 LLM在各种情感分析任务中的表现如何
LLM在各种情感分析任务中的表现如何

最近几年,GPT-3、PaLM和GPT-4等LLM刷爆了各种NLP任务,特别是在zero-shot和few-shot方面表现出它们强大的性能。因此,情感分析(SA)领域也必然少不了LLM的影子,但是哪种LLM适用于SA任务依然是不清晰的。

论文:Sentiment Analysis in the Era of Large Language Models: A Reality Check
地址:https://arxiv.org/pdf/2305.15005.pdf
代码:https://github.com/DAMO-NLP-SG/LLM-Sentiment
这篇工作调查了LLM时代情感分析的研究现状,旨在帮助SA研究者们解决以下困惑:
LLM在各种情感分析任务中的表现如何?
与在特定数据集上训练的小模型(SLM)相比,LLM在zero-shot和few-shot方面的表现如何?
在LLM时代,当前的SA评估实践是否仍然适用?
实验
实验设置
1、调查任务和数据集
该工作对多种的SA任务进行了广泛调查,包括以下三种类型任务:情感分类(SC)、基于方面的情感分析(ABSA)和主观文本的多面分析(MAST)。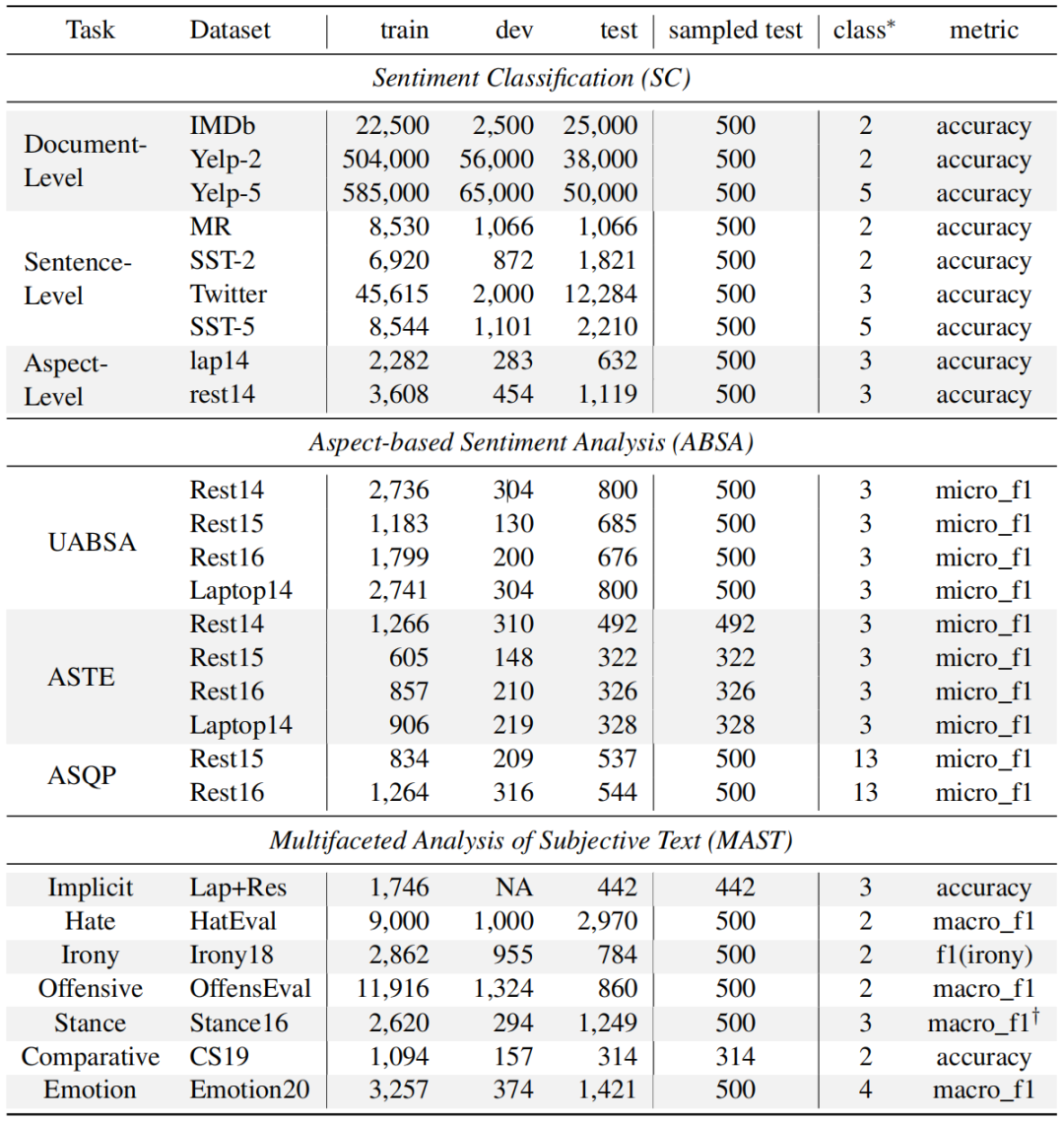
2、基线模型
