 NVIDIA Triton 系列文章(13):模型与调度器-3
NVIDIA Triton 系列文章(13):模型与调度器-3

前面两篇文章,已经将 Triton 的“无状态模型”、“有状态模型”与标准调度器的动态批量处理器与序列批量处理器的使用方式,做了较完整的说明。
大部分的实际应用都不是单纯的推理模型就能完成服务的需求,需要形成前后关系的工作流水线。例如一个二维码扫描的应用,除了需要第一关的二维码识别模型之外,后面可能还得将识别出来的字符传递给语句识别的推理模型、关键字搜索引擎等功能,最后找到用户所需要的信息,反馈给提出需求的用户端。
本文的内容要说明 Triton 服务器形成工作流水线的“集成推理”功能,里面包括“集成模型(ensemble model)”与“集成调度器(ensemble scheduler)”两个部分。下面是个简单的推理流水线示意图,目的是对请求的输入图像最终反馈“图像分类”与“语义分割”两个推理结果:
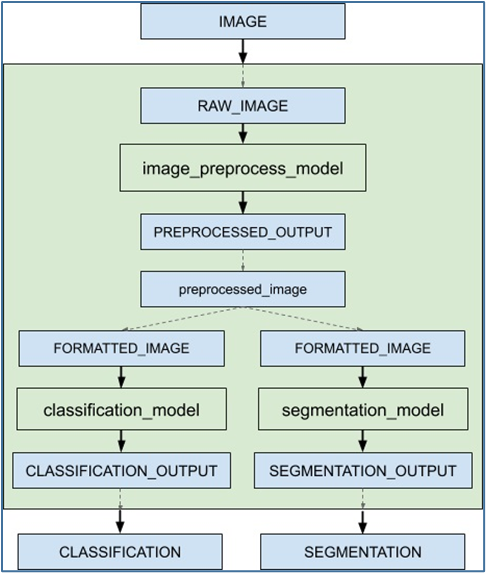 当接收到集成模型的推断请求时,集成调度器将:
当接收到集成模型的推断请求时,集成调度器将:
当接收到集成模型的推断请求时,集成调度器将:
- 确认请求中的“IMAGE”张量映射到预处理模型中的输入“RAW_IMAGE”。
- 检查集合中的模型,并向预处理模型发送内部请求,因为所需的所有输入张量都已就绪。
- 识别内部请求的完成,收集输出张量并将内容映射到“预处理图像”,这是集成中已知的唯一名称。
- 将新收集的张量映射到集合中模型的输入。在这种情况下,“classification_model”和“segmentation_model”的输入将被映射并标记为就绪。
- 检查需要新收集的张量的模型,并向输入就绪的模型发送内部请求,在本例中是分类模型和分割模型。请注意,响应将根据各个模型的负载和计算时间以任意顺序排列。
- 重复步骤 3-5,直到不再发送内部请求,然后用集成输出名称的张量去响应推理请求。
- 使用 image_prepoecess_model 模型,将原始图像处理成preprocessed_image 数据;
- 将 preprocessed_image 数据传递给 classification_model 模型,执行图像分类推理,最终返回“CLASSIFICATION”结果;
- 将 preprocessed_image 数据传递给 segmentation_model 模型,执行语义分割推理计算,最终返回“SEGMENTATION”结果;
- 支持一个或多个模型的流水线以及这些模型之间输入和输出张量的连接;
- 处理多个模型的模型拼接或数据流,例如“数据处理->推理->数据后处理”等;
- 收集每个步骤中的输出张量,并根据规范将其作为其他步骤的输入张量;
- 所集成的模型能继承所涉及模型的特征,在请求方的元数据必须符合集成中的模型;
- 在模型仓里为流水线创建一个新的“组合模型”文件夹,例如为“ensemble_model”;
- 在目路下创建新的 config.pbtxt,并且使用“platform: "ensemble"”来定义这个模型要执行集成功能;
- 定义集成模型:
name:"ensemble_model"
platform: "ensemble"
max_batch_size: 1
input [
{
name: "IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "CLASSIFICATION"
data_type: TYPE_FP32
dims: [ 1000 ]
},
{
name: "SEGMENTATION"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
从这个内容中可以看出,Triton 服务器将这个集成模型视为一个独立模型。
4. 定义模型的集成调度器:这部分使用“ensemble_scheduling”来调动集成调度器,将使用到模型与数据形成完整的交互关系。
在上面示例图中,灰色区块所形成的工作流水线中,使用到 image_prepoecess_model、classification_model、segmentation_model 三个模型,以及 preprocessed_image 数据在模型中进行传递。
下面提供这部分的范例配置内容,一开始使用“ensemble_scheduling”来调用集成调度器,里面再用“step”来定义模组之间的执行关系,透过模型的“input_map”与“output_map”的“key:value”对的方式,串联起模型之间的交互动作:
ensemble_scheduling{
step [
{
model_name: "image_preprocess_model"
model_version: -1
input_map {
key: "RAW_IMAGE"
value: "IMAGE"
}
output_map {
key: "PREPROCESSED_OUTPUT"
value: "preprocessed_image"
}
},
{
model_name: "classification_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "CLASSIFICATION_OUTPUT"
value: "CLASSIFICATION"
}
},
{
model_name: "segmentation_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "SEGMENTATION_OUTPUT"
value: "SEGMENTATION"
}
}
]
}
这里简单说明一下工作流程:
(1) 模型 image_preprocess_model 接收外部输入的 IMAGE 数据,进行图像预处理任务,输出 preprocessed_image 数据;(2) 模型 classification_model 的输入为 preprocessed_image,表示这个模型的工作是在 image_preprocess_model 之后的任务,执行的推理输出为 CLASSIFICATION;(3) 模型 segmentation_model 的输入为 preprocessed_image,表示这个模型的工作是在 image_preprocess_model 之后的任务,执行的退输出为 SEGMENTATION;(4) 上面两步骤可以看出 classification_model 与 segmentation_model 属于分支的同级模型,与上面工作流图中的要求一致。
完成以上的步骤,就能用集成模型与集成调度器的搭配,来创建一个完整的推理工作流任务,相当简单。
不过这类集成模型中,还有以下几个需要注意的重点:
- 这是 Triton 服务器用来执行用户定义模型流水线的抽象形式,由于没有与集成模型关联的物理实例,因此不能为其指定 instance_group 字段;
- 不过集成模型内容所组成的个别模型(例如image_preprocess_model),可以在其配置文件中指定 instance_group,并在集成接收到多个请求时单独支持并行执行。
- 由于集成模型将继承所涉及模型的特性,因此在请求起点的元数据(本例为“IMAGE”)必须符合集成中的模型,如果其中一个模型是有状态模型,那么集成模型的推理请求应该包含有状态模型中提到的信息,这些信息将由调度器提供给有状态模型。
原文标题:NVIDIA Triton 系列文章(13):模型与调度器-3
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
英伟达
+关注
关注
23文章
4041浏览量
97689
原文标题:NVIDIA Triton 系列文章(13):模型与调度器-3
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
面向科学仿真的开放模型系列NVIDIA Apollo正式发布
用于加速工业和计算工程的开放模型系列 NVIDIA Apollo 于近日举行的 SC25 大会上正式发布。
NVIDIA ACE现已支持开源Qwen3-8B小语言模型
为助力打造实时、动态的 NPC 游戏角色,NVIDIA ACE 现已支持开源 Qwen3-8B 小语言模型(SLM),可实现 PC 游戏中的本地部署。
NVIDIA Nemotron Nano 2推理模型发布
NVIDIA 正式推出准确、高效的混合 Mamba-Transformer 推理模型系列 NVIDIA Nemotron Nano 2。

