 英伟达AI加速器新蓝图:集成硅光子I/O,3D垂直堆叠 DRAM 内存
英伟达AI加速器新蓝图:集成硅光子I/O,3D垂直堆叠 DRAM 内存

来源:TECHPOWERUP
2024 IEEE IEDM 会议目前正在美国加州旧金山举行。据分析师 Ian Cutress 在其社交平台上发布的动态,英伟达在本次学术会议上分享了有关未来 AI 加速器设计的愿景。
英伟达认为未来整个 AI 加速器复合体将位于大面积先进封装基板之上,采用垂直供电,集成硅光子 I/O 器件,GPU 采用多模块设计,3D 垂直堆叠 DRAM 内存,并在模块内直接整合冷板。
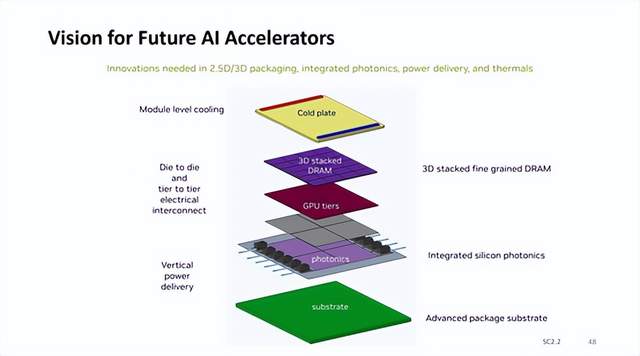
在英伟达给出的模型中,每个 AI 加速器复合体包含 4 个 GPU 模块,每个 GPU 模块与 6 个小型 DRAM 内存模块垂直连接并与 3 组硅光子 I/O 器件配对。
硅光子 I/O 可实现超越现有电气 I/O 的带宽与能效表现,是目前先进工艺的重要发展方向;3D 垂直堆叠的 DRAM 内存较目前的 2.5D HBM 方案拥有更低信号传输距离,有益于 I/O 引脚的增加和每引脚速率的提升;垂直集成更多器件导致发热提升,模块整合冷板可提升解热能力。
热管理是另一个关键考虑因素。多层 GPU 设计带来了复杂的冷却挑战,而目前的技术无法充分解决这一问题。NVIDIA 承认,在将 DRAM 堆叠在逻辑上的概念成为现实之前,材料科学必须取得重大进展。该公司正在探索创新解决方案,包括实施芯片内冷却系统,例如使用专用冷板进行模块级冷却。这种设计的商业化还需要一段时间,Ian Cutress 博士等分析师预测,采用这种技术的产品可能会在 2028-2030 年左右上市。
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
加速器
+关注
关注
2文章
836浏览量
39712 -
AI
+关注
关注
89文章
38091浏览量
296601 -
英伟达
+关注
关注
23文章
4040浏览量
97669 -
DRAM内存
+关注
关注
0文章
9浏览量
3746
发布评论请先 登录
相关推荐
热点推荐
边缘计算中的AI加速器类型与应用
人工智能正在推动对更快速、更智能、更高效计算的需求。然而,随着每秒产生海量数据,将所有数据发送至云端处理已变得不切实际。这正是边缘计算中AI加速器变得不可或缺的原因。这种专用硬件能够直接在边缘设备上