Large Language Models (LLMs) LLM将直接用于SA任务的推理而没有特定的训练,本文从Flan模型家族中选取了两个模型,分别是Flan-T5(XXL版本,13B)和Flan-UL2(20B)。同时,采用了GPT-3.5家族两个模型,包括ChatGPT(gpt-3.5-turbo)和text-davinci-003(text-003,175B)。为了正确性预测,这些模型的温度设置为0。
Small Language Models (SLMs) 本文采用T5(large版本,770M)作为SLM。模型训练包括全训练集的方式和采样部分数据的few-shot方式,前者训练epoch为3而后者为100。采用Adam优化器并设置学习率为1e-4,所有任务的batch大小设置为4。为了稳定对比,为SLM构造3轮不同随机seed的训练,并采用其平均值作为结果。
3、Prompting策略
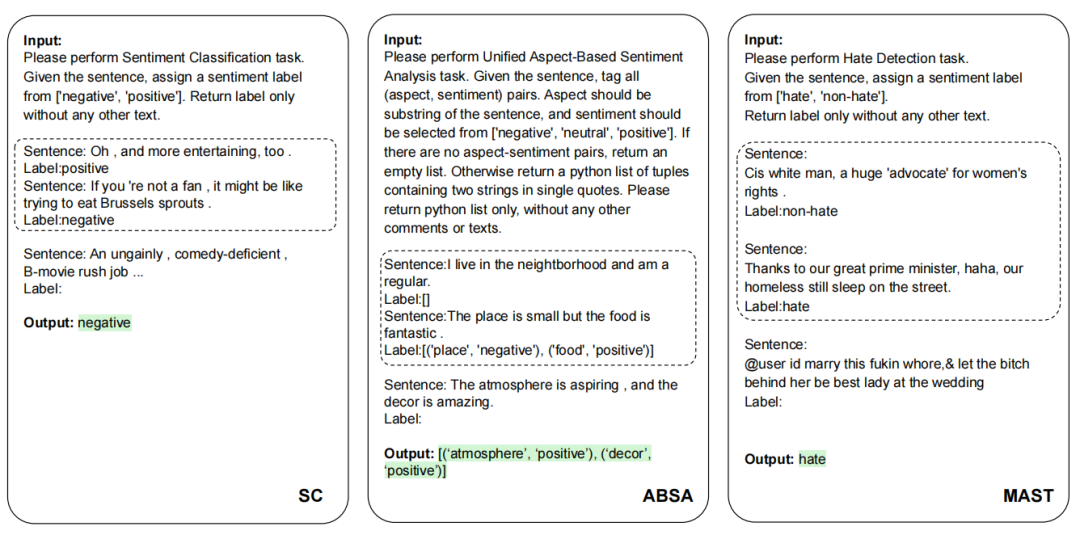 SC,ABSA,和MAST的提示实例。虚线框为few-shot设置,在zero-shot设置时删除。
SC,ABSA,和MAST的提示实例。虚线框为few-shot设置,在zero-shot设置时删除。
为了评估LLM的通用能力,本文为不同模型采用相对一致的的propmts,这些propmts满足简单清晰直接的特性。对于zero-shot学习,propmt只包含任务名、任务定义和输出格式三个必要组件,而对于few-shot学习,将为每个类增加k个实例。
实验结果
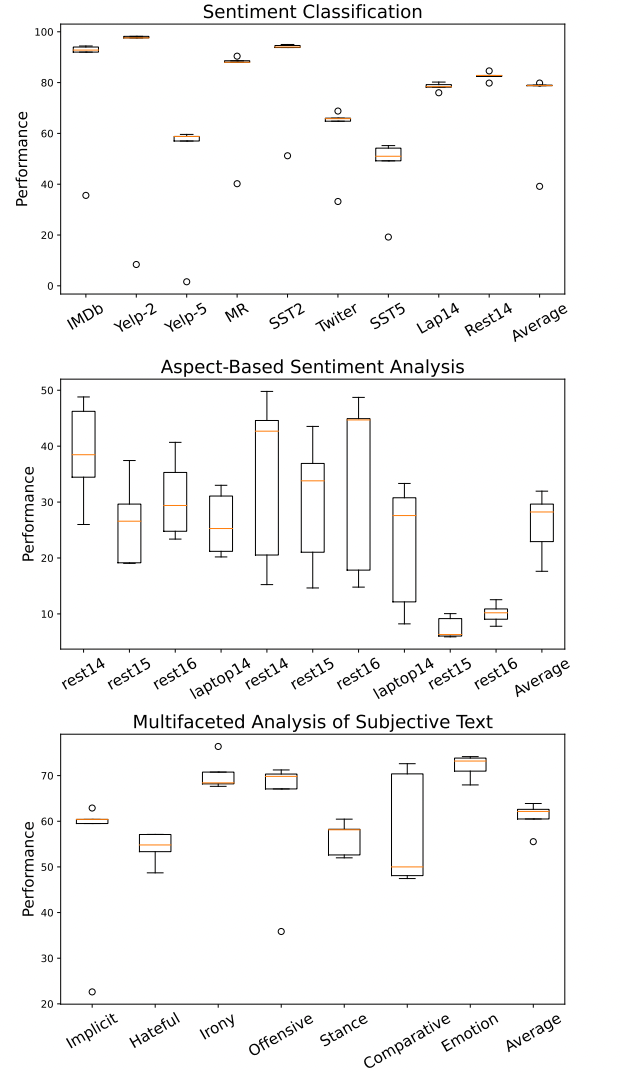
1、Zero-shot结果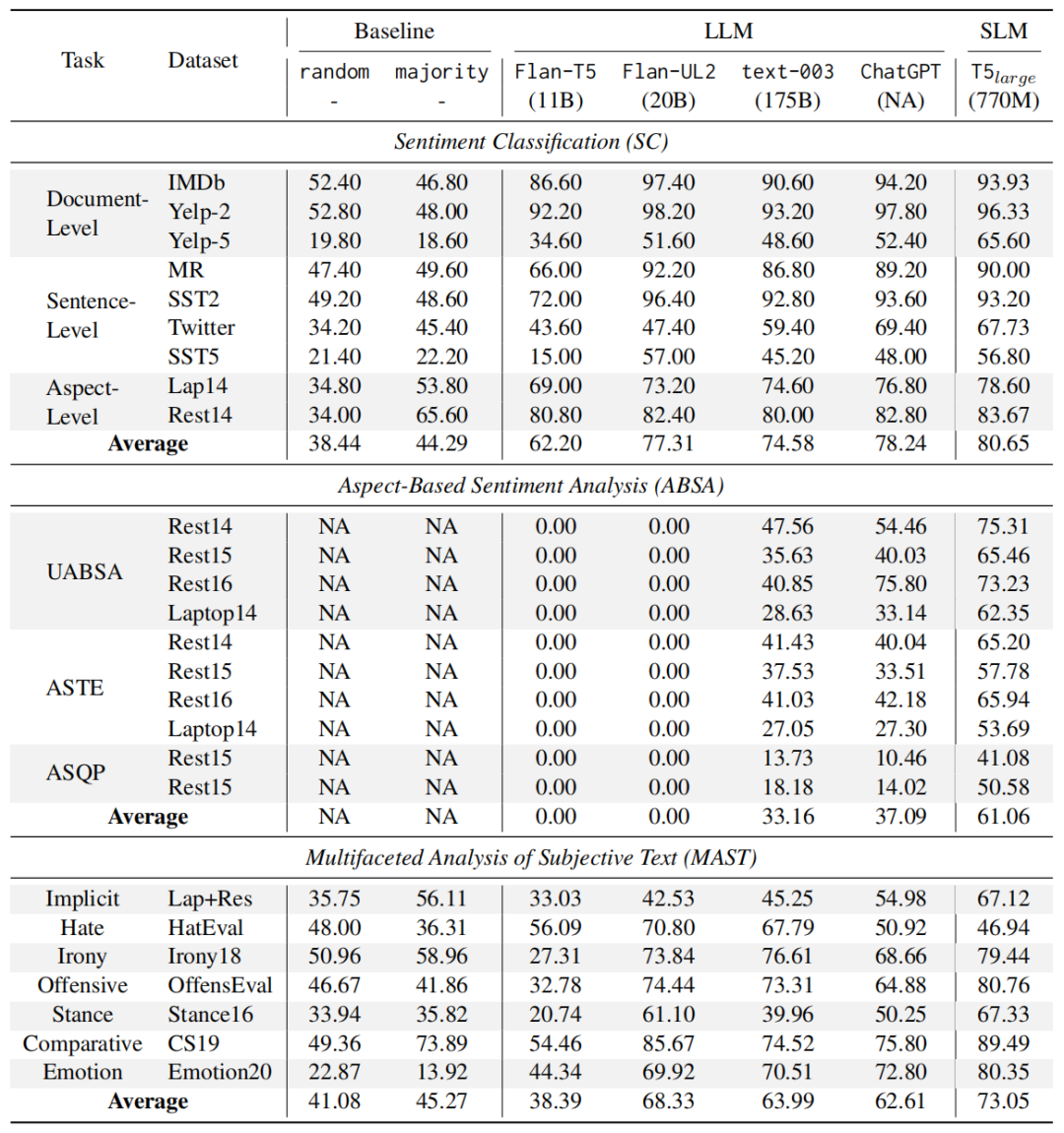 对于LLM,直接将其用于测试集上进行结果推理。对于SLM,先将其在完整训练集上fine-tuned然后再用于测试,从上图结果中可以观测到:
