 大模型训练,英伟达Turing、Ampere和Hopper算力分析
大模型训练,英伟达Turing、Ampere和Hopper算力分析

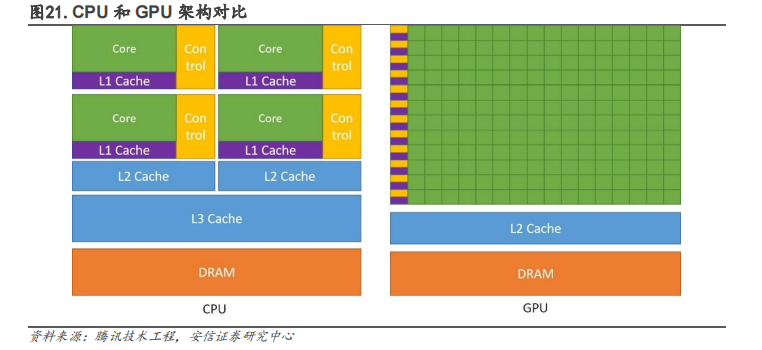
大 GPU 优势在于通过并行计算实现大量重复性计算。GPGPU即通用GPU,能够帮助 CPU 进行非图形相关程序的运算。在类似的价格和功率范围内,GPU 能提供比CPU 高得多的指令吞吐量和内存带宽。GPGPU 架构设计时去掉了 GPU 为了图形处理而设计的加速硬件单元,保留了 GPU 的 SIMT架构和通用计算单元,通过 GPU 多条流水线的并行计算来实现大量计算。
所以基于 GPU 的图形任务无法直接运行在 GPGPU 上,但对于科学计算,AI 训练、推理任务(主要是矩阵运算)等通用计算类型的任务仍然保留了 GPU 的优势,即高效的搬运和运算有海量数据的重复性任务。目前主要用于例如物理计算、加密解密、科学计算以及比特币等加密货币的生成。
随着超算等高并发性计算的需求不断提升,英伟达以推动 GPU 从专用计算芯片走向通用计算处理器为目标推出了GPGPU,并于 2006 年前瞻性发布并行编程模型 CUDA,以及对应工业标准的 OpenCL。CUDA 是英伟达的一种通用并行计算平台和编程模型,它通过利用图形处理器 (GPU)的处理能力,可大幅提升计算性能。CUDA 使英伟达的 GPU 能够执行使用 C、C++、Fortran、OpenCL、DirectCompute 和其他语言编写的程序。在 CUDA 问世之前,对 GPU 编程必须要编写大量的底层语言代码;CUDA 可以让普通程序员可以利用 C 语言、C++等为 CUDA 架构编写程序在 GPU平台上进行大规模并行计算,在全球 GPGPU 开发市场占比已超过 80%。GPGPU 与 CUDA 组成的软硬件底座,构成了英伟达引领 AI 计算及数据中心领域的根基。
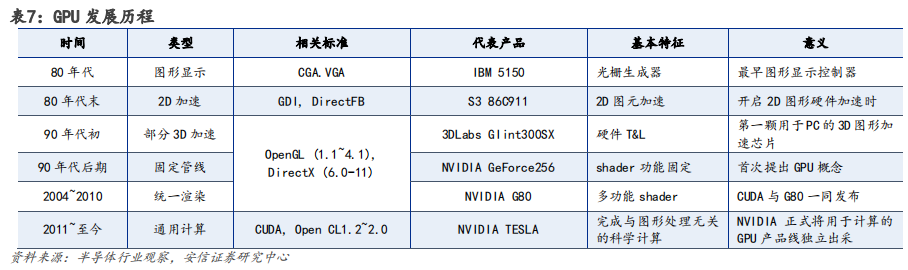
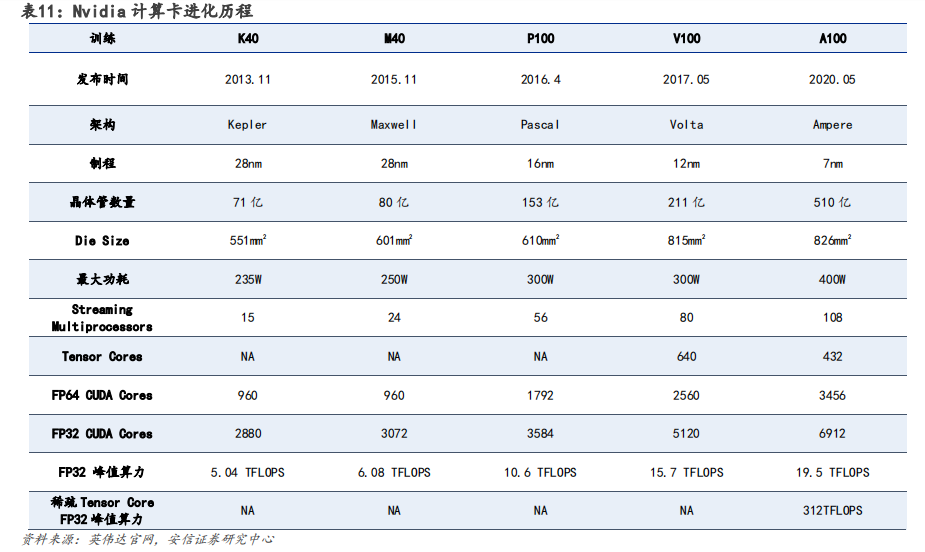
