 常见的语义分割模型
常见的语义分割模型

计算机视觉(Computer Vision)是指让机器通过数字图像或视频等视觉信息来模拟人类视觉的过程,以达到对物体的理解、识别、分类、跟踪、重建等目的的技术。它是人工智能领域中的一个分支,涉及图像处理、模式识别、机器学习、深度学习等多个领域。
计算机视觉的应用非常广泛,例如人脸识别、自动驾驶、无人机、医学影像分析、工业生产等等。本文将对计算机视觉应用中最为广泛的六大技术进行介绍。
一、图像分类
1、定义
图像分类,根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。
2、分类方法及卷烟车间应用
2.1基于色彩特征的索引技术
常见的检测模型包括基于直方图的检测方法和基于机器学习的检测方法。基于直方图的检测方法是最简单和常见的方法,它仅仅对颜色直方图进行比较。基于机器学习的检测方法则需要训练一个分类器,以区分不同类别的图像。常见的分类器包括支持向量机(SVM)和随机森林(Random Forest)等。
实际业务中,可以用来检测和分类卷烟制造过程中的图像。例如,可以使用颜色直方图来检测卷烟生产线上的烟叶颜色分布情况,以及使用颜色矩来分析卷烟的色调和亮度等特征。这些方法可以帮助卷烟厂监控生产过程,提高生产效率和质量。
2.2基于纹理的图像分类技术
通常使用纹理特征描述图像的纹理信息。常见的纹理特征包括灰度共生矩阵(GLCM)、局部二值模式(LBP)和高斯方向梯度直方图(HOG)等。这些纹理特征可以提取图像中的纹理信息,包括纹理的颗粒度、方向、周期性等,从而用于图像分类和识别。
常规的解决方案包括以下几个步骤:
1)特征提取:使用纹理特征描述图像的纹理信息。灰度共生矩阵(GLCM)是一种描述灰度纹理特征的方法,它利用灰度级之间的空间关系来描述纹理信息。局部二值模式(LBP)则是一种描述局部纹理特征的方法,它利用像素点周围的二进制编码来描述纹理信息。高斯方向梯度直方图(HOG)则是一种描述方向纹理特征的方法,它利用图像梯度方向和梯度强度来描述纹理信息。
2)特征选择:对提取的纹理特征进行筛选和选择,以减少特征维度和提高分类性能。常见的特征选择方法包括主成分分析(PCA)和线性判别分析(LDA)等。
3)分类模型:选择一种分类器或分类模型,用于将提取的纹理特征与图像类别进行映射。常见的分类器包括支持向量机(SVM)、K近邻算法、决策树等。
该技术可以用于检测和分类卷烟的表面纹理信息。例如,可以使用灰度共生矩阵(GLCM)来分析卷烟的表面纹理特征,如颗粒度、方向性等。这些方法可以帮助卷烟厂监控卷烟表面质量,提高产品质量和生产效率。
2.3基于形状的图像分类技术
基于形状的图像分类技术通常使用图像形状特征描述图像中的形状信息,常用的形状特征包括边缘特征、轮廓特征和区域特征等。基于形状的图像分类技术可以应用于许多应用领域,如医学图像、工业检测和安防监控等。
常规的解决方案包括以下几个步骤:
1)特征提取:使用形状特征描述图像中的形状信息。常用的形状特征包括边缘特征、轮廓特征和区域特征等。其中,边缘特征通常是指提取图像中的边缘信息,如Canny边缘检测算法。轮廓特征则是指提取图像中的轮廓信息,如Hu不变矩特征。区域特征则是指提取图像中的区域信息,如Zernike矩和小波矩等。
2)特征选择:对提取的形状特征进行筛选和选择,以减少特征维度和提高分类性能。常见的特征选择方法包括主成分分析(PCA)和线性判别分析(LDA)等。
3)分类模型:选择一种分类器或分类模型,用于将提取的形状特征与图像类别进行映射。常见的分类器包括支持向量机(SVM)、K近邻算法、决策树等。
在卷烟厂相关的应用中,可以用于检测和分类卷烟的形状信息,如卷烟的长度、粗细和形态等。例如,可以使用轮廓特征和区域特征来描述卷烟的形状信息,然后使用分类器对不同形状的卷烟进行分类。这些方法可以帮助卷烟厂监控卷烟形状质量,提高产品质量和生产效率。
2.4基于空间关系的图像分类技术
利用图像中不同区域之间的空间关系,来描述和分类图像的一种方法。这种方法通常用于场景分类、物体识别和图像标注等领域。
常规的解决方案包括以下几个步骤:
1)特征提取:提取图像中的区域特征,通常包括颜色、纹理、形状等特征。
2)空间关系建模:根据提取的特征,对不同区域之间的空间关系进行建模,例如使用关系图模型或基于视觉单词的方法。