对于LLM,直接将其用于测试集上进行结果推理。对于SLM,先将其在完整训练集上fine-tuned然后再用于测试,从上图结果中可以观测到:
LLM在简单SA任务上表现出强大的zero-shot性能 从表中结果可以看到LLM的强大性能在SC和MAST任务上,而不需要任何的前置训练。同时也能观察到任务稍微困难一点,比如Yelp-5(类目增多)和,LLM就比fine-tuned模型落后很多。
更大的模型不一定导致更好的性能 从表中结果可以看到LLM对于SC和MAST任务表现较好,而且不需要任何的前置训练。但是也能观察到任务稍微困难一点,比如Yelp-5(类目增多),LLM就比fine-tuned模型落后很多。
LLM难以提取细粒度的结构化情感和观点信息 从表中中间部分可以看出,Flan-T5和Flan-UL2在ABSA任务根本就不适用,而text-003和ChatGPT虽然取得了更好的结果,但是对于fine-tuned的SLM来说,依然是非常弱的。
RLHF可能导致意外现象 从表中可以观察到一个有趣现象,ChatGPT在检测仇恨、讽刺和攻击性语言方面表现不佳。即使与在许多其他任务上表现相似的text-003相比,ChatGPT在这三项任务上的表现仍然差得多。对此一个可能的解释是在ChatGPT的RLHF过程与人的偏好“过度一致”。这一发现强调了在这些领域进一步研究和改进的必要性。
