 AI大模型网络如何搭建
AI大模型网络如何搭建

2023年,以ChatGPT为代表的AIGC大模型全面崛起,成为了整个社会关注的焦点。 大模型表现出了强悍的自然语言理解能力,刷新了人们对AI的认知,也掀起了新一轮的“算力军备竞赛”。 大家都知道,AIGC大模型的入局门槛是很高的。玩AI的三大必备要素——算力、算法和数据,每一个都意味着巨大的投入。 以算力为例。ChatGPT的技术底座,是基于微调后的GPT3.5大模型,参数量多达1750亿个。为了完成这个大模型的训练,微软专门建设了一个AI超算系统,投入了1万个V100 GPU,总算力消耗约3640 PF-days(即假如每秒计算一千万亿次,需要计算3640天)。 业内头部厂商近期推出的大模型,参数量规模更是达到万亿级别,需要的GPU更多,消耗的算力更大。 这些数量庞大的GPU,一定需要通过算力集群的方式,协同完成计算任务。这就意味着,需要一张超高性能、超强可靠的网络,才能把海量GPU联接起来,形成超级计算集群。 那么,问题来了,这张网络,到底该如何搭建呢?
高性能网络的挑战 想要建设一张承载AIGC大模型的网络,需要考虑的因素非常多。 首先,是网络规模。 刚才我们也提到,AI训练都是10000个GPU起步,也有的达到十万级。从架构上,目标网络就必须hold得住这么多的计算节点。而且,在节点增加的同时,集群算力尽量线性提升,不能引入过高的通信开销,损失算力。 其次,是网络带宽。 超高性能的GPU,加上千亿、万亿参数的训练规模,使得计算节点之间的通信量,达到了百GB量级。再加上各种并行模式、加速框架的引入,节点之间的通道带宽需求会更高。 传统数据中心通用的100Gbps带宽接入,根本满足不了这个需求。我们的目标网络,接入带宽必须升级到800Gbps、1.6Tbps,甚至更高。 第三,流量调控。 传统的网络架构,在应对AI大模型训练产生的数据流时,存在缺陷。所以,目标网络需要在架构上做文章,更好地控制数据流路径,让节点和通道的流量更均衡,避免发生拥塞。 第四,协议升级。 网络协议是网络工作的行为准则。它的好坏,直接决定了网络的性能、效率和延迟。 传统数据中心的TCP/IP协议,早已已无法满足高性能网络的大带宽、低时延需求。性能更强的IB(InfiniBand)协议、RDMA协议,已然成为主流。有实力的厂家,还会基于自家硬件设备,自研更高效的协议。 第五,运维简化。 