使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践
针对基于 Diffusion 和 LLM 类别的 TTS 模型,NVIDIA Triton 和 TensorRT-LLM 方案能显著提升推理速度。在单张 NVIDIA Ada Love

NVIDIA RTX 5880 Ada与Qwen3系列模型实测报告
近日,阿里巴巴通义千问团队正式推出新一代开源大语言模型——Qwen3 系列,该系列包含 6 款 Dense 稠密模型和 2 款 MoE 混合
NVIDIA使用Qwen3系列模型的最佳实践
阿里巴巴近期发布了其开源的混合推理大语言模型 (LLM) 通义千问 Qwen3,此次 Qwen3 开源模型系列包含两款混合专家

英伟达GTC25亮点:NVIDIA Dynamo开源库加速并扩展AI推理模型
Triton 推理服务器的后续产品,NVIDIA Dynamo 是一款全新的 AI 推理服务软件,旨在为部署推理 AI 模型的 AI 工厂最大化其 token 收益。它协调并加速数千
NVIDIA推出开放式Llama Nemotron系列模型
作为 NVIDIA NIM 微服务,开放式 Llama Nemotron 大语言模型和 Cosmos Nemotron 视觉语言模型可在任何加速系统上为 AI 智能体提供强效助力。
Triton编译器与GPU编程的结合应用
Triton编译器简介 Triton编译器是一种针对并行计算优化的编译器,它能够自动将高级语言代码转换为针对特定硬件优化的低级代码。
Triton编译器的优化技巧
在现代计算环境中,编译器的性能对于软件的运行效率至关重要。Triton 编译器作为一个先进的编译器框架,提供了一系列的优化技术,以确保生成的
Triton编译器的优势与劣势分析
Triton编译器作为一种新兴的深度学习编译器,具有一系列显著的优势,同时也存在一些潜在的劣势。以下是对Triton编译
Triton编译器支持的编程语言
Triton编译器支持的编程语言主要包括以下几种: 一、主要编程语言 Python :Triton编译器通过Python接口提供了对Triton
Triton编译器与其他编译器的比较
Triton编译器与其他编译器的比较主要体现在以下几个方面: 一、定位与目标 Triton编译器 : 定位:专注于深度学习中最核心、最耗时的
Triton编译器功能介绍 Triton编译器使用教程
Triton 是一个开源的编译器前端,它支持多种编程语言,包括 C、C++、Fortran 和 Ada。Triton 旨在提供一个可扩展和可定制的编译器框架,允许开发者添加新的编程语言





 工商网监
工商网监
评论