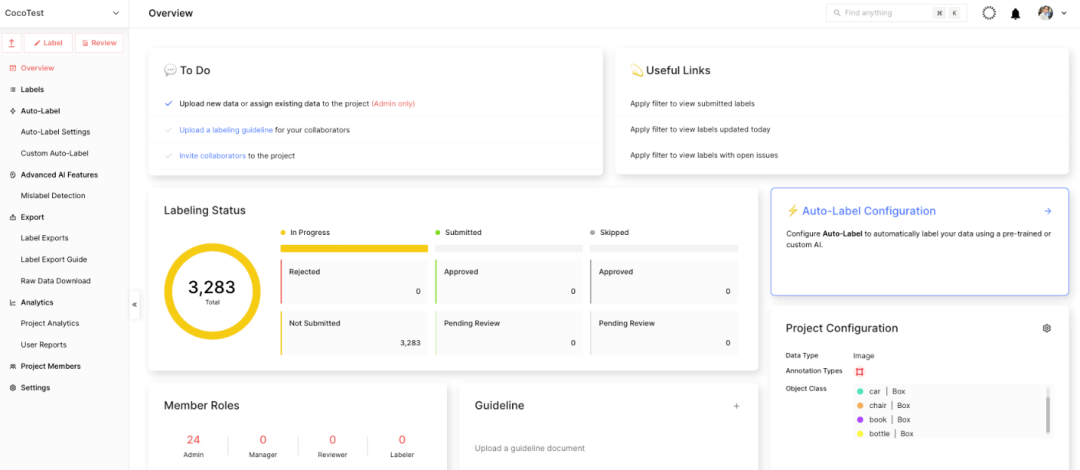
图 5. Superb AI Suite 项目主页面
第 4 步:使用 Suite SDK 上传数据
在创建完项目后,就可以开始上传数据了。您可以使用此链接中的代码片段上传数据 (https://github.com/Superb-AI-Suite/spb-example/blob/main/create-coco-project/upload.py)。将其保存在一个名为 upload.py 的文件中,然后在终端运行 python upload.py --project CocoTest --dataset coco-dataset。
这表示 CocoTest 是项目名称,coco-dataset 是数据集名称。然后将启动上传流程,可能需要几个小时才能完成上传,具体时间取决于设备的处理能力。
如图 6 所示,您可以在 Suite 网页上实时检查上传的数据集。
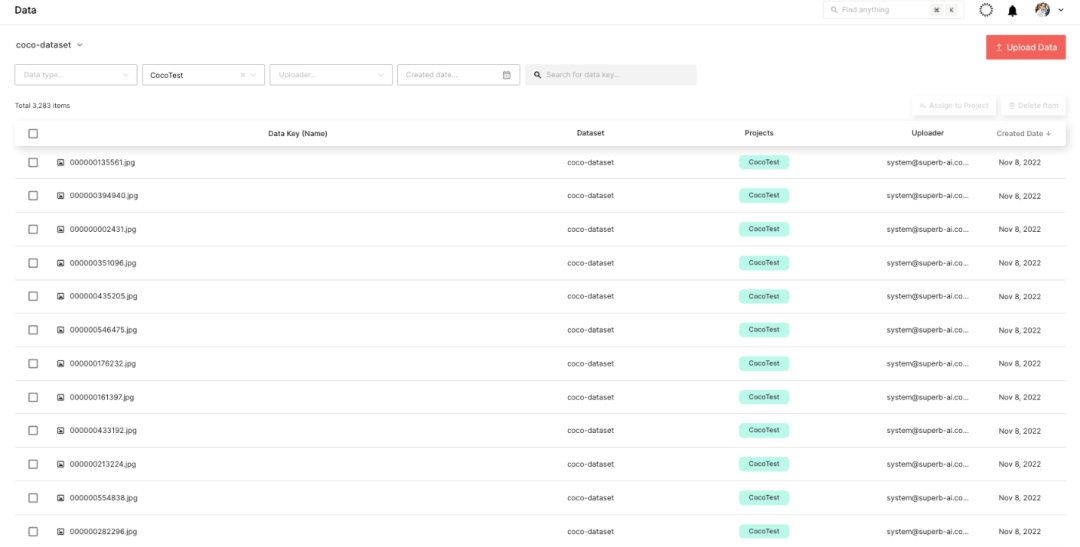
图 6. 通过 Suite 列表视图实时监控上传的数据集
第 5 步:标记数据集
下一步是标记 COCO 数据集。为了快速完成这项工作,请使用 Suite 强大的自动标记功能。具体来讲就是 Auto-Label 和 Custom Auto-Label 这两个强大的工具,会通过自动检测对象并进行标记来提高标记效率。
Auto-Label 是一个由 Superb AI 开发的预训练模型,可检测和标记 100 多个常见对象;Custom Auto-Label 是一个使用您自己的数据训练的模型,可检测和标记小众对象。
本教程中的 COCO 数据由五个能够被 Auto-Label 标记的常见对象组成。请按照链接中的指南设置 Auto-Label(https://docs.superb-ai.com/docs/image)。请注意,应选择 MSCO Box CAL 作为 Auto-Label 的 AI,并将对象名称与各自应用的对象进行映射。处理 COCO 数据集中的所有 3283 个标签可能需要大约一个小时。
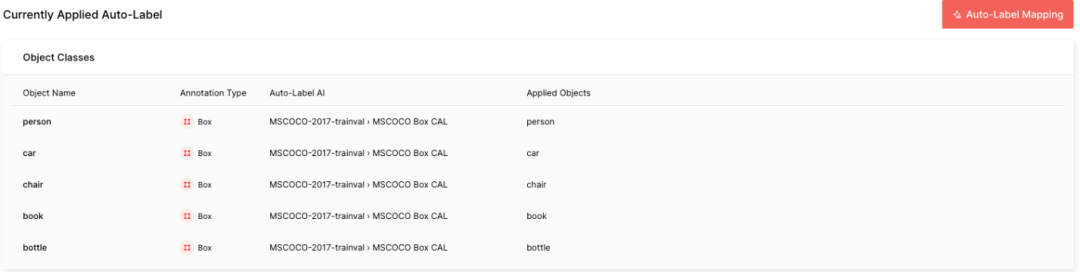
图 7. 创建完毕的 Auto-Label中的对象类设置
Auto-Label 运行完毕后,您会看到每个自动标记任务的难度:红色代表困难,黄色代表中等,绿色代表容易。难度越高,自动标记对图像进行错误标记的可能性就越大。
这种难度,或者说所估测的不确定性是根据对象尺寸的大小、照明条件的优劣、场景的复杂度等因素计算出来的。在实际使用时,您可以很容易地按照难度对标签进行分类和筛选,以便优先处理出错几率较高的标签。
第 6 步:从 Suite 中导出标记的数据集
在获得标记的数据集后,导出并下载标签。标签内容不仅仅是注释信息。为了充分利用一个标签来训练机器学习模型,您还必须知道其他信息,比如项目配置和关于原始数据的元信息。要想连同注释文件一起下载所有这些信息,首先要请求导出,以便 Suite 系统可以创建一个供下载的压缩文件。按照指南,从 Suite 中导出并下载标签 (https://docs.superb-ai.com/docs/export-and-download-labels)。
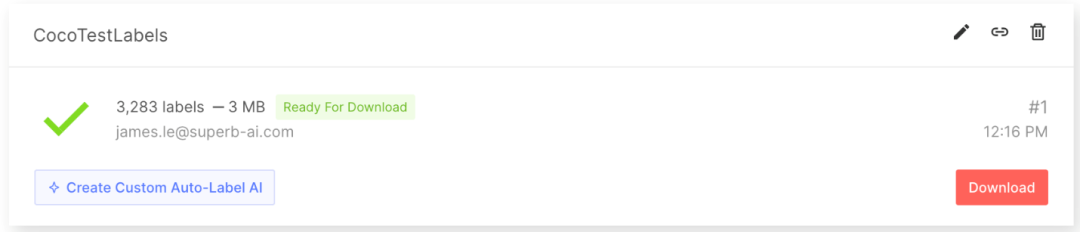
图 8. 通过用户界面导出数据集
在导出标签时,将创建一个压缩好的 zip 文件供您下载。导出结果文件夹将包含关于整个项目的基本信息、每个标签的注释信息以及每个数据资产的元数据。更多细节请参见导出结果格式文件 (https://docs.superb-ai.com/docs/export-result-format)。
第 7 步:将输出结果转换成 COCO 格式
接下来,创建一个脚本,将您的标签数据转换成可以输入到 TAO Toolkit 的格式,比如 COCO 格式。请注意,因为本教程使用的是 COCO 数据集,所以数据已经是 COCO 格式了。例如,您可以在下面找到一个随机导出标签的 JSON 文件:
{
"objects": [
{
"id": "7e9fe8ee-50c7-4d4f-9e2c-145d894a8a26",
"class_id": "7b8205ef-b251-450c-b628-e6b9cac1a457",
"class_name": "person",
"annotation_type": "box",
"annotation": {
"multiple": false,
"coord": {
"x": 275.47,
"y": 49.27,
"width": 86.39999999999998,
"height": 102.25
},
