 AI算法画小姐姐,AMD显卡比顶级CPU快30倍!
AI算法画小姐姐,AMD显卡比顶级CPU快30倍!

从Stable Diffusion这一AI应用出现之后,在极短时间内就迅速走红,成为众多玩家口口相传的“最美小姐姐”生成工具。不过这一AI计算画图工具在Stable Diffusion官方推出之初,无论是WEB UI的部署还是模型的训练生成,都基本是基于NVIDIA CUDA加速的算法,因此A卡最初并不被Stable Diffusion官方支持。不过好在Stable Diffusion算是一个开源的产品,在众多社区聚集玩家的支持下,也出现了许多支持A卡GPU加速计算的分支,比如我们今天要测试的基于DirectML的部署,就能实现AMD Radeon显卡的Stable Diffusion AI计算硬件加速。
如果要自己在本地部署基于DirectML的Stable Diffusion话,相比便捷的基于CUDA的WEB UI部署要相对复杂一些,不过现在网上已经有比较成熟的整合包供玩家适用,玩家们只需要下载相应的整合包,就能一键实现在本地的傻瓜式安装部署,可以为大家节省相当多的时间。
▲我们选择用于测试的这个整合包安装完毕之后,自动进入AMD GPU加速计算模式,在本地开启http://127.0.0.1:7860即可打开本地Stable Diffusion的AI画图界面。
▲在本地WEB UI界面上可以自由设置相关的AI艺术图生成参数,点击“生成”即可开始画图。具体请参考线上相关教程,在此我们不赘述。
那么,基于DirectML的Stable Diffusion部署分支能不能实现对AMD显卡的硬件计算加速支持呢?它的效率到底如何?在此前A卡玩家经常只能在Linux系统下运行Stable Diffusion,通过ROCM(Radeon Open Compute)模拟CUDA加速,如今在Windows系统下直接实现A卡的AI加速计算,能否达到我们的预期目标呢?为此,我们选择了AMD Radeon RX 5000系、RX 6000系以及RX 7000系的数款显卡,进行了一番详细的体验。
体验平台
显卡:AMD Radeon RX 5500XT(8GB)、RX 5700(8GB)、RX 6500XT 4GB、RX 6600(8GB)、RX 6700XT(12GB)、RX 6750XT(12GB)、RX 6800(16GB)、RX 6900XT(16GB)、RX 7900 XT(20GB)、RX 7900 XTX(24GB)
主板:英特尔Z790
内存:DDR5 6000 16GB×2
SSD:AORUS NVMe PCIe SSD 2TB
操作系统:Windows 11 Pro 22H2
驱动程序:AMD Software Adrenalin Edition 23.4.3
通过测试,我们想知道:
AMD Radeon 5000系、6000系和7000系之间,在Stable Diffusion的AI画图算力上有多大差别?
相比传统的CPU AI计算加速,AMD GPU加速性能到底如何?
