 英伟达Grace Hopper CPU架构
英伟达Grace Hopper CPU架构

英伟达的 Grace CPU 和 Grace Hopper Superchip 有望在 2023 年初发布。
英伟达在下周的 Hot Chips 34 发布会之前宣布了有关Grace CPU Superchip的新细节,并透露该芯片采用4N工艺制造。英伟达还分享了有关架构、数据结构、性能和效率基准的更多信息。Grace芯片和服务器将在2023年上半年投入市场。
英伟达的Grace CPU是该公司第一款专为数据中心设计的CPU专用Arm芯片,在一块主板上有两个芯片,共144个核心,而Grace Hopper超级芯片则将Hopper GPU和Grace CPU结合在同一块板上。在披露中,英伟达最终正式确认 Grace CPU 使用 TSMC 4N 工艺。台积电在其5nm节点系列中列出了“N4”4nm工艺,将其描述为5nm节点的增强版。英伟达使用该节点的专用变体,称为“4N”,专门针对其GPU和CPU进行了优化。
随着摩尔定律的减弱,这些类型的专用节点变得越来越普遍,随着每个新节点的出现,晶体管的缩小变得越来越困难,成本也越来越高。为了实现英伟达4N等定制工艺节点,芯片设计公司和代工厂携手合作,使用设计技术协同优化(DTCO)为其特定产品输入定制功率、性能和面积(PPA)特性。
英伟达此前曾透露,其 Grace CPU 使用现成的Arm Neoverse内核作为其Grace CPU,但该公司尚未指定使用哪种特定版本。然而,英伟达披露,Grace使用Arm v9内核并支持SVE2,Neoverse N2平台是Arm第一个支持Arm V7和SVE2等扩展的IP。N2 Perseus 平台采用 5nm 设计(N4 属于 TSMC 的 5nm 系列)并支持 PCIe Gen 5.0、DDR5、HBM3、CCIX 2.0 和 CXL 2.0。