"meta": {},
"difficulty": 0,
"uncertainty": 0.0045
},
"properties": []
},
{
"id": "70257635-801f-4cad-856a-ef0fdbfdf613",
"class_id": "7b8205ef-b251-450c-b628-e6b9cac1a457",
"class_name": "person",
"annotation_type": "box",
"annotation": {
"multiple": false,
"coord": {
"x": 155.64,
"y": 40.61,
"width": 98.34,
"height": 113.05
},
"meta": {},
"difficulty": 0,
"uncertainty": 0.0127
},
"properties": []
}
],
"categories": {
"properties": []
},
"difficulty": 1
}
第 8 步:准备好用于模型训练的标记数据
接下来,使用 SuiteDataset 将 COCO 数据从 Suite 导入到模型开发。SuiteDataset 使 Suite 中导出的数据集可以通过 PyTorch 数据管道访问。下面的代码片段将用于训练集的 SuiteDataset 对象类进行了实例化。
class SuiteDataset(Dataset):
"""
Instantiate the SuiteDataset object class for training set
"""
def __init__(
self,
team_name: str,
access_key: str,
project_name: str,
export_name: str,
train: bool,
caching_image: bool = True,
transforms: Optional[List[Callable]] = None,
category_names: Optional[List[str]] = None,
):
"""Function to initialize the object class"""
super().__init__()
# Get project setting and export information through the SDK
# Initialize the Python Client
client = spb.sdk.Client(team_name=team_name, access_key=access_key, project_name=project_name)
# Use get_export
export_info = call_with_retry(client.get_export, name=export_name)
# Download the export compressed file through download_url in Export
export_data = call_with_retry(urlopen, export_info.download_url).read()
# Load the export compressed file into memory
with ZipFile(BytesIO(export_data), 'r') as export:
label_files = [f for f in export.namelist() if f.startswith('labels/')]
label_interface = json.loads(export.open('project.json', 'r').read())
category_infos = label_interface.get('object_detection', {}).get('object_classes', [])
cache_dir = None
if caching_image:
cache_dir = f'/tmp/{team_name}/{project_name}'
os.makedirs(cache_dir, exist_ok=True)
self.client = client
self.export_data = export_data
self.categories = [
{'id': i + 1, 'name': cat['name'], 'type': cat['annotation_type']}
for i, cat in enumerate(category_infos)
]