▲我们所采用的网络开源共享的部署方案可以正确实现AMD显卡的硬件加速计算,可以看到在图片生成的过程中GPU的占用率一直保持在100%。
模型为Novel AI Final-runed(CKPT)
测试一:AI生成时尚美女
在第一部分的测试中,我们通过关键词生成一个大眼的时尚美女小姐姐,还要有一定的照片感。关键词设置如下(部分引用自网络开源共享关键词):
lora0.6> , best quality, ultra high res, (photorealistic:1.4), 1woman, sleeveless white button shirt, black skirt, black choker, cute, (Kpop idol), (aegyo sal:1), (platinum blonde hair:1), ((puffy eyes)), looking at viewer, full body, facing front,fashion,premium
分辨率设置:512×512
采样步进:20
提示词引导系数:7
生成批次-每批数量:1-1、4-1

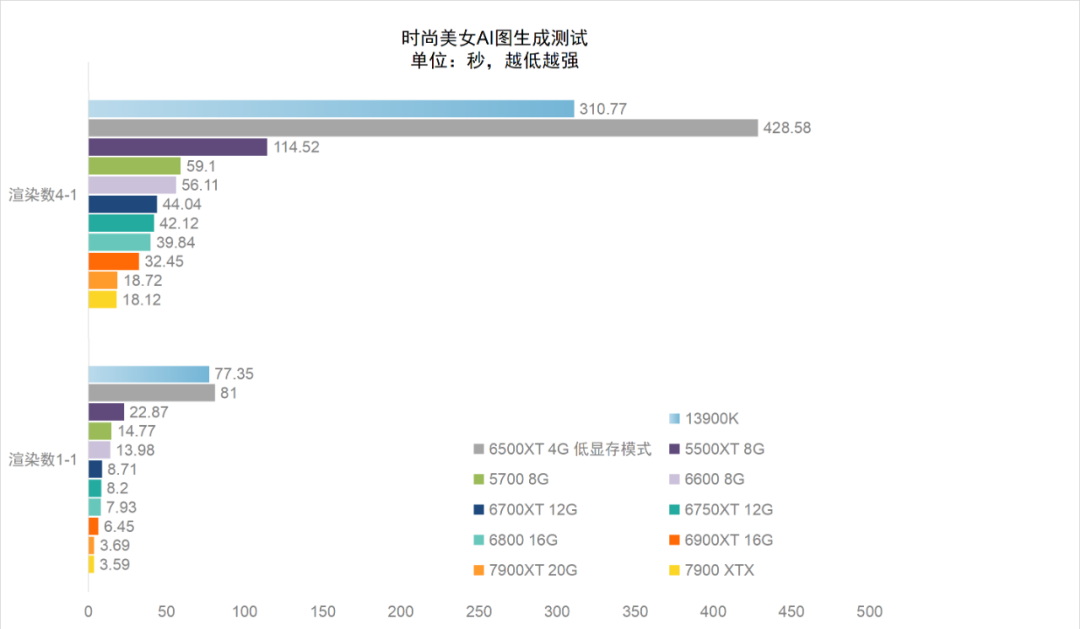
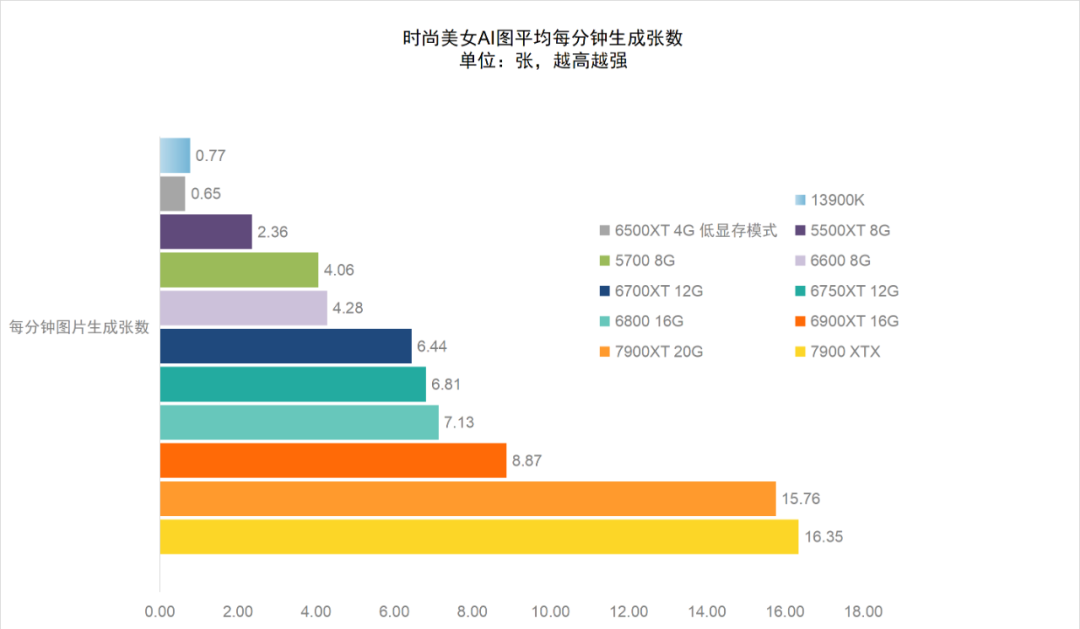
在测试中由于绝大部分显卡都拥有8GB以上的显存,因此我们在运行参数上基本设置了正常的高显存默认模式,只有4GB显存版的RX 6500XT运行时采用了添加了--lowvram的低显存运行模式(否则就无法运行)。从整体测试结果来看,AMD从Radeon RX 5000系到RX 7000系的显卡几乎都很好地实现了Stable Diffusion应用的AI计算加速性能,尤其是Radeon RX 7000系显卡性能相比RX 6000系显卡有了巨大的提升。比如RX 6900XT在该设置与模型算法下的图片生成率约为8.87张/秒,而RX 7900 XT则可以达到15.76张/秒,性能提升接近100%。