GPU 架构升级过程计算能力不断强化,Hopper 架构适用于高性能计算(HPC)和 AI 工作负载。英伟达在架构设计上,不断加强 GPU 的计算能力和能源效率。在英伟达 GPU 架构的演变中,从最先 Tesla 架构,分别经过 Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere至发展为今天的 Hopper 架构。
以 Pascal 架构为分界点,自 2016 年后英伟达逐步开始向深度学习方向演进。根据英伟达官网,Pascal 架构,与上一代 Maxwell 相比,神经网络训练速度提高 12 倍多,并将深度学习推理吞吐量提升了 7 倍。
Volta 架构,配备 640 个 Tensor 内核增强性能,可提供每秒超过 100 万亿次(TFLOPS)的深度学习性能,是上一代 Pascal 架构的 5 倍以上。
Turing 架构,配备全新 Tensor Core,每秒可提供高达 500 万亿次的张量运算。
Ampere架构,采用全新精度标准 Tensor Float 32(TF32),无需更改任何程序代码即可将AI 训练速度提升至 20 倍。
最新Hopper 架构是第一个真正异构加速平台,采用台积电 4nm 工艺,拥有超 800 亿晶体管,主要由 Hopper GPU、Grace CPU、NVLINK C2C 互联和 NVSwitch 交换芯片组成,根据英伟达官网介绍,其性能相较于上一代 Megatron 530B 拥有 30 倍 AI 推理速度的提升。
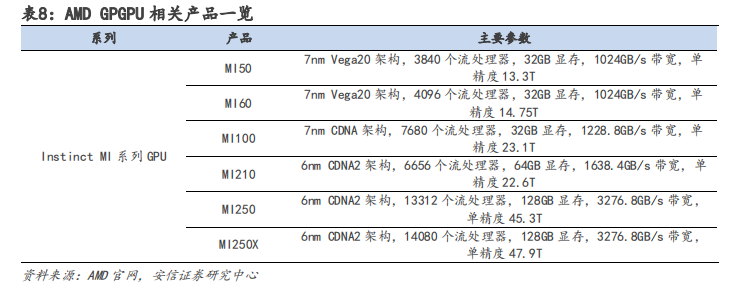
AMD 数据中心领域布局全面,形成 CPU+GPU+FPGA+DPU 产品矩阵。与英伟达相比,AMD 在服务器端 CPU 业务表现较好,根据 Passmark 数据显示,2021 年 Q4 AMD EPYC 霄龙系列在英特尔垄断下有所增长,占全球服务器 CPU 市场的 6%。依据 CPU 业务的优势,AMD 在研发 GPGPU 产品时推出 Infinity Fabric 技术,将 EPYC 霄龙系列 CPU 与 Instinct MI 系列 GPU 直接相连,实现一致的高速缓存,形成协同效应。此外,AMD 分别于 2022 年 2 月、4 月收购 Xilinx 和Pensando,补齐 FPGA 与 DPU 短板,全面进军数据中心领域。