这就不用多说了。超大规模的网络,如果还是采用传统运维,不仅效率跟不上,还会导致更长的故障恢复周期,损失算力,损失资金。 目前,行业里的“大模头”们,都会根据自己技术和资金实力,选择商用网络组网,或者自研网络协议。 大家心里很清楚,想要赢得这场比赛,除了算力芯片足够强之外,网络的性能表现是至关重要的。网络越强,集群的算力提升就越大,完成模型训练的时间就越短,成本也就越低。
星脉网络,鹅厂的算力集群杀手锏 对于AI大模型这场热潮,腾讯当然不会缺席。他们推出了业界领先的高性能计算网络架构——星脉。 腾讯深耕互联网行业20多年,从QQ到微信,他们的超大规模业务承载能力,可以说是行业顶尖的。在网络技术的理解和驾驭能力上,也是世界领先水平。而星脉,则是他们多年技术研究的精髓,是真正的杀手锏。 根据实测,星脉实现了AI大模型通信性能的10倍提升、GPU利用率提升40%、通信时延降低40%。 基于全自研的网络硬件平台,星脉可以实现网络建设成本降低30%,模型训练成本节省30%~60%。 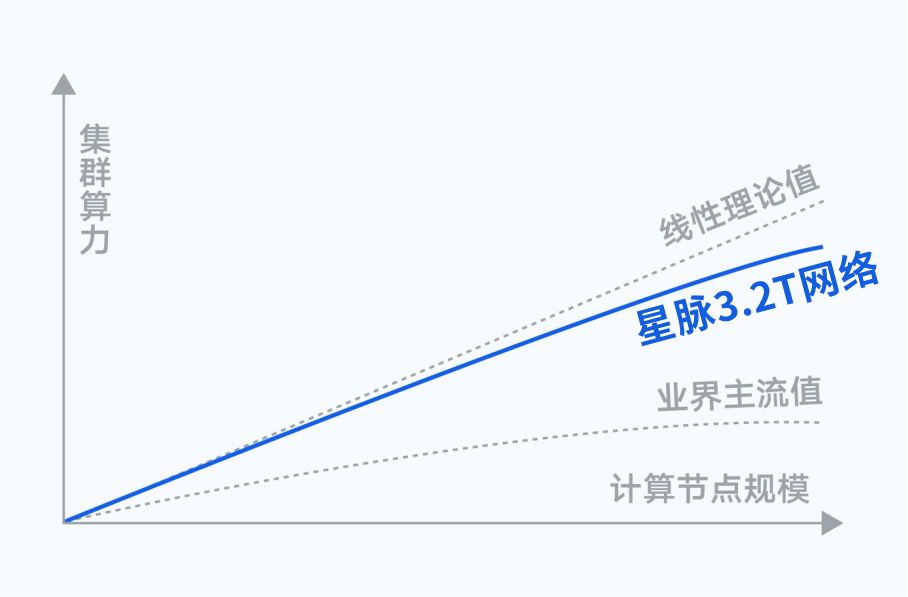 星脉网络的算力效率,远高于业界主流值 接下来,我们不妨深入解读一下,星脉到底采用了哪些黑科技。在前面所提到的几项挑战上,腾讯团队又是如何应对的。
星脉网络的算力效率,远高于业界主流值 接下来,我们不妨深入解读一下,星脉到底采用了哪些黑科技。在前面所提到的几项挑战上,腾讯团队又是如何应对的。
网络规模
在组网架构上,星脉网络采用无阻塞胖树(Fat-Tree)拓扑,分为Block-Pod-Cluster三级。 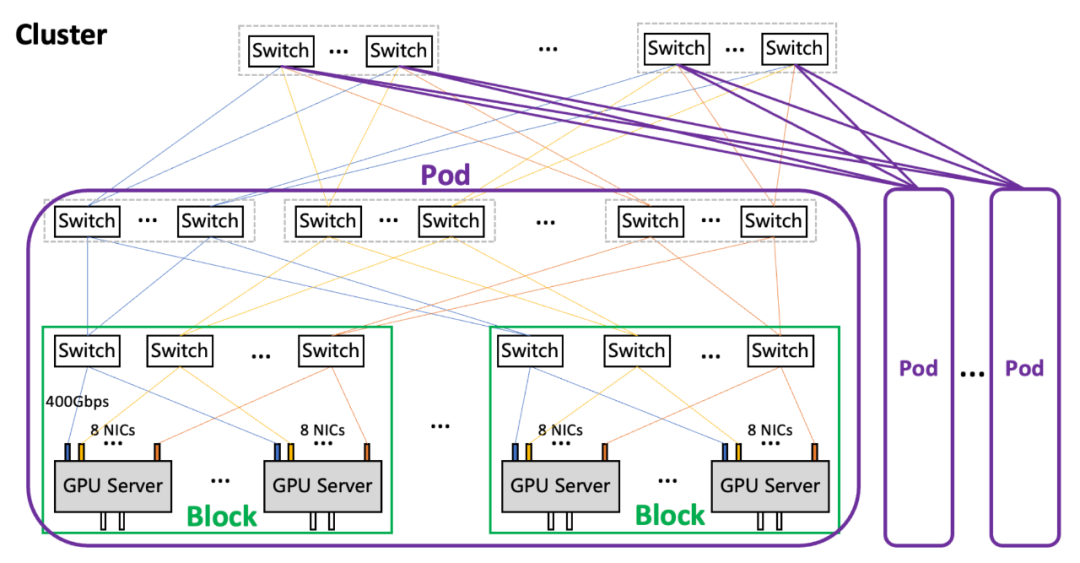 星脉网络的架构 Block是最小单元,包括256个GPU。 Pod是典型集群规模,包括16~64个Block,也就是4096~16384个GPU。 多个Block可以组成Cluster。1个Cluster最大支持16个Pod,也就是65536~262144个GPU。 26万个GPU,这个规模完全能够满足目前的训练需求。
星脉网络的架构 Block是最小单元,包括256个GPU。 Pod是典型集群规模,包括16~64个Block,也就是4096~16384个GPU。 多个Block可以组成Cluster。1个Cluster最大支持16个Pod,也就是65536~262144个GPU。 26万个GPU,这个规模完全能够满足目前的训练需求。