而相比CPU来说,全系AMD显卡都占有非常明显的优势,RX 7900 XT的性能达到了酷睿i9-13900K的30倍左右,即使前两代的入门级显卡RX 5500XT,性能上也几乎接近酷睿i9-13900K的5倍。
唯一有点异常的是RX 6500XT,按照核心规格来看,它应该是要强于RX 5500XT的,不过由于显存配置仅为4GB,因此在测试中开启了低显存运行模式之后,其图片上生成速度受到了极大影响,远低于GPU加速的正常表现,仅能达到略高于CPU计算的水准。
测试二:AI生成较为复杂的水边别墅风景照
在接下来的测试中,我们用一系列相对复杂的关键词来生成一座位于水边的别墅,同时还伴有阳光、波纹、倒影等效果要求。关键词如下:
‘beautiful render of a Tudor style house near the water at sunset, fantasy forest. photorealistic, cinematic composition, cinematic high detail, ultra realistic, cinematic lighting, Depth of Field, hyper-detailed, beautifully color-coded, 8k,’
分辨率设置:512×512
采样步进:50
提示词引导系数:7.5
生成批次-每批数量:1-1、2-1、4-1

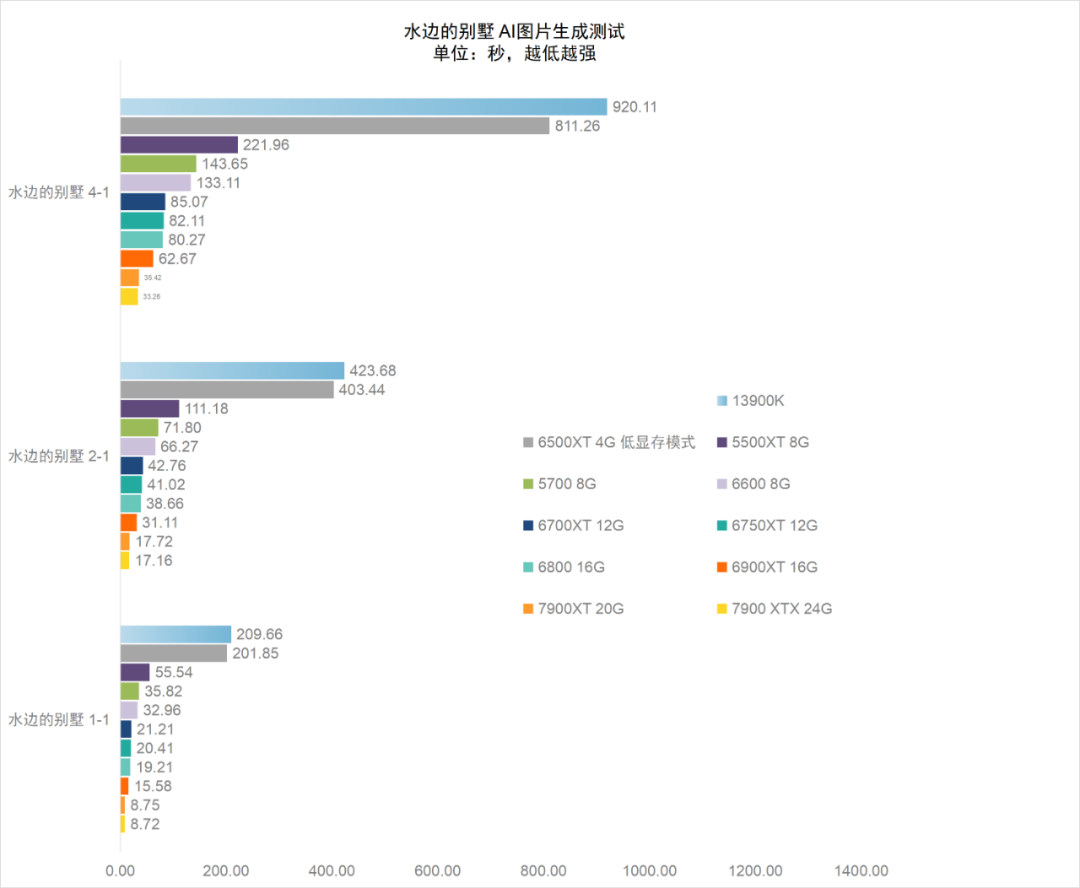
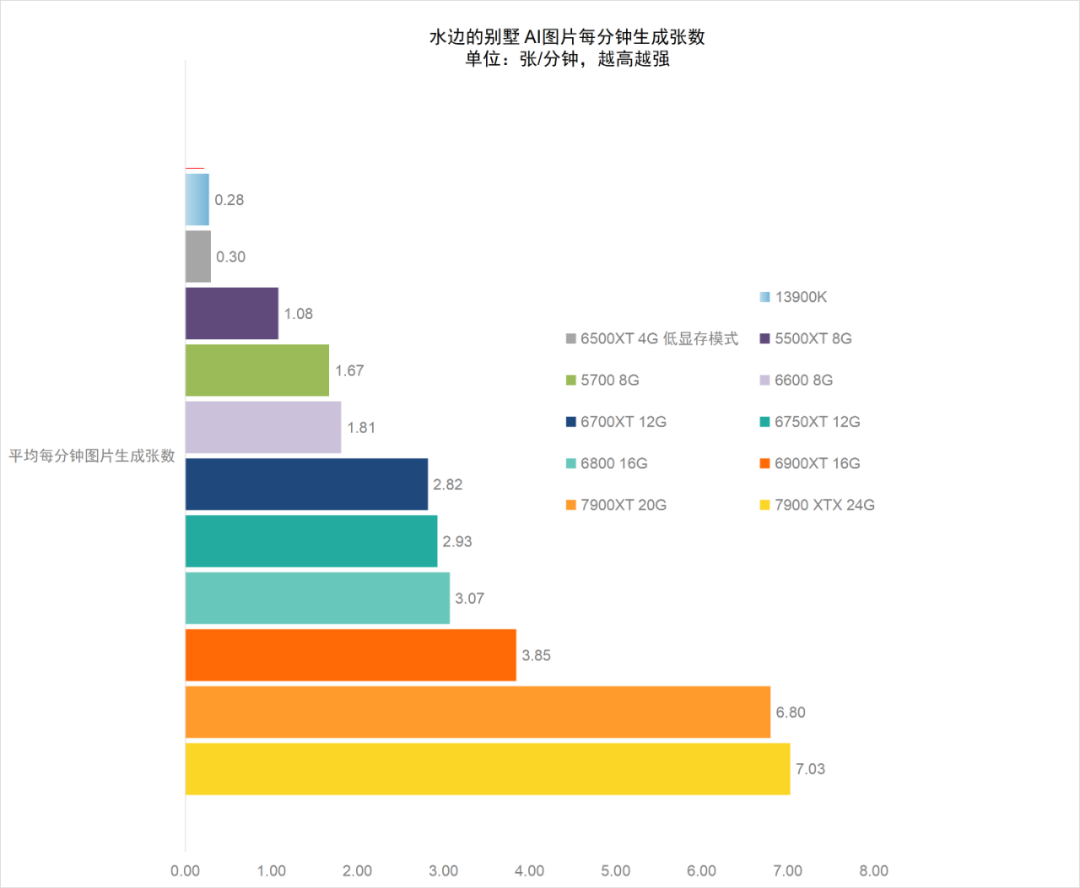
这部分的测试结果与前一测试基本保持了一致性。仍然是RX 7000系显卡在性能上独占鳌头,相对于RX 6000系显卡的对位提升在100%左右,与CPU的计算性能相比,GPU加速计算的性能提升仍然非常显著,RX 7900 XT的性能达到了酷睿i9-13900K的30倍左右,入门级显卡RX 5500XT,性能上也几乎接近酷睿i9-13900K的5倍。