Perseus 设计针对每功率性能(瓦特)和每面积性能进行了优化。Arm 表示,其下一代核心 Poseidon 要到 2024 年才会上市,考虑到 Grace 2023 年初的发布日期,这些核心不太可能成为候选者。
英伟达Grace Hopper CPU 架构
英伟达的新NVDIA calable Coherency Fabric (SCF) 是一种网状互连,与Arm Neoverse核心使用的标准CMN-700相干网状网络非常相似。
英伟达SCF 在各种 Grace 芯片单元(如 CPU 内核、内存和 I/O)之间提供 3.2 TB/s 的双向带宽,更不用说将芯片连接到主板上其他单元(无论是另一个Grace CPU还是Hopper GPU)的NVLink-C2C接口。
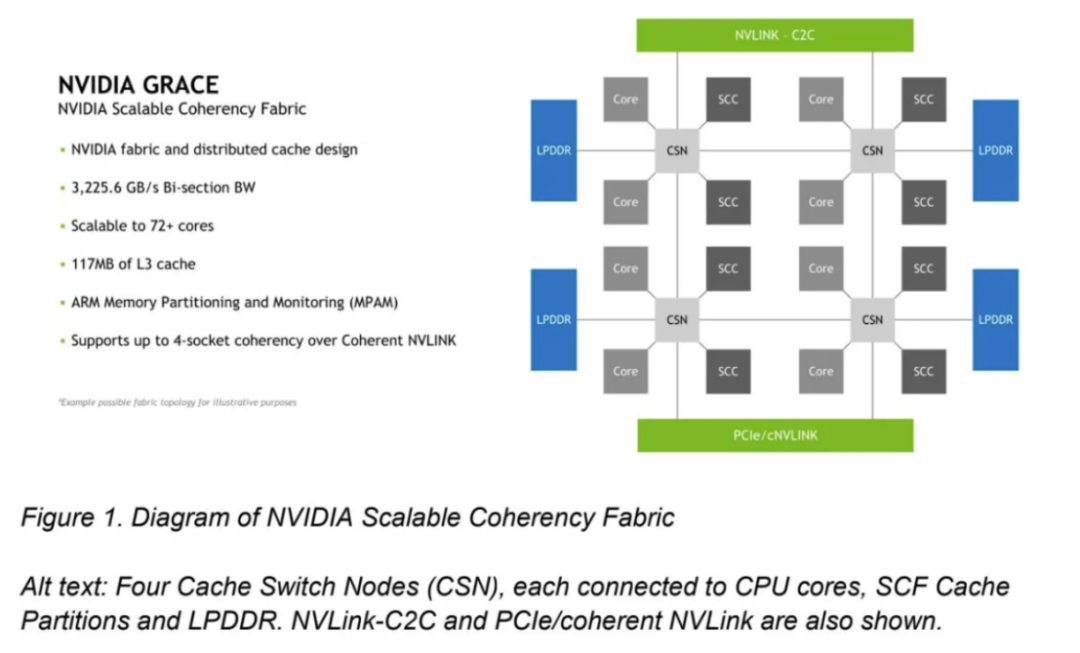
该网格支持 72+ 个内核,每个 CPU 有 117MB 的总 L3 缓存。英伟达表示,上面图片中的第一个方框图是“出于说明目的的可能拓扑结构”,其对齐方式与第二个方框图不完全一致。
此图显示了具有8个SCF缓存分区(SCC)的芯片,这些分区看起来是L3缓存片以及8个CPU单元。SCC 和内核以两个一组连接到缓存交换节点 (CSN),然后 CSN 驻留在 SCF 网状结构上,以提供CPU核心和芯片其余部分的存储器之间的接口。SCF 还通过 Coherent NVLink 支持多达四个插槽的一致性。
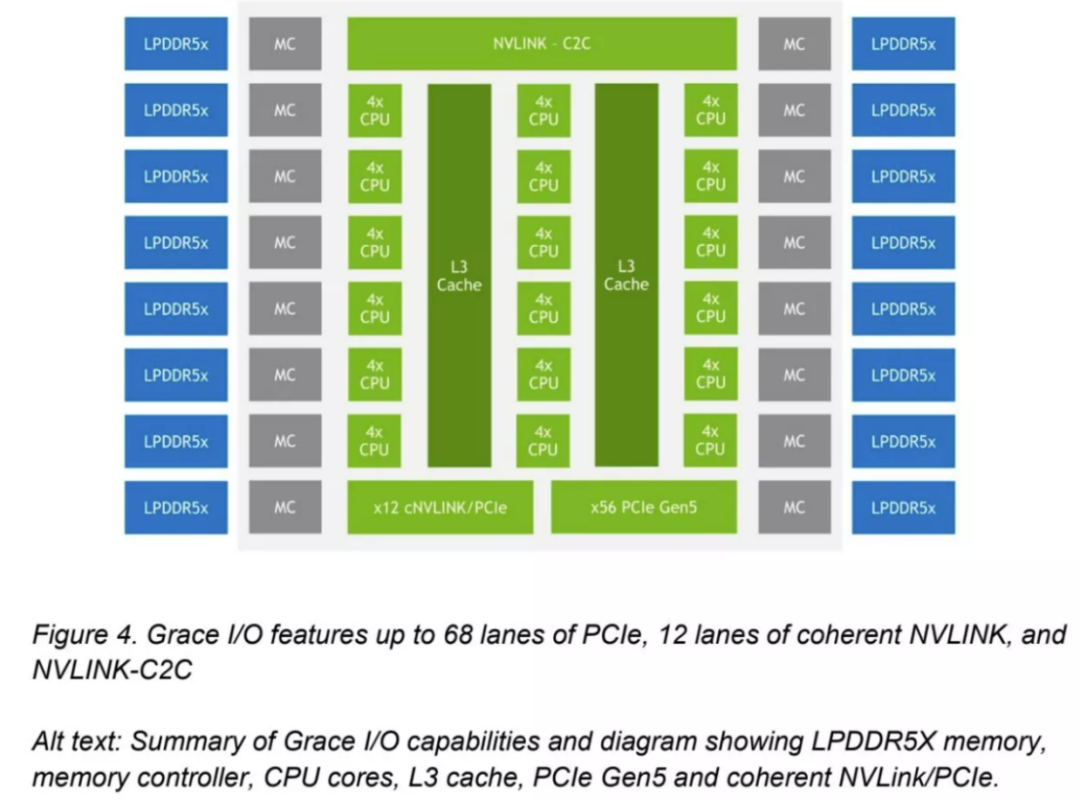