网络带宽
腾讯星脉网络为每个计算节点提供了3.2T的超高通信带宽。 单个服务器(带有8个GPU)就是一个计算节点。每个服务器有8块RoCE网卡。每块网卡的接口速率是400Gbps。 RoCE,是RDMA over Converged Ethernet(基于聚合以太网的RDMA)。RDMA(远程直接GPU通信访问)我们以前介绍过很多次。它允许计算节点之间直接通过内存进行数据传输,无需操作系统内核和CPU的参与,能够大幅减小CPU负荷,降低延迟,提高吞吐量。 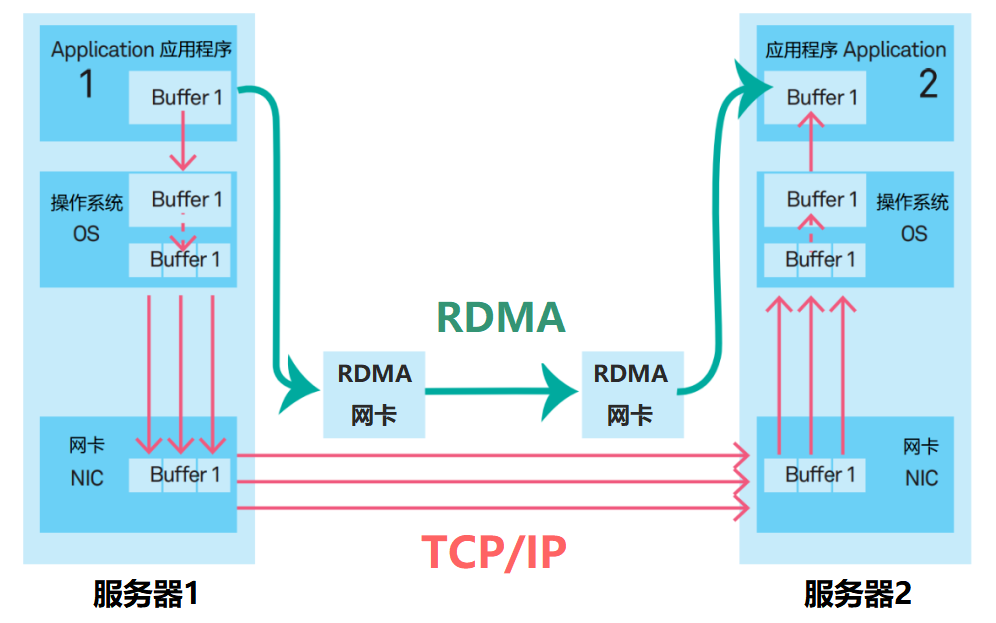 大带宽带来的优势是非常显著的。对于AllReduce和All-to-All这两种典型通信模式,在不同集群规模下,1.6Tbps超带宽都会带来10倍以上的通信性能提升(相比100Gbps带宽)。 以AllReduce模式、64 GPU规模为例,采用1.6Tbps超带宽网络,将使得AllReduce的耗时大幅缩短14倍,通信占比从35%减少到3.7%,最终使得单次迭代的训练耗时减少32%。从集群算力的角度来看,相当于用同样的计算资源,系统算力却提升48%。
大带宽带来的优势是非常显著的。对于AllReduce和All-to-All这两种典型通信模式,在不同集群规模下,1.6Tbps超带宽都会带来10倍以上的通信性能提升(相比100Gbps带宽)。 以AllReduce模式、64 GPU规模为例,采用1.6Tbps超带宽网络,将使得AllReduce的耗时大幅缩短14倍,通信占比从35%减少到3.7%,最终使得单次迭代的训练耗时减少32%。从集群算力的角度来看,相当于用同样的计算资源,系统算力却提升48%。
流量调控
为了提升集群的通信效率,星脉网络对通信流量路径进行了优化,引入了“多轨道流量聚合架构”。 该架构将不同服务器上位于相同位置的网卡,都归属于同一个ToR switch(机柜顶部的汇聚交换机)。整个计算网络平面,从物理上被划分为8个独立并行的轨道平面。 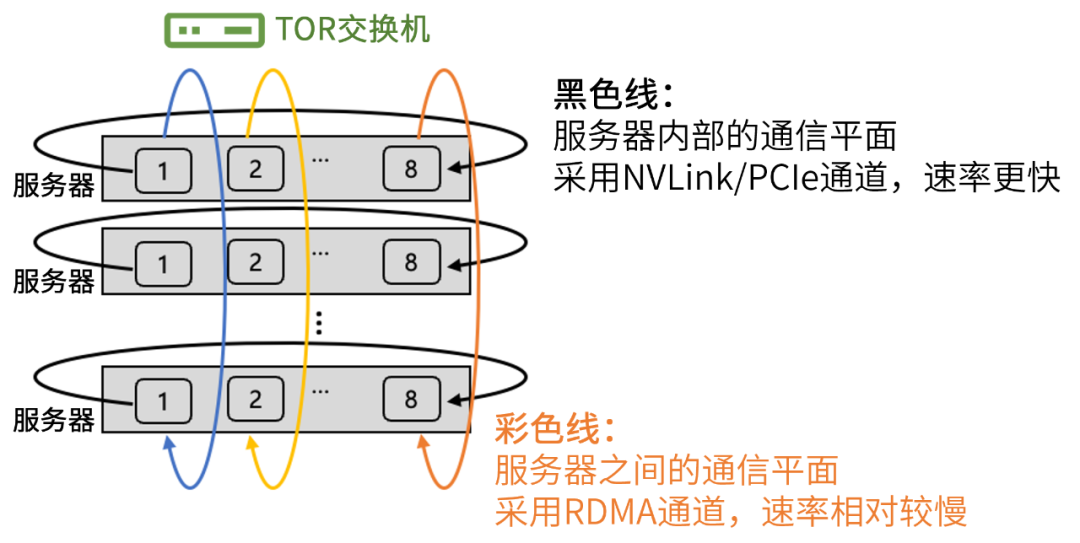 在工作时,GPU之间的数据,可以用多个轨道并行传输加速。并且,大部分流量,都聚合在轨道平面内传输(只经过一级 ToR switch)。只有小部分流量,会跨轨道平面传输(需要经过二级 switch)。