4GB显存配置RX 6500XT由于仅能在低显存模式下运行,因此图片上生成速度还是受到了极大影响,远低于GPU加速的正常表现,大致与酷睿i9-13900K相当。
写在最后
这是一次简单但却比较有趣的测试,通过这次体验,我们认为有几点参考意见可以总结给玩家们参考:
1.当前AMD显卡已经可以通过开源的部署方案实现在Windows系统下的Stable Diffusion AI计算加速,而且网上也有许多的傻瓜式整合包,感兴趣的玩家完全可以一试;
2.从测试结果来看,AMD显卡在Stable Diffusion的AI图片生成计算中能够发挥出远胜于CPU计算的性能增幅,使用GPU加速计算能带来事倍功半的效果;
3.从测试情况来看,测试中当渲染分辨率设置超过512时(如768×768),就会出现爆显存的情况,这与部署方案和模型有一定关系,但也反映了在正常模式下运行时,8GB显存几乎是Stable Diffusion的硬性入门要求。如果显存低于8GB,即使在512×512分辨率下渲染,也会出现显存不足的情况,此时就不得不采用--lowvram的低显存运行方案,但会极大地拖累计算速度,如测试中的RX 6500XT 4GB。所以要想畅玩Stable Diffusion,我们建议显卡的显存为8GB或更高为佳;
4.从整体结果来看,我们认为AMD GPU还有极大的算法优化空间,凭不可靠经验判断,从RX 7900 XTX到酷睿i9-13900K的性能差距还不足够大。这和我们部署的算法方案以及模型都有一定关系,也希望各社区的程序员们能开发出更多更优秀的针对AMD显卡的计算加速方案。
不管如何,AMD显卡对Stable Diffusion的硬件加速计算性能已经得到了展现,效果也比较明显,对AMD显卡用户来说毫无疑问是利好的福音消息,剩下的就是玩家与AMD需要坚持的继续优化之路了。