2、Few-shot结果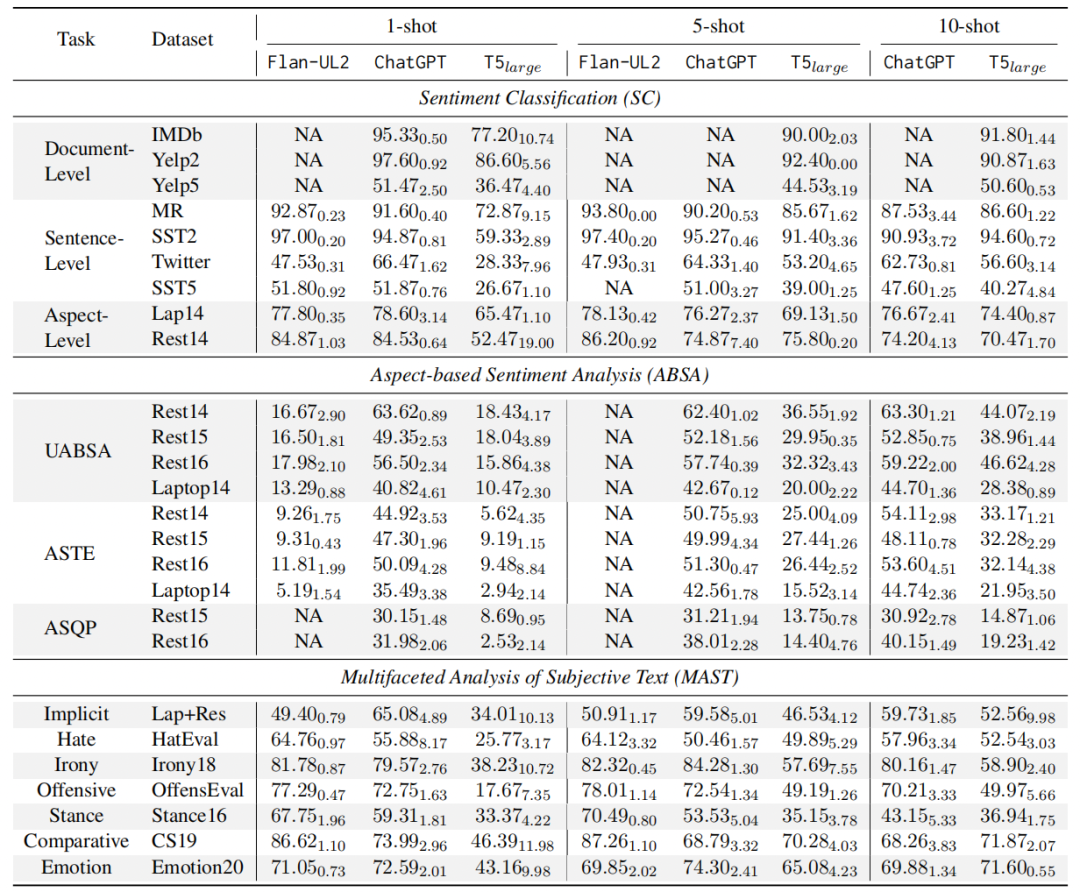 本文采用了手中K-shot的设置:1-shot, 5-shot, 和10-shot。这些采样的实例分别作为LLM上下文学习实例以及SLM的训练数据。可以有如下发现:
本文采用了手中K-shot的设置:1-shot, 5-shot, 和10-shot。这些采样的实例分别作为LLM上下文学习实例以及SLM的训练数据。可以有如下发现:
在不同的few-shot设置下,LLM超越SLM 在三种few-shot设置中,LLM几乎在所有情况下都始终优于SLM。这一优势在ABSA任务中尤为明显,因为ABSA任务需要输出结构化的情感信息,SLM明显落后于LLM,这可能是由于在数据有限的情况下学习这种模式会变得更加困难。
SLM通过增加shot在多数任务性能得到持续提升 随着shot数目的增加,SLM在各种SA任务中表现出实质性的提升。这表明SLM能有效利用更多的示例实现更好的性能。任务复杂性也可以从图中观察到,T5模型用于情感分类任务性能逐渐趋于平稳,然而对于ABSA和MAST任务,性能继续增长,这表明需要更多的数据来捕捉其基本模式。
LLM shots的增加对不同任务产生不同结果 增加shot数目对LLM的影响因任务而异。对于像SC这种相对简单的任务,增加shot收益并不明显。此外,如MR和Twitter等数据集以及立场和比较任务,甚至随着shot的增加,性能受到阻碍,这可能是由于处理过长的上下文误导LLM的结果。然而,对于需要更深入、更精确的输出格式的ABSA任务,增加few数目大大提高了LLM的性能。这表明更多示例并不是所有任务的灵丹妙药,需要依赖任务的复杂性。
SA能力评估再思考