这大幅减轻了网络压力。 星脉网络还采用了“异构网络自适应通信技术”。 在集群中,GPU之间的通信包括机间网络(网卡+交换机)与机内网络( NVLink/NVSwitch 网络、PCIe 总线网络)。 星脉网络将机间、机内两种网络同时利用起来,实现了异构网络之间的联合通信优化。 例如,在All-to-All通信模式时,每个GPU都会和其它服务器的不同GPU通信。
在工作时,GPU之间的数据,可以用多个轨道并行传输加速。并且,大部分流量,都聚合在轨道平面内传输(只经过一级 ToR switch)。只有小部分流量,会跨轨道平面传输(需要经过二级 switch)。这大幅减轻了网络压力。 星脉网络还采用了“异构网络自适应通信技术”。 在集群中,GPU之间的通信包括机间网络(网卡+交换机)与机内网络( NVLink/NVSwitch 网络、PCIe 总线网络)。 星脉网络将机间、机内两种网络同时利用起来,实现了异构网络之间的联合通信优化。 例如,在All-to-All通信模式时,每个GPU都会和其它服务器的不同GPU通信。 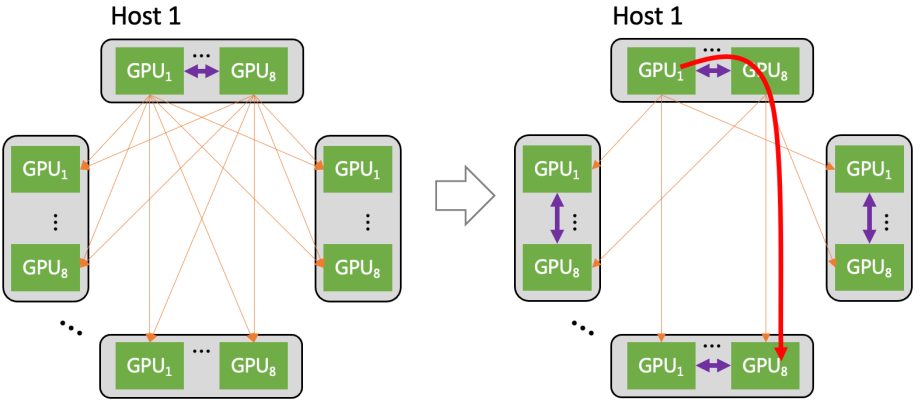 基于异构网络自适应通信技术,不同服务器上相同位置的GPU,在同一轨道平面,仍然走机间网络通信。 但是,要去往不同位置的GPU(比如host1上的GPU1,需要向其它host上的GPU8 送数据),则先通过机内网络,转发到host1上的GPU8上,然后通过机间网络,来完成通信。 这样一来,机间网络的流量,大部分都聚合在轨道内传输(只经过一级 ToR switch)。机间网络的流量大幅减少,冲击概率也明显下降,从而提供了整网性能。 根据实测,异构网络通信在大规模All-to-All场景下,对中小数据包的传输性能提升在30%左右。
基于异构网络自适应通信技术,不同服务器上相同位置的GPU,在同一轨道平面,仍然走机间网络通信。 但是,要去往不同位置的GPU(比如host1上的GPU1,需要向其它host上的GPU8 送数据),则先通过机内网络,转发到host1上的GPU8上,然后通过机间网络,来完成通信。 这样一来,机间网络的流量,大部分都聚合在轨道内传输(只经过一级 ToR switch)。机间网络的流量大幅减少,冲击概率也明显下降,从而提供了整网性能。 根据实测,异构网络通信在大规模All-to-All场景下,对中小数据包的传输性能提升在30%左右。