3)分类模型:选择一种分类器或分类模型,用于将提取的特征与图像类别进行映射。常见的分类器包括支持向量机(SVM)、卷积神经网络(CNN)等。
在实际应用中可以检测和分类卷烟生产过程中的不同区域和组件,例如卷烟的过滤嘴、烟膜和滤棒等。常用的解决方案是基于视觉单词的方法,即将图像中的每个区域表示为一组视觉单词,并通过计算视觉单词之间的空间关系来描述区域之间的空间关系。然后,可以使用分类器对不同区域进行分类,以实现卷烟生产过程中的自动化检测和分类。
二、目标检测
目标检测是指在图像或视频中,识别出目标物体所在的位置,并标注出其所属的类别的任务。相比于图像分类任务,目标检测需要对目标的位置和数量进行准确的识别,因此其难度更大,但也更加实用。目标检测通常应用于智能安防、自动驾驶、无人机等领域,能够对目标进行追踪、识别和分析,有助于提高智能决策和系统自主性。
常见的目标检测模型包括:
1)Faster R-CNN:是一种基于深度神经网络的目标检测模型,它通过在区域提议网络(Region Proposal Network, RPN)中引入锚点来提高检测速度,同时采用了RoI Pooling层来实现不同大小的目标检测。
2)YOLO(You Only Look Once):是一种基于单阶段目标检测算法的模型,它将目标检测任务转化为一个回归问题,通过卷积神经网络预测目标的类别和位置。
3)SSD(Single Shot MultiBox Detector):也是一种基于单阶段目标检测算法的模型,通过在每个特征层上应用不同大小和形状的先验框,从而实现对不同尺度目标的检测。
目标检测的适用场景包括但不限于:
1)智能安防:监控场景中的人员和车辆,实现目标追踪和识别。
自动驾驶:通过识别道路标志、交通信号灯、行人和其他车辆等来实现自主驾驶。
2)无人机:对无人机飞行区域中的目标进行识别和跟踪,以实现智能控制和导航。
3)工业制造:在生产过程中对产品进行检测和分类,提高生产效率和质量。
4)医疗诊断:通过对医学图像中的肿瘤等异常进行识别和定位,辅助医生进行诊断和治疗。
目标检测的性能指标主要包括准确率、召回率、F1得分等,常用的评价方法有mAP(mean Average Precision)和IoU(Intersection over Union)等。在实际应用中,可以根据具体场景和需求,选择不同的模型和算法来实现目标检测任务。
三、目标跟踪
目标跟踪是指在视频序列中,对于已知的初始目标,在后续帧中通过对目标的特征提取和跟踪算法进行处理,实现对目标位置、形态等信息的实时跟踪。目标跟踪技术适用于视频监控、无人驾驶、智能交通等领域,可以用于目标的实时跟踪和识别,实现自动化控制和智能化分析。
常用的目标跟踪算法包括以下几种:
1)基于相关滤波的跟踪方法
这种方法是将目标与模板进行相关性计算,计算得到的结果可以表示目标在当前帧的位置。常用的相关滤波算法包括均值归一化相关滤波(Mean Normalized Correlation,MNC)、峰值信号比相关滤波(Peak-to-Correlation Energy Ratio,PCER)等。
2)基于粒子滤波的跟踪方法
这种方法通过在目标周围随机生成多个粒子,然后根据目标的运动模型,对这些粒子进行预测,再用观测信息对预测的粒子进行权重更新,最终选择权重最高的粒子来表示目标的位置。常用的粒子滤波算法包括卡尔曼滤波(Kalman Filter,KF)、粒子滤波(Particle Filter,PF)等。
3)基于深度学习的跟踪方法
这种方法使用深度学习算法对目标进行特征提取和表示,然后根据目标在前一帧的位置和特征,对目标在当前帧的位置进行预测。常用的深度学习跟踪算法包括循环神经网络(Recurrent Neural Network,RNN)、卷积神经网络(Convolutional Neural Network,CNN)等。
目标跟踪技术适用于视频监控、无人驾驶、智能交通等领域,可以用于目标的实时跟踪和识别,实现自动化控制和智能化分析。
四、语义分割
旨在将输入图像中的每个像素标记为属于哪个语义类别。与目标检测和图像分类不同,语义分割不仅可以识别图像中的物体,还可以为每个像素分配标签,从而提供更详细和准确的图像理解。