self.category_id_map = {cat['id']: i + 1 for i, cat in enumerate(category_infos)}
self.transforms = build_transforms(train, self.categories, transforms, category_names)
self.cache_dir = cache_dir
# Convert label_files to numpy array and use
self.label_files = np.array(label_files).astype(np.string_)
def __len__(self):
"""Function to return the number of label files"""
return len(self.label_files)
def __getitem__(self, idx):
"""Function to get an item"""
idx = idx if idx >= 0 else len(self) + idx
if idx < 0 or idx >= len(self):
raise IndexError(f'index out of range')
image_id = idx + 1
label_file = self.label_files[idx].decode('ascii')
# Load label information corresponding to idx from the export compressed file into memory
with ZipFile(BytesIO(self.export_data), 'r') as export:
label = load_label(export, label_file, self.category_id_map, image_id)
# Download the image through the Suite sdk based on label_id
try:
image = load_image(self.client, label['label_id'], self.cache_dir)
# Download data in real time using get_data from Suite sdk
except Exception as e:
print(f'Failed to load the {idx}-th image due to {repr(e)}, getting {idx + 1}-th data instead')
return self.__getitem__(idx + 1)
target = {
'image_id': image_id,
'label_id': label['label_id'],
'annotations': label['annotations'],
}
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target
请以类似的方式处理测试集。下面的代码片段通过包裹 SuiteDataset 使其与 Torchvision COCOEvaluator 兼容,将用于测试集的 SuiteCocoDataset 对象类实例化。
class SuiteCocoDataset(C.CocoDetection):
"""
Instantiate the SuiteCocoDataset object class for test set
(by wrapping SuiteDataset to make compatible with torchvision's official COCOEvaluator)
"""
def __init__(
self,
team_name: str,
access_key: str,
project_name: str,
export_name: str,
train: bool,
caching_image: bool = True,
transforms: Optional[List[Callable]] = None,
category_names: Optional[List[str]] = None,
num_init_workers: int = 20,
):
"""Function to initialize the object class"""
super().__init__(img_folder='', ann_file=None, transforms=None)
# Call the SuiteDataset class
dataset = SuiteDataset(