协议升级
星脉网络采用的“自研端网协同协议TiTa”,可以提供更高的网络通信性能,非常适合大规模参数模型训练。 TiTa协议内嵌拥塞控制算法,可以实时监控网络状态并进行通信优化。它就好比是一个智能交通管理系统,可以让网络上的数据传输更加通畅。 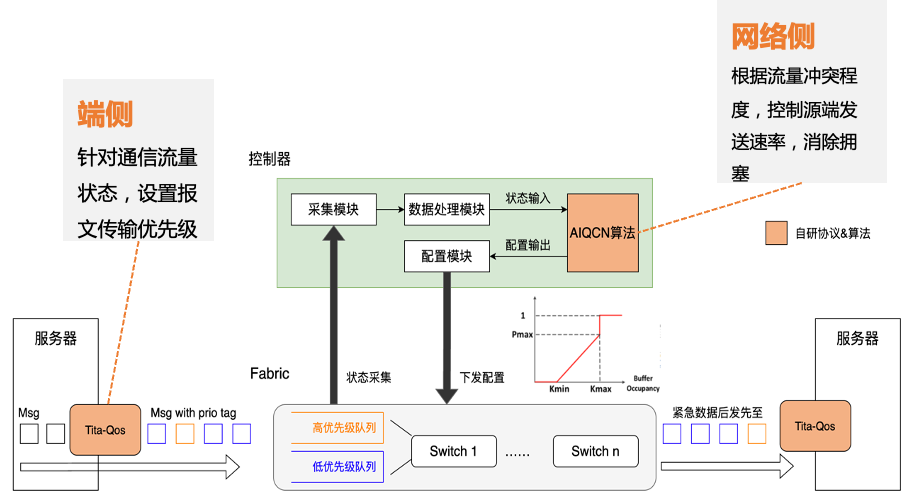 TiTa协议的处理方式 面对定制设计的高性能组网架构,业界开源的GPU集合通信库(例如NCCL)并不能将网络的通信性能发挥到极致。为此,腾讯推出了“高性能集合通信库TCCL(Tencent Collective Communication Library)”。 TCCL就像一个智能导航系统。它在网卡设备管理、全局网络路由、拓扑感知亲和性调度、网络故障自动告警等方面进行了深度定制,对网络了如指掌,让流量路径更加合理。 例如,从GPU A到GPU B,原来需要经过9个路口。有了TCCL导航之后,只需要走4个路口,提升了效率。 根据实测,在AllReduce/AllGather/ReduceScatter等常用通信模式下,TCCL能给星脉网络带来40%左右的通信性能提升。
TiTa协议的处理方式 面对定制设计的高性能组网架构,业界开源的GPU集合通信库(例如NCCL)并不能将网络的通信性能发挥到极致。为此,腾讯推出了“高性能集合通信库TCCL(Tencent Collective Communication Library)”。 TCCL就像一个智能导航系统。它在网卡设备管理、全局网络路由、拓扑感知亲和性调度、网络故障自动告警等方面进行了深度定制,对网络了如指掌,让流量路径更加合理。 例如,从GPU A到GPU B,原来需要经过9个路口。有了TCCL导航之后,只需要走4个路口,提升了效率。 根据实测,在AllReduce/AllGather/ReduceScatter等常用通信模式下,TCCL能给星脉网络带来40%左右的通信性能提升。
部署和运维简化
算力集群网络越庞大,它的部署和维护难度也就越大。 为了提升星脉网络的可靠性,腾讯自研了一套全栈网络运营系统,实现了“端网部署一体化”、“一键故障定位”、“业务无感秒级网络自愈”,对网络进行全方位保驾护航。 先看看“端网部署一体化”。 部署一直都是高性能网络的痛点。在星脉网络之前,根据统计,90%的高性能网络故障问题,是因为配置错误导致。