英伟达还分享了上图,显示每个Grace CPU支持多达68个PCIe通道和多达4个PCIe 5.0 x16连接。每个x16连接支持高达128 GB/s的双向吞吐量(x16链路可以分成两个x8链路),还有16个双通道LPDDR5X内存控制器(MC)。然而,这张图与第一张图不同——它将 L3 缓存显示为连接到四核 CPU 集群的两个连续块,这比之前的图更有意义,芯片中总共有 72 个内核。但是,我我们在第一张图中没有看到单独的SCF分区或CSN节点。
英伟达官方表示,Scalable Coherency Fabric (SCF) 是其专有设计,但 Arm 允许其合作伙伴通过调整核心数量、缓存大小和使用不同类型的内存(如 DDR5 和 HBM)来定制 CMN-700 网格,以及选择各种接口,如 PCIe 5.0、CXL 和 CCIX。这意味着 英伟达有可能为片上结构使用高度定制的 CMN-700 实现。
英伟达Grace Hopper 扩展 GPU 内存
GPU 需要高的内存吞吐量,因此,英伟达将目光转向提高内存吞吐量,不仅是芯片内部,还包括CPU和GPU之间。Grace CPU 有 16 个双通道 LPDDR5X 内存控制器,最多可支持 32 个通道,支持高达 512 GB 的内存和高达 546 GB/s 的吞吐量。英伟达表示,由于容量和成本等多种因素,它选择了 LPDDR5X 而不是 HBM2e。同时,与标准 DDR5 内存相比,LPDDR5X 提供了 53% 的带宽和 1/8 的每 GB 功耗,使其成为更好的选择。
英伟达还推出了扩展 GPU 内存 (EGM),它允许 NVLink 网络上的任何 Hopper GPU 访问网络上任何 Grace CPU 的 LPDDR5X 内存。
英伟达的目标是提供一个统一的内存池,可以在 CPU 和 GPU 之间共享,从而在简化编程模型的同时提供更高的性能。Grace Hopper CPU+GPU 芯片支持具有共享页表的统一内存,这意味着芯片可以与 CUDA 应用程序共享地址空间和页表,并允许使用系统分配器来分配 GPU 内存。