呼吁更全面的评估 目前大多数评估往往只关注特定的SA任务或数据集,虽然这些评估可以为LLM的情感分析能力的某些方面提供有用见解,但它们本身并没有捕捉到模型能力的全部广度和深度。这种限制不仅降低了评估结果的总体可靠性,而且限制了模型对不同SA场景的适应性。因此,本文试图在这项工作中对广泛的SA任务进行全面评估,并呼吁在未来对更广泛的SA工作进行更全面的评估。
呼吁更自然的模型交互方式 常规情感分析任务通常为一个句子配对相应的情感标签。这种格式有助于学习文本与其情感之间的映射关系,但可能不适合LLM,因为LLM通常是生成模型。在实践中不同的写作风格产生LLM解决SA任务的不同方式,所以在评估过程中考虑不同的表达以反映更现实的用例是至关重要的。这确保评估结果反映真实世界的互动,进而提供更可靠的见解。
prompt设计的敏感性 如图所示,即使在一些简单的SC任务上,prompt的变化也会对ChatGPT的性能产生实质性影响。当试图公平、稳定地测试LLM的SA能力时,与prompt相关的敏感性也带来了挑战。当各种研究在一系列LLM中对不同的SA任务使用不同的prompt时,挑战被进一步放大。与prompt相关的固有偏见使采用相同prompt的不同模型的公平对比变得复杂,因为单个prompt可能并不适用于所有模型。
为了缓解上述评估LLM的SA能力时的局限性,本文提出了SENTIEVAL基准,用于在LLM时代进行更好的SA评估,并利用各种LLM模型进行了再评估,结果如图所示。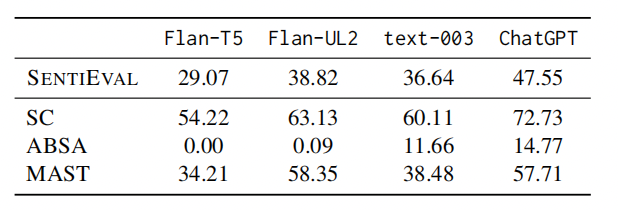
总结