team_name, access_key, project_name, export_name,
train=False, transforms=[],
caching_image=caching_image, category_names=category_names,
)
self.client = dataset.client
self.cache_dir = dataset.cache_dir
self.coco = build_coco_dataset(dataset, num_init_workers)
self.ids = list(sorted(self.coco.imgs.keys()))
self._transforms = build_transforms(train, dataset.categories, transforms, category_names)
def _load_image(self, id: int):
"""Function to load an image"""
label_id = self.coco.loadImgs(id)[0]['label_id']
image = load_image(self.client, label_id, self.cache_dir)
return image
def __getitem__(self, idx):
"""Function to get an item"""
try:
return super().__getitem__(idx)
except Exception as e:
print(f'Failed to load the {idx}-th image due to {repr(e)}, getting {idx + 1}-th data instead')
return self.__getitem__(idx + 1)
然后,可以将 SuiteDataset 和 SuiteCocoDataset 用于您的训练代码。下面的代码片段说明了如何使用它们。在模型开发过程中,可以使用 train_loader 进行训练并使用 test_loader 进行评估。
train_dataset = SuiteDataset(
team_name=args.team_name,
access_key=args.access_key,
project_name=args.project_name,
export_name=args.train_export_name,
caching_image=args.caching_image,
train=True,
)
test_dataset = SuiteCocoDataset(
team_name=args.team_name,
access_key=args.access_key,
project_name=args.project_name,
export_name=args.test_export_name,
caching_image=args.caching_image,
train=False,
num_init_workers=args.workers,
)
train_loader = DataLoader(
num_workers=args.workers,
batch_sampler=G.GroupedBatchSampler(
RandomSampler(train_dataset),
k=3),
args.batch_size,
),
collate_fn=collate_fn,
)
test_loader = DataLoader(
num_workers=args.workers,
sampler=SequentialSampler(test_dataset), batch_size=1,
collate_fn=collate_fn,
)
第 9 步:使用 NVIDIA TAO Toolkit 训练您的模型
现在,可以将 Suite 注释的数据用于训练您的对象检测模型了。TAO Toolkit 使您能够训练、微调、修剪和输出经过高度优化的高精度计算机视觉模型,以便根据数据采用流行的网络架构和骨干网来完成部署。在本次教学中,您可以选择 TAO 自带的对象检测模型 YOLO v4。
首先,从 TAO Toolkit 快速入门(https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/resources/tao-getting-started)下载适用于 notebook 的样本。
pip3 install nvidia-tao