英伟达NVLink-C2C
CPU 内核是计算引擎,但互连是决定计算未来的战场。移动数据比实际计算数据消耗更多的能量,因此更快、更有效地移动数据,甚至避免数据传输,是一个关键目标。
英伟达的Grace CPU由一块板上的两个 CPU 组成,而 Grace Hopper Superchip 则由同一块板上的一个 Grace CPU 和一个 Hopper GPU 组成,旨在通过专有的NVLink芯片到芯片(C2C)互连最大化单元之间的数据传输,并提供一致性内存,以减少或消除数据传输。
英伟达分享了有关其 NVLink-C2C 互连的新细节,这是一种支持内存一致性的芯片到芯片和芯片到芯片互连,可提供高达 900 GB/s 的吞吐量(是 PCIe 5.0 x16 链路带宽的 7 倍)。该接口使用 NVLink 协议,英伟达使用其 SERDES 和 LINK 设计技术精心设计了该接口,重点关注能源和面积效率。NVLink-C2C 也支持行业标准协议,如 CXL 和 Arm 的 AMBA 相干集线器接口(CHI — Neoverse CMN-700 网格的CHI-key)。它还支持多种类型的连接,从基于PCB的互连到硅中介层和晶圆级实现。
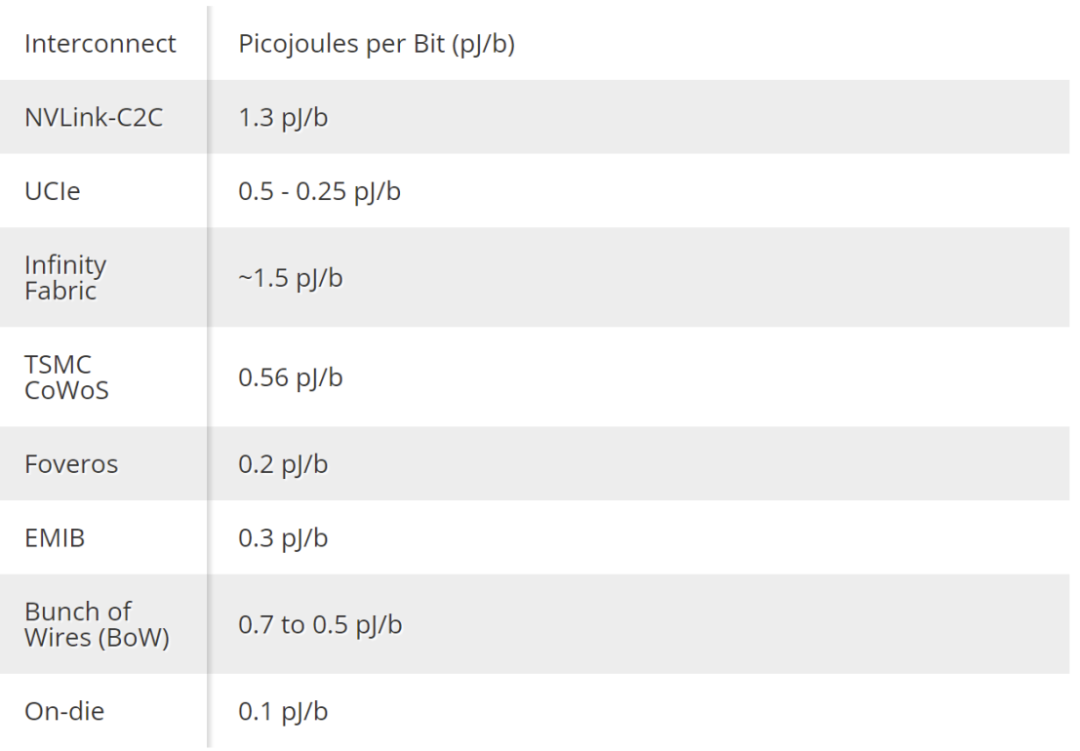
功率效率是所有数据结构的一个关键指标,如今,英伟达共享链路传输的数据每比特消耗1.3微微焦耳(pJ/b)。这是 PCIe 5.0 接口效率的 5 倍,但它是未来将上市的 UCIe 互连(0.5 到 0.25 pJ/b)功率的两倍多。封装类型各不相同,C2C link为 英伟达提供了性能和效率的完美结合,以满足其特定的使用情况。
英伟达Grace CPU 基准测试
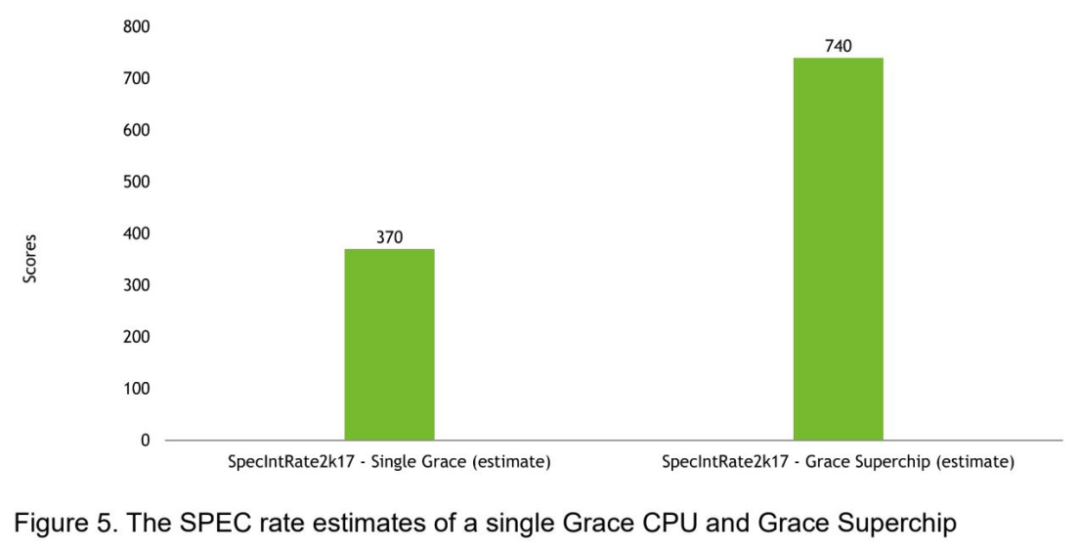
