 国内最大自动驾驶智算中心发布,为何车企纷纷自建智算中心?
国内最大自动驾驶智算中心发布,为何车企纷纷自建智算中心?

电子发烧友网报道(文/李弯弯)前不久,毫末智行与火山引擎共同发布了中国自动驾驶行业最大的智算中心——毫末“雪湖·绿洲”(MANA OASIS)。据毫末智行CEO顾维灏介绍,MANA OASIS的算力高达67亿亿次/秒,存储带宽可达2T/秒,通信带宽达到800G/秒,可以为自动驾驶技术的持续迭代提供充足动力。
不仅仅是自动驾驶车自身算力,智算中心也成为车企和自动驾驶公司竞争的焦点。众所周知,自动驾驶行业的领军企业特斯拉在几年前就已经建立自己的智算中心,并且还自研芯片以提升效率。国内除了毫末智行,小鹏汽车在今年8月也宣布已经建成自动驾驶智算中心。
多方面优化,MANA OASIS训练效率提升100倍
结合自动驾驶近十年的发展历史,毫末智行认为,可以将近十年的自动驾驶技术发展分成三个阶段:最早的硬件驱动方式,可以称为自动驾驶的1.0时代;最近几年的软件驱动方式,可称之为自动驾驶的2.0时代;即将发生,并将持续发展的数据驱动方式,是自动驾驶的3.0时代。数据驱动也是自动驾驶发展公认的方向,而它对智算中心的要求很高。
因此毫末和火山引擎共同定制了一个属于自动驾驶的智算中心。具体来看,在系统架构方面,如下图,左边是高性能存储,基于高性能并行文件系统VePFS,可以提供高达2T/s的读取速度,并且支持百亿级小文件高速读写。右边是计算平台,提供了充沛的算力,每台服务器配置8个GPU卡,通过600G/s的双向NVSwitch高速互联,进行通信。服务器之间通过4张200G带宽的RDMA网络互联,提供高达800G/s的网络带宽。
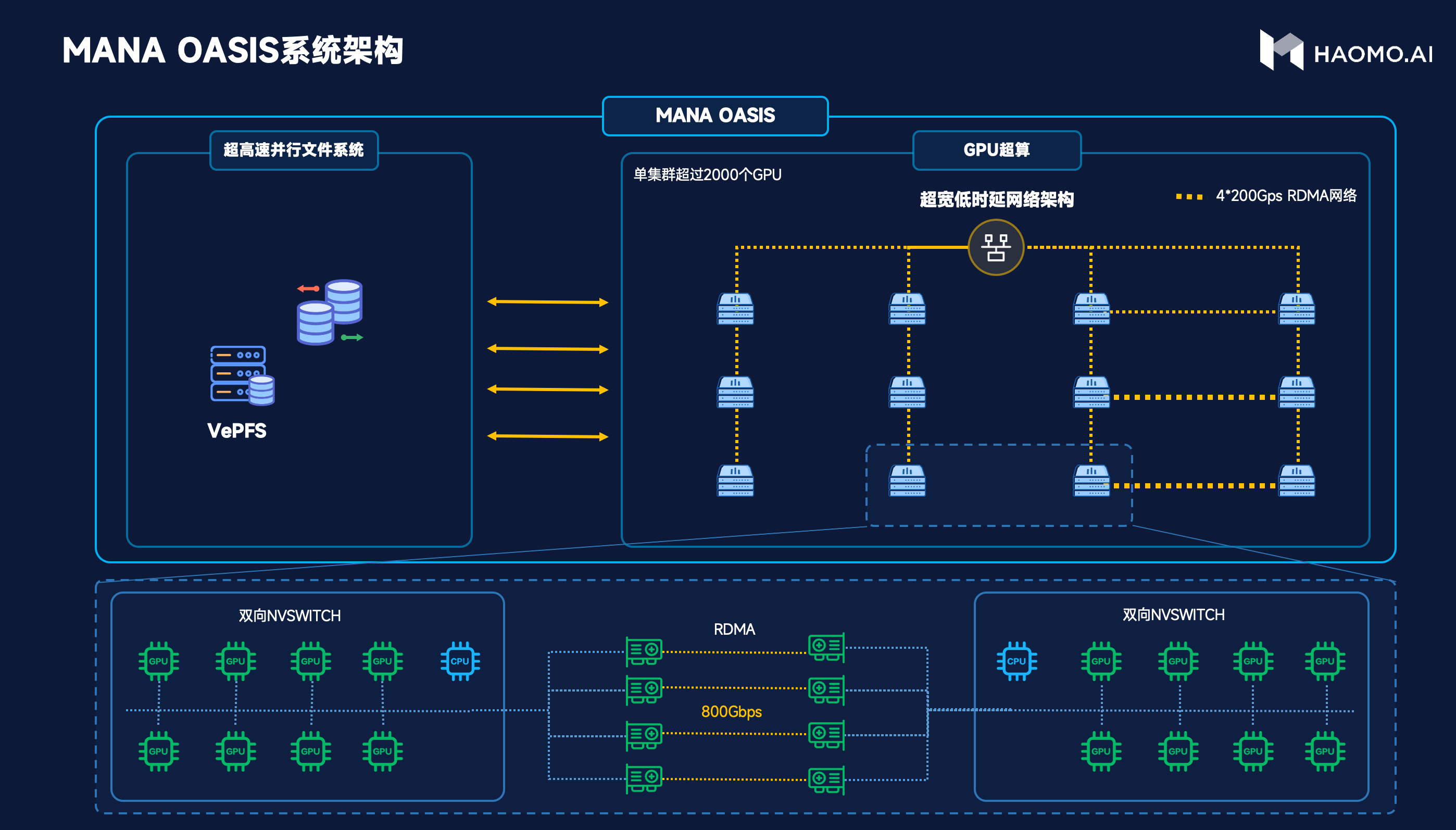
在数据管理上,为了充分发挥智算中心的价值,让GPU持续饱和运行,毫末经过2年多研发,建立了全套面向大规模AI训练的毫末文件系统。在采集端,把数据按照训练的要求,以4D Clip为单位组织文件形态;在传输端,基于毫末场景库,对数据进行场景化分析,打上各类Tag,方便模型基于Tag从不同维度对数据进行采样、分布统计、语料提取;在训练端,基于分级存储理念,把对象存储、高性能、显存充分整合,实现高容量与高性能并存。