原因很简单,网卡的配置套餐太多(取决于架构版本、业务类型和网卡类型),人为操作很难保证不出错。 腾讯的解决方法,是将配置过程自动化。 他们通过API的方式,实现单台/多台交换机的并行部署能力。 在正式部署前,系统会自动对基础网络环境进行校验,看看上级交换机的配置是否合理等。 然后,识别外部因素,自动选择配置模板。 配置完成后,为了保证交付质量,运营平台还会进行自动化验收,包括一系列的性能和可靠性测试。  所有工作完成后,系统才会进入交付状态。 根据数据统计,基于端网一体部署能力,大模型训练系统的整体部署时间从19天缩减到4.5天,并保证了基础配置100%准确。 再看看运维阶段的“一键故障定位”。 星脉网络具有端网高度协同的特点,增加了端侧的运营能力。运营平台通过数据采集模块,获取端侧服务器和网络侧交换机的数据,联动网管拓扑信息,可以做到快速诊断与自动化检查。 一键故障定位,可以快速定界问题方向,精准推送到对应团队的运营人员(网络or业务),减少沟通成本,划分责任界限。而且,它还有利于快速定位问题根因,并给出解决方案。 最后,是“业务无感秒级网络自愈”。 在网络运行的过程中,故障是无法避免的。 为了将故障自愈时间缩短到极致,腾讯推出了秒级故障自愈产品——“HASH DODGING”。 这是一种基于Hash偏移算法的网络相对路径控制方法。即,终端仅需修改数据包头特定字段(如IP头TOS字段)的值,即可使得修改后的包传输路径与修改前路径无公共节点。 在网络数据平面发生故障(如静默丢包、路由黑洞)时,该方案可以帮助TCP快速绕过故障点,不会产生对标准拓扑及特定源端口号的依赖。
所有工作完成后,系统才会进入交付状态。 根据数据统计,基于端网一体部署能力,大模型训练系统的整体部署时间从19天缩减到4.5天,并保证了基础配置100%准确。 再看看运维阶段的“一键故障定位”。 星脉网络具有端网高度协同的特点,增加了端侧的运营能力。运营平台通过数据采集模块,获取端侧服务器和网络侧交换机的数据,联动网管拓扑信息,可以做到快速诊断与自动化检查。 一键故障定位,可以快速定界问题方向,精准推送到对应团队的运营人员(网络or业务),减少沟通成本,划分责任界限。而且,它还有利于快速定位问题根因,并给出解决方案。 最后,是“业务无感秒级网络自愈”。 在网络运行的过程中,故障是无法避免的。 为了将故障自愈时间缩短到极致,腾讯推出了秒级故障自愈产品——“HASH DODGING”。 