这项工作使用LLM对各种SA任务进行了系统评估,有助于更好地了解它们在SA问题中的能力。结果表明,虽然LLM在zero-shot下的简单任务中表现很好,但它们在处理更复杂的任务时会遇到困难。在few-shot下,LLM始终优于SLM,这表明它们在标注资源稀缺时的潜力。同时还强调了当前评估实践的局限性,然后引入了SENTIEVAL基准作为一种更全面、更现实的评估工具。
总体而言,大型语言模型为情感分析开辟了新的途径。虽然一些常规SA任务已经达到了接近人类的表现,但要全面理解人类的情感、观点和其他主观感受还有很长的路要走。LLM强大的文本理解能力为LLM时代情感分析探索之路提供了有效的工具和令人兴奋的研究方向。
-
模型
+关注
关注
1文章
3879浏览量
52355 -
数据集
+关注
关注
4文章
1242浏览量
26308 -
ChatGPT
+关注
关注
31文章
1609浏览量
10441 -
LLM
+关注
关注
1文章
352浏览量
1415
原文标题:ChatGPT时代情感分析还存在吗?一份真实调查
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
简单介绍ACL 2020中有关对象级情感分析的三篇文章

金融市场中的NLP 情感分析
将对话中的情感分类任务建模为序列标注 并对情感一致性进行建模
绍华为云在细粒度情感分析方面的实践
情感分析常用的知识有哪些呢?
图模型在方面级情感分析任务中的应用
Macaw-LLM:具有图像、音频、视频和文本集成的多模态语言建模
适用于各种NLP任务的开源LLM的finetune教程~

基于单一LLM的情感分析方法的局限性




评论