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/tao-getting-started/versions/4.0.1/zip -O getting_started_v4.0.1.zip
$ unzip -u getting_started_v4.0.1.zip -d ./getting_started_v4.0.1 && rm -rf getting_started_v4.0.1.zip && cd ./getting_started_v4.0.1
接下来,使用下面的代码启动notebook:
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
在 localhost 上打开网页浏览器并前往以下地址:
http://0.0.0.0:8888
如要创建一个 YOLO v4 模型,请打开:
notebooks/tao_launcher_starter_kit/yolo_v4/yolo_v4.ipynb and follow the
并按照notebook上的说明训练模型。
根据结果对模型进行微调,直到达到指标要求。如果需要的话,您可以在这个阶段创建您自己的主动学习循环。在现实场景中,查询预测失败的样本,指派人工标记员对这批新的样本数据进行注释,并使用新标记的训练数据补充您的模型。在随后的几轮模型开发中,Superb AI 套件可以进一步协助您进行数据采集和注释,从而反复提高模型的性能。
使用 TAO Toolkit 4.0,无需任何 AI 专业知识,可以更加轻松地开始创建高精度的模型。可以使用 AutoML 自动微调您的超参数、体验一键将 TAO Toolkit 部署到各种云服务中、将 TAO Toolkit 与第三方 MLOPs 服务集成并探索新的基于 Transformer 的视觉模型 (CitySemSegformer, Peoplenet Transformer)。
总结
计算机视觉领域的数据标记会带来许多独特的挑战。由于需要标记的数据量大,这个过程可能十分困难且昂贵。此外,由于这个过程是主观的,使得在一个大型数据集中实现一致的高质量标记输出非常困难。
由于需要调整和优化许多算法与超参数,模型训练也可能极具挑战性。在这个过程中,需要对数据和模型有深刻的了解,并进行大量实验才能达到最佳效果。此外,训练计算机视觉模型往往需要耗费大量算力,因此在预算和时间有限的情况下很难做到。
Superb AI Suite 能够帮助您采集和标记高质量的计算机视觉数据集,而 NVIDIA TAO Toolkit 使您能够优化预先训练的计算机视觉模型。将两者相结合,就可以在不牺牲质量的前提下,大幅缩短计算机视觉应用的开发时间。
更多信息,敬请访问:
-
TAO Toolkit Google Colab notebook(https://colab.research.google.com/github/NVIDIA-AI-IOT/nvidia-tao/blob/main/tensorflow/yolo_v4/yolo_v4.ipynb)
-
TAO Toolkit 文档(https://docs.nvidia.com/tao/tao-toolkit/index.html)
-
Superb AI Suite 标记平台(https://superb-ai.com/product/labeling/)
-
Superb AI Suite 文档(https://docs.superb-ai.com/docs/)
原文标题:利用 Superb AI Suite 和 NVIDIA TAO Toolkit 创建高质量的计算机视觉应用
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4119浏览量
99677
原文标题:利用 Superb AI Suite 和 NVIDIA TAO Toolkit 创建高质量的计算机视觉应用
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
传音相关研究成果入选计算机视觉顶会CVPR 2026

声智科技亮相2026海淀区经济社会高质量发展大会
上海计算机视觉企业行学术沙龙走进西井科技
华为出席智慧校园赋能教育教学高质量发展研讨会
上海市计算机行业协会携手深兰科技推动人工智能高质量发展
飞腾一体机主板为工业转型升级和高质量发展注入强大动力
NVIDIA DGX Spark桌面AI计算机开启预订

索尼重载设备的高质量远程制作方案和应用(2)

大模型时代,如何推进高质量数据集建设?
NVIDIA助力AI超级计算机Isambard-AI投入使用
自动化计算机的功能与用途

NVIDIA驱动的现代超级计算机如何突破速度极限并推动科学发展



评论