这是一种基于Hash偏移算法的网络相对路径控制方法。即,终端仅需修改数据包头特定字段(如IP头TOS字段)的值,即可使得修改后的包传输路径与修改前路径无公共节点。 在网络数据平面发生故障(如静默丢包、路由黑洞)时,该方案可以帮助TCP快速绕过故障点,不会产生对标准拓扑及特定源端口号的依赖。 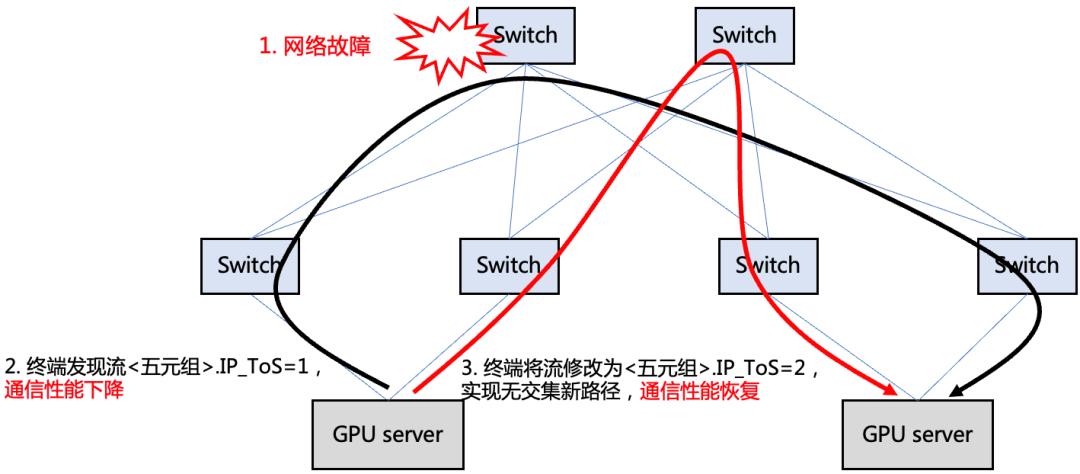 单路径传输协议下,使用本方案,实现确定性换路 █ 结语 以上,就是对腾讯星脉高性能计算网络的关键技术分析。 这些关键技术,揭示了高性能网络的发展思路和演进方向。随着AI大模型的深入发展,人类对AI算力的需求会不断增加。 日前,腾讯云发布的新一代HCC高性能计算集群,正是基于星脉高性能网络打造,算力性能较前代提升3倍,为AI大模型训练构筑可靠的高性能网络底座。 未来已来,这场围绕算力和连接力的角逐已经开始。更多的精彩还在后面,让我们拭目以待吧!
单路径传输协议下,使用本方案,实现确定性换路 █ 结语 以上,就是对腾讯星脉高性能计算网络的关键技术分析。 这些关键技术,揭示了高性能网络的发展思路和演进方向。随着AI大模型的深入发展,人类对AI算力的需求会不断增加。 日前,腾讯云发布的新一代HCC高性能计算集群,正是基于星脉高性能网络打造,算力性能较前代提升3倍,为AI大模型训练构筑可靠的高性能网络底座。 未来已来,这场围绕算力和连接力的角逐已经开始。更多的精彩还在后面,让我们拭目以待吧!
-
网络
+关注
关注
14文章
8400浏览量
95801 -
AI
+关注
关注
91文章
42482浏览量
303421 -
TCP
+关注
关注
8文章
1441浏览量
83980
原文标题:死磕AI大模型网络,鹅厂出招了!
文章出处:【微信号:鲜枣课堂,微信公众号:鲜枣课堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
用TINA如何搭建仿真模型?


Firefly支持AI引擎Tengine,性能提升,轻松搭建AI计算框架
【AI学习】第3篇--人工神经网络
轻量化神经网络的相关资料下载
介绍在STM32cubeIDE上部署AI模型的系列教程
simulink搭建的摩擦模型

卷积神经网络模型搭建
虹科分享 | 谷歌Vertex AI平台使用Redis搭建大语言模型



评论