审核编辑 :李倩
-
amd
+关注
关注
25文章
5705浏览量
140394 -
算法
+关注
关注
23文章
4800浏览量
98513 -
AI算法
+关注
关注
0文章
272浏览量
13196
原文标题:AI算法画小姐姐,AMD显卡比顶级CPU快30倍!AMD Radeon显卡Stable Diffusion AI画图体验测试
文章出处:【微信号:Microcomputer,微信公众号:Microcomputer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
历史首次!AMD服务器CPU市占率达50%
AMD扩展锐龙AI嵌入式处理器产品组合,为工业与AI边缘解决方案提供可扩展的高效 AI 计算能力

使用NORDIC AI的好处
Robotec.ai与AMD Silo AI的合作实践
LPDDR5X在AI数据中心多能打?10.7Gbps速率、互连快7倍、推理吞吐高5倍、延迟低80%!

AMD 推出锐龙 AI 嵌入式处理器产品组合,为汽车、工业和物理 AI 领域提供 AI 驱动的沉浸式体验

性能提升30倍:当AI存储冲刺“秒速”,谁为它的“出厂体检”按下快门?
AI算法开发,SpeedDP打辅助!不止10倍效率

AMD Vitis AI 5.1测试版现已开放下载
AMD Vitis AI 5.1测试版发布
谷歌芯片实现量子计算新突破,比超算快13000倍
今日看点:谷歌芯片实现量子计算比经典超算快13000倍;NFC 技术突破:读取距离从 5 毫米提升至 20 毫米
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
八天三次收购!AMD收购AI芯片制造商Untether AI团队,刺激创新




评论