语义分割适用于需要对图像进行精细分割和像素级分类的场景,例如自动驾驶中的道路分割、医学图像中的病变分割、地理信息系统中的土地分类等。
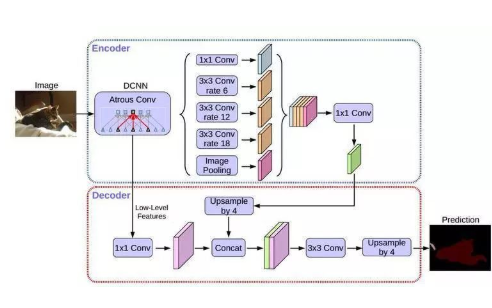
常见的语义分割模型包括FCN(Fully Convolutional Network)、U-Net、DeepLab等。其中FCN模型是最早被提出并被广泛使用的语义分割模型之一,它将全连接层转换为卷积层,从而实现端到端的像素级分类。U-Net模型通过引入对称的上采样和下采样路径,能够更好地处理分辨率较低的输入图像。DeepLab模型则通过空洞卷积(Dilated Convolution)和空间金字塔池化(Spatial Pyramid Pooling)等技术,提高了图像语义分割的精度。
除了这些常用模型外,近年来还涌现出了许多基于深度学习的新型语义分割模型,如PSPNet、DeepLab V3+等,它们在精度和效率等方面都有所提高。
五、实例分割
实例分割是结合目标检测和语义分割的一个更高层级的任务。
实例分割是计算机视觉中的一项任务,旨在同时检测图像中的物体,并将每个物体分割成精确的像素级别的区域。与语义分割不同,实例分割不仅可以分割出不同类别的物体,还可以将它们分割成独立的、像素级别的区域。
实例分割适用于需要对图像进行精细分割并区分不同物体的场景,例如自动驾驶中的行人和车辆分割、医学图像中的器官分割、遥感图像中的建筑物分割等。
常见的实例分割模型包括Mask R-CNN、FCIS(Fully Convolutional Instance-aware Semantic Segmentation)等。其中,Mask R-CNN是一种基于 Faster R-CNN 框架的实例分割模型,通过添加分割头网络在目标检测框架中增加了实例分割的功能,从而实现了同时检测和分割的目标。FCIS模型则是一种全卷积实例分割模型,它使用了RoI pooling和RoI reshape等技术,可以在不增加计算量的情况下同时实现目标检测和实例分割。
除了这些常用模型外,近年来还涌现出了许多基于深度学习的新型实例分割模型,如SOLO(Segmenting Objects by Locations)等,它们在精度和效率等方面都有所提高。
六、影像重建
影像重建是指通过对原始图像进行处理和重构,生成高质量的图像或视频。其应用场景包括医学影像学、遥感图像、安全监控等领域。
在医学影像学中,影像重建技术可以应用于CT、MRI等医学影像的重建,帮助医生更精准地诊断和治疗病情。在遥感图像领域,影像重建技术可以帮助提高遥感图像的分辨率和质量,为资源管理、环境监测等提供支持。在安全监控领域,影像重建技术可以帮助提高监控图像的清晰度和识别度,增强安全监控的效果。
影像重建技术主要包括基于插值的方法、基于统计建模的方法和基于深度学习的方法。其中,基于插值的方法是最简单的方法之一,它通过对原始图像进行插值操作来增加图像的分辨率。基于统计建模的方法则通过对样本进行统计建模来重建图像,如主成分分析(PCA)、独立成分分析(ICA)等。基于深度学习的方法则是当前最先进的影像重建方法之一,如卷积神经网络(CNN)和生成对抗网络(GAN)。这些模型通过学习大量数据来重构图像,并且在不同的任务中取得了很好的效果。
计算机视觉是当前最热门的研究之一,是一门多学科交叉的研究,随着对计算机视觉研究的深入,很多科学家相信将为人工智能行业的发展奠定基础。
-
模型
+关注
关注
1文章
3816浏览量
52265 -
计算机视觉
+关注
关注
9文章
1715浏览量
47713 -
机器学习
+关注
关注
67文章
8562浏览量
137209
原文标题:计算机视觉六大主要技术介绍
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?
DeepLab进行语义分割的研究分析
语义分割算法系统介绍
分析总结基于深度神经网络的图像语义分割方法

结合双目图像的深度信息跨层次特征的语义分割模型

基于深度神经网络的图像语义分割方法

基于SEGNET模型的图像语义分割方法
语义分割数据集:从理论到实践
语义分割标注:从认知到实践
模型在学习可转移的语义分割表示方面的有效性
PyTorch教程-14.9. 语义分割和数据集

深度学习图像语义分割指标介绍




评论