软件方面,AMD 推出 ROCm 平台打造 CDNA 架构,但无法替代英伟达 CUDA 生态。AMD 最新的面向 GPGPU 架构为 CDNA 系列架构,CDNA 架构使用 ROCm 自主生态进行编写。AMD 的 ROCm 生态采取 HIP 编程模型,但 HIP 与 CUDA 的编程语法极为相似,开发者可以模仿 CUDA 的编程方式为 AMD 的 GPU 产品编程,从而在源代码层面上兼容 CUDA。所以从本质上来看,ROCm 生态只是借用了 CUDA 的技术,无法真正替代 CUDA 产生壁垒。
软硬件共同布局形成生态系统,造就英伟达核心技术壁垒。
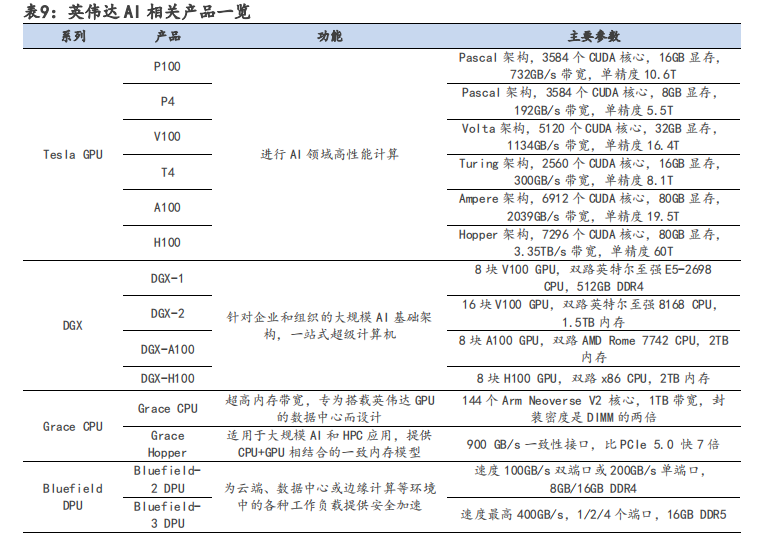
硬件端:基于 GPU、DPU 和 CPU 构建英伟达加速计算平台生态:
(1)主要产品 Tesla GPU 系列迭代速度快,从 2008 年至 2022 年,先后推出 8 种 GPU 架构,平均两年多推出新架构,半年推出新产品。超快的迭代速度使英伟达的 GPU 性能走在 AI 芯片行业前沿,引领人工智能计算领域发生变革。
(2)DPU 方面,英伟达于 2019 年战略性收购以色列超算以太网公司 Mellanox,利用其InfiniBand(无限带宽)技术设计出 Bluefield 系列 DPU 芯片,弥补其生态在数据交互方面的不足。InfiniBand 与以太网相同,是一种计算机网络通信标准,但它具有极高的吞吐量和极低的延迟,通常用于超级计算机的互联。英伟达的 Bluefield DPU 芯片可用于分担 CPU 的网络连接算力需求,从而提高云数据中心的效率,降低运营成本。
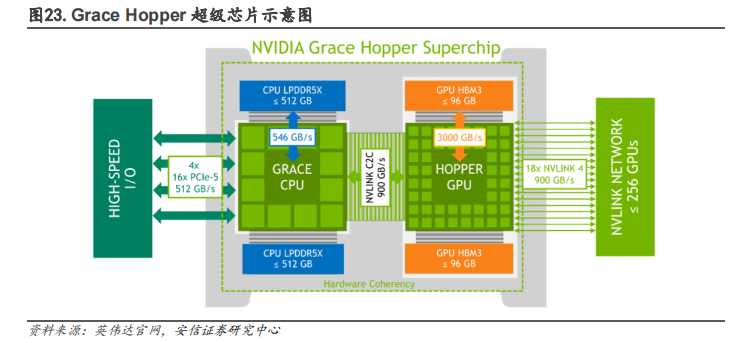
(3)CPU 方面,自主设计 Grace CPU 并推出 Grace Hopper 超级芯片,解决内存带宽瓶颈问题。采用 x86 CPU 的传统数据中心会受到 PCIe 总线规格的限制,CPU 到 GPU 的带宽较小,算效率受到影响;而 Grace Hopper 超级芯片提供自研 Grace CPU+GPU 相结合的一致内存模型,从而可以使用英伟达 NVLink-C2C 技术快速传输,其带宽是第 5 代 PCIe 带宽的 7 倍,极大提高了数据中心的运行性能。