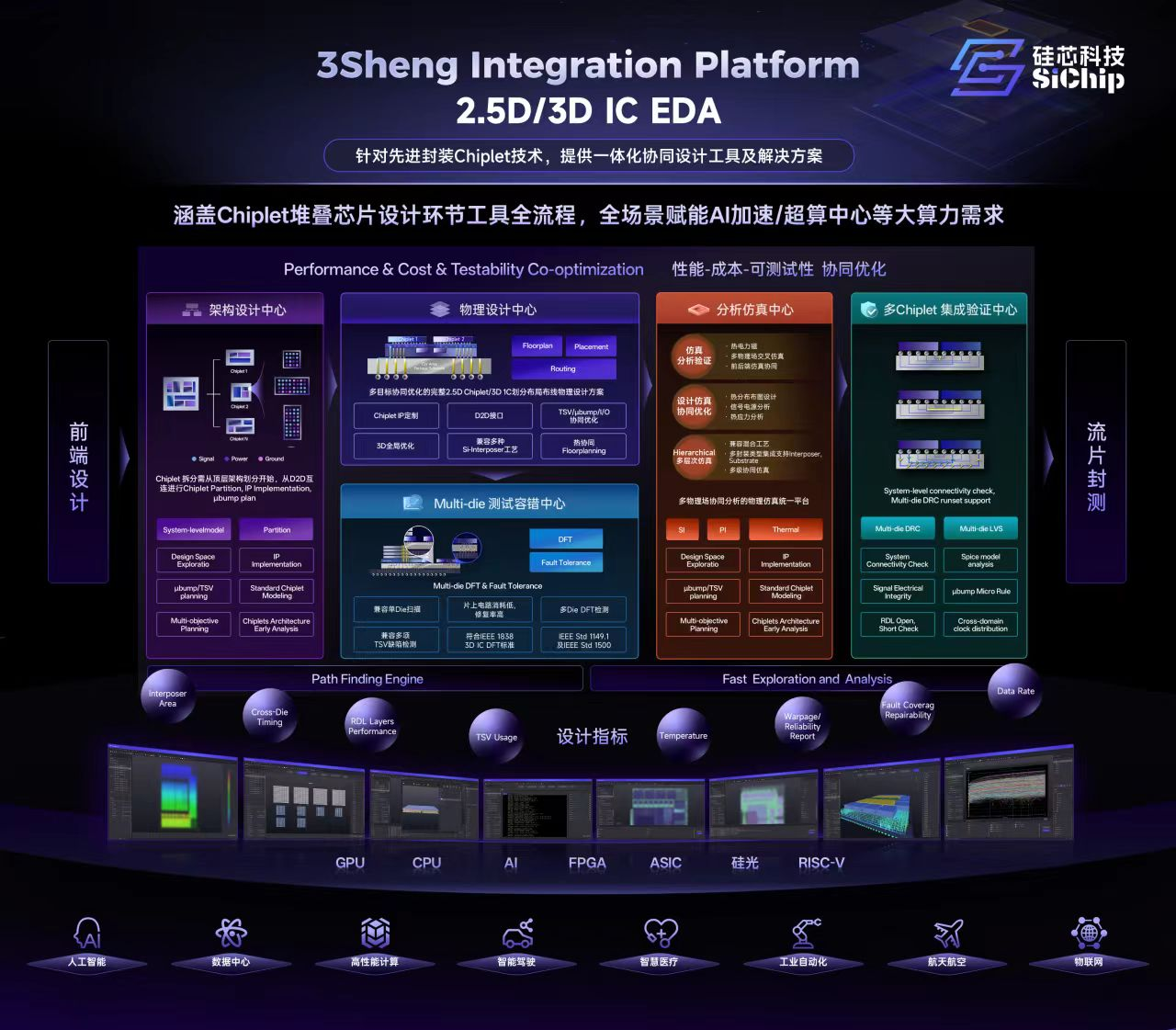
硅芯科技:AI算力突破,新型堆叠EDA工具持续进化
电子发烧友网报道(文/黄晶晶)先进封装是突破算力危机的核心路径。2.5D/3D Chiplet异构集成可破解内存墙、功耗墙与面积墙,但面临多物理场分析、测试容错等EDA设计挑战。现有E
一些神经网络加速器的设计优化方案
加以后的部分和 psum 保留,直到完成整个 2D或 3D 滑动窗口计算再写入内存,最多复用 R*R*C 次,完成一个输出特征图像素。
l 输入固定 Input Stationary (IS):输入
发表于 10-31 07:14
【「AI芯片:科技探索与AGI愿景」阅读体验】+半导体芯片产业的前沿技术
。
叉行片:连接并集成两个晶体管NFET和PFET,它们之间同时被放置一层不到10nm的绝缘膜,放置缺陷的发生。
CFET:属于下一代晶体管结构,采用3D堆叠式GAAFET,面积可缩小至原来的50
发表于 09-15 14:50
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
两方面的问题:①Transformer 模型需要向NVM器件写入大量数据。②传统内存加速器的时序单指令多数据流通通道实现这些操作的成本很高。
因此设计一种既能有效存储模型参数,又能让动态矩阵乘法运算
发表于 09-12 17:30
详解WLCSP三维集成技术
。然而,当系统级集成需求把 3D 封装/3D IC 技术推向 WLCSP 时,传统方案——引线键合堆叠、PoP、TSV 硅通孔——因工艺窗口

继HBM之后,英伟达带火又一AI内存模组!颠覆AI服务器与PC
Attached Memory Module,即小型化压缩附加内存模组,是英伟达主导开发的一种新型内存模块,是适用于数据中心 AI 服务
简单认识高带宽存储器
HBM(High Bandwidth Memory)即高带宽存储器,是一种基于 3D 堆叠技术的高性能 DRAM(动态随机存取存储器)。其核

新思科技携手英伟达加速芯片设计,提升芯片电子设计自动化效率
B200 Blackwell架构,新思科技 Proteus预计将计算光刻仿真的速度提升达20倍 英伟达NIM推理微服务集成将生成式AI驱动的
发表于 03-19 17:59
•437次阅读
英伟达开发新型内存模组SOCAMM,或年底量产
大内存制造商深入讨论SOCAMM规范的商业化落地可能性。这意味着,SOCAMM内存模组有望最早在今年年底实现量产,为全球用户带来更加高效、稳定的内存解决方案。 值得一提的是,英伟
腾讯混元3D AI创作引擎正式发布
近日,腾讯公司宣布其自主研发的混元3D AI创作引擎已正式上线。这一创新性的创作工具将为用户带来前所未有的3D内容创作体验,标志着腾讯在AI技术领域的又一重大突破。 混元
腾讯混元3D AI创作引擎正式上线
近日,腾讯公司宣布其自主研发的混元3D AI创作引擎已正式上线。这一创新性的创作工具,标志着腾讯在3D内容生成领域迈出了重要一步。 混元3D AI






 工商网监
工商网监
评论