 用3D堆叠技术打造DRAM成为L4级缓存,华邦电子CUBE解决方案助力边缘AI
用3D堆叠技术打造DRAM成为L4级缓存,华邦电子CUBE解决方案助力边缘AI

华邦电子一直以来提供闪存和DRAM的良品裸晶圆(KGD)产品,KGD可以与SoC进行合封,以实现更优的成本和更小的尺寸。据华邦电子次世代内存产品营销企划经理曾一峻介绍,在KGD1.0中裸片最厚处大约为100-150微米,裸片至裸片(dieto die)的I/O 路径为1000 微米,目前这种性能的KGD信号完整性/电源完整性(SI/PI)是主流也够用。在对LPDDR4的电源效率进行估算时显示,其小于35pJ/Byte,带宽方面 X32 LPDDR4x每I/O为17GB/s。
如今华邦电子KGD进入2.0时代。KGD2.0是以3D堆叠的KGD,通过TSV的深宽比能力(也就是aspect Ratio),可以做到1:10,实现厚度更薄。华邦目前可以实现50微米的深度,相当于需要将芯片打磨至2mil。未来通过HybridBonding工艺可以实现1微米的距离。同时,在KGD2.0工艺下,信号完整性/电源完整性(SI/PI)表现会更好,并且功耗更低,可以低于LPDDR4的四分之一,为8pJ/Byte,而带宽可以实现16-256GB/s。KGD2.0性能更好、成本更优、更容易按时交付。
CUBEDRAM的3D堆叠技术特点
今年2月,华邦宣布加入了UCIe联盟,华邦可协助系统单芯片客户(SoC)设计与 2.5D / 3D 后段工艺(BEOL, back-end-of-life)封装连结。其推出CUBE解决方案,提供半定制化的紧凑超高带宽DRAM(Customized/Compact Ultra Bandwidth Elements)。
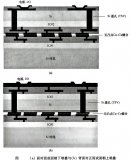
从CUBE的结构来看,是将SoC裸片置上,DRAM裸片置下,省去SoC的TSV工艺。下图右边虚线部分所示: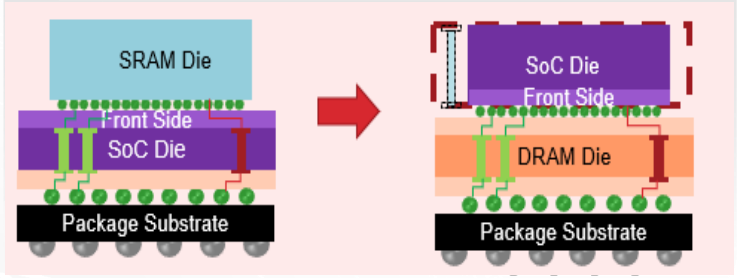
曾一峻分析,传统上CPU为了增加高速缓存能效,直接增加SRAM的带宽和容量,这样的方式会增加非常高的成本。为了节省成本,厂商会使用相对成熟制程的SRAM,例如5nm的 SoC裸片上堆叠7nm的SRAM 裸片。但这种架构下,底部的CPU就需要埋入相当多的TSV,同时增加CPU裸片面积,成本依然会相对较高,如上图左边的示意。
而采用华邦的解决方案(上图右边所示),SoC裸片尺寸缩小,成本相应降低,同时通过华邦的DRAM TSV工艺,可以将SoC的信号引至外部,使它们成为同一个封装芯片。DRAM做TSV的好处是其裸片将会变得很薄,尺寸变得更小。
SoC裸片置上也可以带来更好的散热效果,满足现在AI高算力的需求。总之进行3D堆叠以及CUBEDRAM裸片堆叠可以带来高带宽、低功耗和优秀的散热表现。
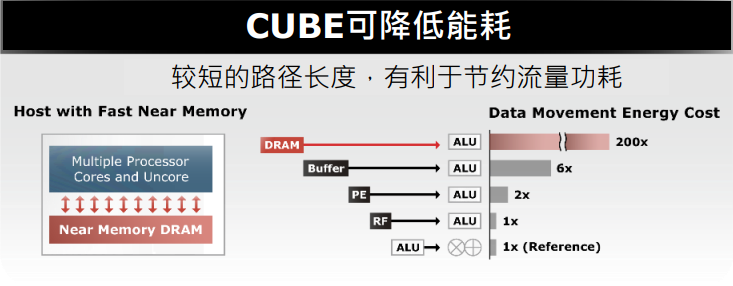