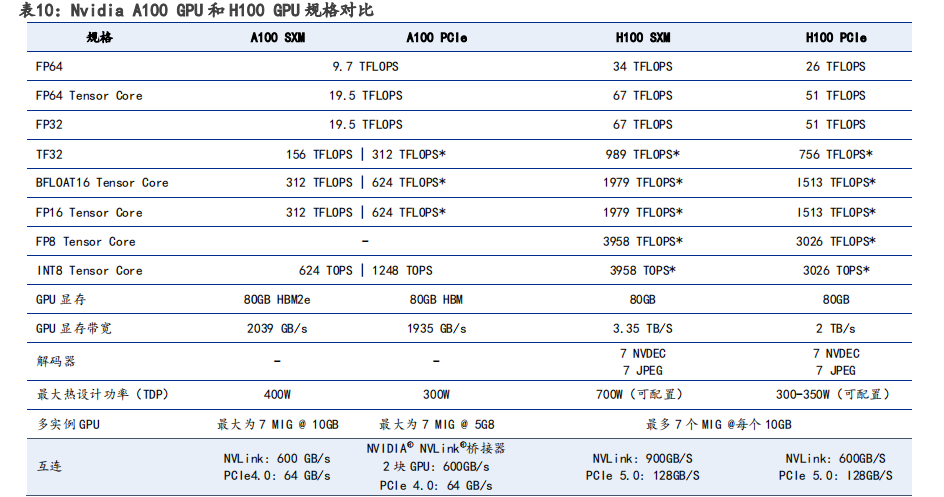
相较于 A100 GPU,H100 性能再次大幅提升。在 H100 配备第四代 Tensor Core 和 Transformer引擎(FP8 精度),同上一代 A100 相比,AI 推理能力提升 30 倍。其核心采用的是 TSMC 目前最先进的 4nm 工艺,H100 使用双精度 Tensor Core 的 FLOPS 提升 3 倍。
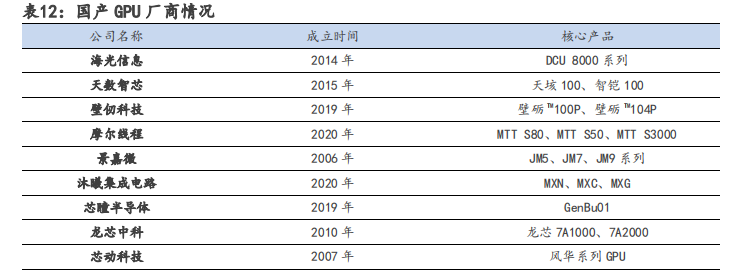
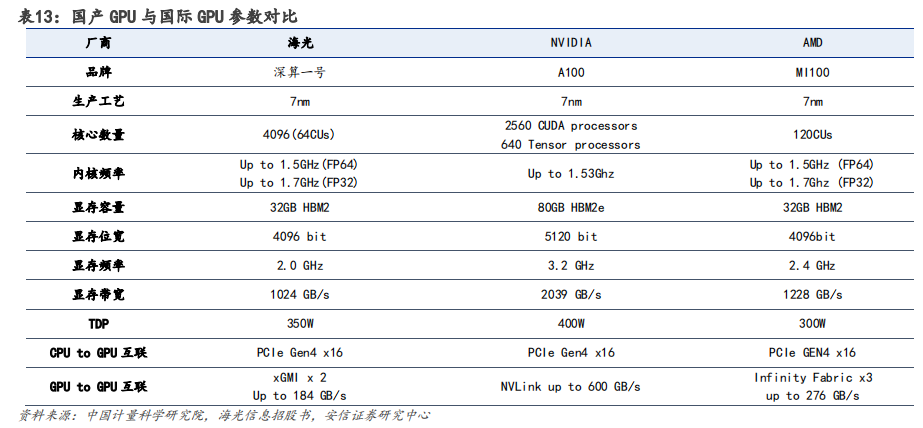
在算力需求快速增长的进程中,国产 GPU 正面临机遇与挑战并存的局面。目前,国产 GPU 厂商的核心架构多为自研,难度极高,需投入海量资金以及高昂的人力和时间成本。由于我国 GPU 行业起步较晚,缺乏相应生态,目前同国际一流厂商仍存在较大差距。在中美摩擦加剧、经济全球化逆行的背景下,以海光信息、天数智芯、壁仞科技和摩尔线程等为代表的国内 GPU 厂商进展迅速,国产 GPU 自主可控未来可期。
以Open AI的算力基础设施为例,芯片层面 GPGPU 的需求最为直接受益,其次是 CPU、AI 推理芯片、FPGA 等。AI 服务器市场的扩容,同步带动高速网卡、HBM、DRAM、NAND、PCB 等需求提升。
审核编辑 :李倩
-
gpu
+关注
关注
28文章
5321浏览量
136206 -
AI
+关注
关注
91文章
41972浏览量
303061 -
算力
+关注
关注
2文章
1773浏览量
16857
原文标题:大模型训练,英伟达Turing、Ampere和Hopper算力分析
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
通往AGI之路:揭秘英伟达A100、A800、H800、V100在高性能计算与大模型训练中的霸主地位




评论