英伟达的新基准是SpecIntRate 2017基准中单台Grace CPU的370分。这英伟达已经共享了一个多CPU基准,在SPECTINTRATE2017基准中,两个Grace CPU的得分为740。显然,这表明两个芯片的线性缩放改进。
AMD目前的第二代EPYC Milan芯片是数据中心目前的性能领导者,发布的规格结果从382到424片不等,这意味着高端x86芯片仍将保持领先地位。然而,英伟达的解决方案将具有许多其他优势,如功率效率和更GPU友好的设计。
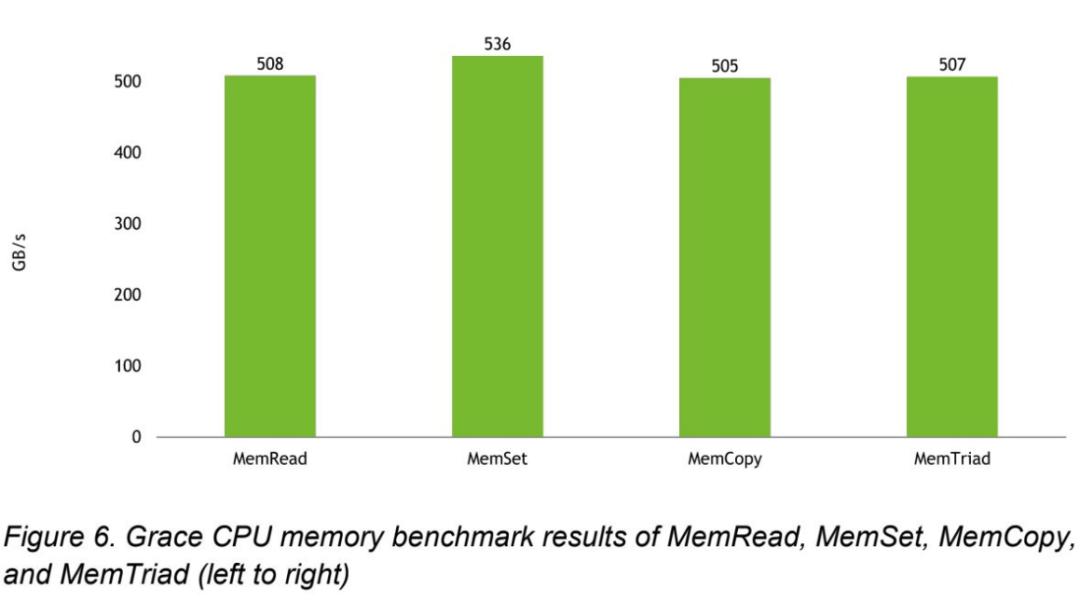
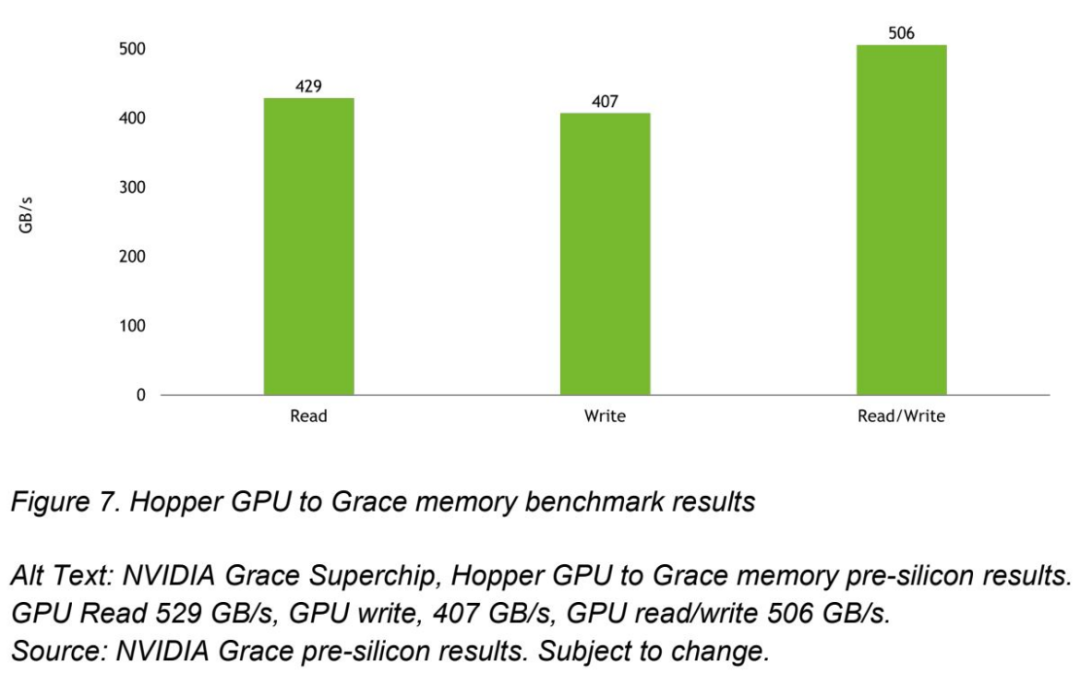
英伟达分享了其内存吞吐量基准,表明Grace CPU在CPU内存吞吐量测试中可以提供约500 GB/s的吞吐量。英伟达还声称,该芯片还可以将高达506Gb/s的组合读/写吞吐量推送到连接的Hopper GPU,并在读吞吐量测试期间将CPU到GPU的带宽计时为429Gb/s,在写入时为407Gb/秒。
Grace Hopper ARM系统准备好了吗?
英伟达还宣布 Grace CPU Superchip 将遵守获得 System Ready 认证的必要要求。以获得系统就绪认证。该认证意味着Arm芯片将与操作系统和软件一起“正常工作”,从而简化部署。Grace 还将支持虚拟化扩展,包括嵌套虚拟化和 S-EL2 支持。英伟达还列出了对以下内容的支持:
nRAS v1.1 通用中断控制器 (GIC) v4.1
n内存分区和监控 (MPAM)
n系统内存管理单元 (SMMU) v3.1
nArm 服务器基础系统架构 (SBSA) 可实现符合标准的硬件和软件接口
此外,为了在基于 Grace CPU 的系统上启用标准引导流程,Grace CPU被设计为支持Arm服务器基本引导要求(SBBR)。