华邦的CUBE还可以降低功耗。曾一峻解析,当SoC裸片和DRAM裸片堆叠的时候,相比于传统的引线键合(WireBonding),微键合(MicroBonding)可以将1000微米的线长缩短至40微米,仅有传统长度的2.5%。在未来的混合键合(HybridBonding)封装工艺下,线长甚至可以缩短至1微米。从芯片内部来看,信号所经过的传输距离更短,因此功耗可相应地降低。此外,采用混合键合工艺,两颗堆叠的芯片可以被看作同一颗芯片,因此内部传输信号和SIP表现会更优秀。
曾一峻进一步指出,DRAM裸片中都会包含电容,华邦的CUBE芯片提供硅电容(Si-Cap)。硅电容的好处在于可以降低电源波动带来的影响。例如,如果先进制程的SoC的核心电压只有0.75V-1V左右,并且运行过程中电源产生一些波动,除了会影响到功耗,还会影响信号的稳定性,而硅电容容量提高的情况下,SoC借助硅电容就可以获得稳定的电压。
下图是华邦当前硅电容规格和制程的进展,今年下半年会带来更优规格的硅电容。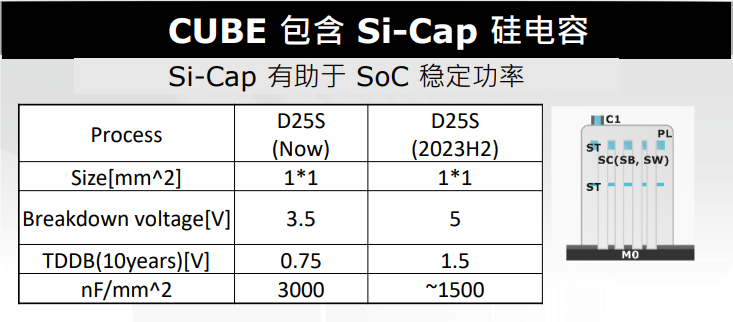
通过上面表格的参数,可以看到尽管电容缩小到了一半,但是运行经时击穿电压(TDDB)被提高一倍至1.5V。1.5V目前是大部分先进制程芯片的核心电压。此外击穿电压也是目前先进制程所需的5V,因此1500nF/(mm2)其实是可以符合目前先进制程芯片的电容需求。
华邦还提供中介层中介层(Interposer),目前正在进行内部技术演进的是华邦的DRAM堆叠与中介层(Interposer)的架构,以这样的架构开发DRAM的目的是可以验证华邦的TSV。
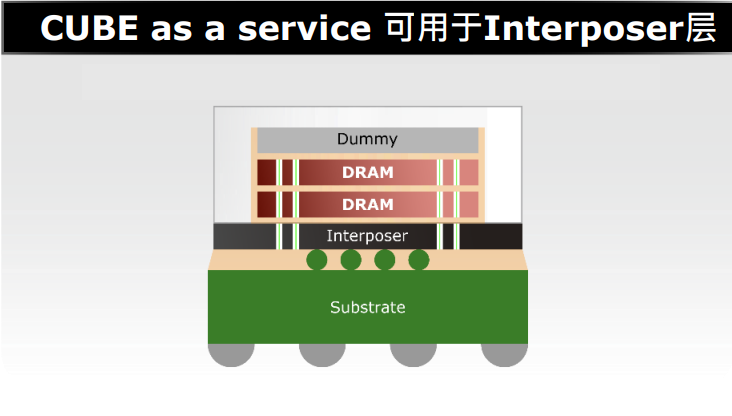
至此,华邦电子成立了3DCaaS平台,可以向客户提供包括DRAM、中介层、硅电容在内的整体解决方案。这也是华邦加入UCIe后带来的贡献之一。“无论是TSV、还是WOW(WaferonWafer),华邦都已经达成了与业内相关企业的合作,构建了合作伙伴生态。在COW(ChiponWafer)方面,华邦将提供TSV的DRAM裸片,并且会帮助SoC客户通过适合的合作伙伴进行后续封测。COW还包含了2.5D、Fan-Out以及3D堆叠工艺,其中2.5D和3D堆叠所用到的硅中介层华邦都可以提供,并且华邦的硅电容还能使芯片的SI/PI减小,使能耗表现更好。甚至华邦的Si-Bridge还能让硅中介层的裸片尺寸更小。”曾一峻说道。
可作为L4级缓存用于边缘计算
华邦的CUBE解决方案主要面向低功耗、高带宽,以及中低容量的内存需求,适合于边缘计算和生成式AI等应用。
例如在AI-ISP架构中,如下图所示,灰色部分属于神经网络处理器(NPU),如果AI-ISP要实现大算力,需要很大的带宽,或者是SPRAM。但是在AI-ISP上使用SPRAM的成本非常高,不太可行。如果使用LPDDR4就需要4-8颗,无论是合封还是外置,成本同样相当高昂。此外,还有可能会用到传输速度为4266Mhz的高速LPDDR4,而这样的产品需要依赖7nm或12nm的先进制程工艺生产。

华邦的CUBE解决方案可以允许客户使用成熟制程(例如28、22nm)的SoC,获得类似的高速带宽。华邦的CUBE解决方案可以通过多个I/O(256或者512个)结合28nm SoC提供的500MHz的运行频率,以此实现更高带宽,带宽最高可增至256GB/s。不仅如此,华邦在未来可能会和客户探讨64GB/s带宽的合作,I/O数可以减少,裸片的尺寸也会进一步缩小。
随着CPU高速运算需求对制程的要求越来越高,我们可以看到16nm、7nm、5nm到3nm的CPU,SRAM占比(如下图中红色部分所示)并不会同比例缩小,因此当需要实现AI运算或者进行高速运算的情况下,就需要把L3的缓存SRAM容量加大,即便可以使用堆叠的方式达到几百MB,也会导致高昂的成本。

华邦的方案是把L3缓存缩小,转而使用L4缓存的CUBE解决方案。当然,L4缓存之所以被称作L4,首先是因为它的延迟(Latency)会比L3的稍长。曾一峻表示,为了克服这个问题,可以采用多BANK的方式(multibankper channel),来获得更好的存取效率。第二个方式是将重写(rewrite) IO分开,这是一个比较类SRAM的方式,缩短运行时间。换句话说,是以某些比较特殊的架构进行产品修正,我们会针对客户的一些特殊需求和应用场景进行定制化调配,缩短L4缓存的延迟。
同时,AI模型在某些情况下还是需要外置一定容量的内存,例如在某些边缘计算的场景下会需要8-12GB的LPDDR4或者是LPDDR5,因此也可以外挂高容量的工作内存(Working Memory)。综上所述,CUBE可以允许使用成熟制程,以降低SoC成本、减小芯片功耗以及获得高带宽这三大主要诉求。
据透露,目前华邦就CUBE解决方案已经和几家客户展开了项目洽谈,具体的合作内容也还处在进行时,包括了边缘计算和生成式AI这两个应用方向。依照目前的进展,或许明年会有一些官方的合作新闻发布。
曾一峻认为,CUBE解决方案在边缘计算服务器领域将有很大的机会。相对于大模型的训练,在边缘服务器上可以把模型缩小,但是它一样需要具备很高带宽的内存(通过堆叠DRAM),但不需要很高的容量。无论是监控(surveillance)或5G的边缘计算服务器,或是中小企业内部部署的数据中心服务器(on-premise data server center),都有可能会运用到华邦的CUBE解决方案。
华邦电子DRAM路线
华邦目前拥有两座12寸晶圆厂,一个是位于台中的Fab6工厂;另外,从去年的下半年开始,华邦在高雄新建的第二座厂已经正式量产,目前的投片量达到了1万片/月左右。后续高雄厂规划的产能会逐渐爬坡到1.4万片至2万片/月。
高雄厂主要生产先进制程的DRAM,台中厂的中小容量DRAM制程会维持在65nm、46nm以及38nm、25nm,以成熟制程为主。目前高雄厂已在量产的25nm产品包括2GB和4GB两种产品,已经开始大批量交付。20nm产品在今年中也会进入量产阶段,下一步会向19nm制程演进。