对于缓存和带宽分区以及带宽监控,Grace CPU还支持Arm内存分区和监控(MPAM)。Grace CPU 还包括 Arm 性能监控单元,允许对 CPU 内核以及片上系统 (SoC) 架构中的其他子系统进行性能监控。这使得标准工具(例如 Linux perf)能够用于性能调查。英伟达的 Grace CPU 和 Grace Hopper Superchip 有望在 2023 年初发布,其中 Hopper 变体适用于 AI 训练、推理和 HPC,而双 CPU Grace 系统则专为 HPC 和云计算工作负载而设计。
审核编辑 :李倩
-
cpu
+关注
关注
68文章
11370浏览量
226406 -
架构
+关注
关注
1文章
537浏览量
26664 -
英伟达
+关注
关注
23文章
4126浏览量
99776
原文标题:详解英伟达Grace Hopper CPU 超级芯片设计
文章出处:【微信号:ICViews,微信公众号:半导体产业纵横】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
RV生态又一里程碑:英伟达官宣CUDA将兼容RISC-V架构!
英伟达+联发科,打入游戏本市场?
英伟达算力中心电源架构的变革性演进与国产生态应用研究报告

新思科技与英伟达多项硬核科技成果亮相GTC 2026

英伟达重磅出手!AI 推理存储全面觉醒

NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备
英伟达发布 NVQLink 开放系统架构;国内首个汽车芯片标准验证平台投入使用
纳微半导体助力英伟达打造800 VDC电源架构
英伟达加速800V HVDC架构落地,三家本土企业打入供应链!



评论