华邦DDR3主要有1Gb、2Gb、4Gb以及8Gb四种容量,同时需要强调的是,华邦会持续进行DDR3的生产和支持。华邦的DDR4规划是在今年中,20nm的制程就绪以后在高雄厂生产。量产时间规划在2024年初。后续DDR3产品在2025年会演进至16nm。
在业界很多大厂停产DDR3之时,华邦表示未来会持续生产DDR3,据OMDIA的报告DDR3产品将持续存在到2027、2028年。特别是在车用、工业用的场景,DDR3是更加成熟且尺寸、成本更有优势的一代产品。
存储市场预期
我们看到,存储行业经过从去年下半年开始到今年上半后的调整,主要是大厂削减产能、减少资本支出,延迟新厂建设计划等,以期让存储行情企稳。对此,华邦电子大陆区产品营销处处长朱迪表示,虽然今年上半年大环境还是处于调库存的状态,但是需求已经逐渐回暖。在消费类的应用上,客户的下单力道慢慢在恢复。同时也有一些客户也在观望库存调整以及价格下跌是否已经到达阶段性低谷,开始来跟各家内存厂商洽谈准备下一些长期的订单。
因此,朱迪认为,今年上半年应该还是底部阶段,但是市况会逐渐改善。尤其是国内出台了一些相应的刺激经济的措施,包括数字经济发展、AI产业的推动等,因此对于下半年的存储市场比较乐观。
朱迪表示,另一个维度看,汽车和工业应用是华邦耕耘较好的领域,占到去年营收的29%。这也是为什么大环境虽然如此不好,去年华邦的营收表现还算不错的原因。这一类客户更看重于品质的稳定性和交付的保证。华邦作为一个拥有自有工厂的IDM,同时又更聚焦于这些中小容量DDR3及以下的产品,赢得客户的信任和认可。另外,在消费类、网通类产品,它的DDR3以及往DDR4演进的速度会比预想的快一些。主要原因是主芯片厂商要追求更高的带宽,以及市场价格的走向影响。
“利基型存储市场的特点是整个市场的盘子会比较小,大概占整个存储的10%不到。所以它的供需相对而言是比较平衡和稳定的。因此这一市场受到波动的影响相对较小。谨慎乐观看待今年下半年存储行业的复苏。”朱迪说道。
-
DRAM
+关注
关注
41文章
2403浏览量
189704 -
华邦电子
+关注
关注
0文章
88浏览量
17222 -
3D封装
+关注
关注
9文章
150浏览量
28397
发布评论请先 登录
端侧AI“堆叠DRAM”技术,这些国内厂商发力!

华为在MWC 2026正式发布核心网AN L4目标解决方案CORESpirit
简单认识3D SOI集成电路技术
铠侠公布3D DRAM 技术

Kioxia研发核心技术,助力高密度低功耗3D DRAM的实际应用
华邦电子推出先进 16nm 制程 8Gb DDR4 DRAM 专为工业与嵌入式应用而生

NVIDIA与Uber合作推进全球L4级自动驾驶移动出行网络
Socionext推出3D芯片堆叠与5.5D封装技术

【「AI芯片:科技探索与AGI愿景」阅读体验】+半导体芯片产业的前沿技术
iTOF技术,多样化的3D视觉应用
《电子发烧友电子设计周报》聚焦硬科技领域核心价值 第26期:2025.08.25--2025.08.29
华邦电子重新定义AI内存:为新一代运算打造高带宽、低延迟解决方案



评论