最终实现了百P数据筛选速度提升10倍、百亿小文件随机读写延迟小于500us。在毫末文件系统的加持下,消除数据瓶颈,GPU利用率从60%提升到接近80%。
在MANA OASIS的训练加速上也做了大量优化。大家都知道,transformer大模型的训练成本非常高,训练一个大模型有时成本高达几千万。毫末在此方向深入研究,借鉴了学术界最新的研究成果,基于Sparse MoE,可以根据计算特点,进行稀疏激活,提高计算效率,实现单机8卡就能训练百亿参数大模型的效果。
毫末智算中心也实现了跨机共享expert的方法,完成千亿参数规模大模型的训练,而且训练成本降低到百卡周级别。在此基础上,毫末基于自己的业务特点,设计并实现了业界领先的多任务并行训练系统,能同时处理图片、点云、结构化文本等多种模态的信息,既保证了模型的稀疏性,又提升了计算效率。结合多方面的优化,毫末智算中心的训练效率提升了100倍。
为何小鹏、特斯拉等车企要建立自己的智算中心
除了毫末智行,小鹏汽车、特斯拉等车企也已建设自己的智算中心。今年8月,小鹏汽车宣布在乌兰察布建成当时中国最大的自动驾驶智算中心“扶摇”,用于自动驾驶模型训练。“扶摇”基于阿里云智能计算平台,算力可达600PFLOPS(每秒浮点运算60亿亿次),将小鹏自动驾驶核心模型的训练速度提升了近170倍。
通过与阿里云合作,“扶摇”以更低成本实现了更强算力。具体来看,对GPU资源进行细粒度切分、调度,将GPU资源虚拟化利用率提高3倍,支持更多人同时在线开发,效率提升十倍以上。在通讯层面,端对端通信延迟降低80%至2微秒。
整体计算效率上,实现了算力的线性扩展。存储吞吐比业界20GB/s的普遍水准提升了40倍,数据传输能力相当于从送快递的微型面包车,换成了20多米长的40吨集装箱重卡。此外,阿里云机器学习平台PAI提供了模型训练部署、推理优化等AI工程化工具,比开源框架训练性能提升30%以上。
“扶摇”支持小鹏自动驾驶核心模型的训练时长从7天,缩短至1小时内,大幅提速近170倍。据介绍,“扶摇”正用于小鹏城市NGP辅助驾驶系统的算法模型训练。和高速道路相比,城市路段的交通状况更为复杂,自动驾驶特殊场景的数据集规模增加了上百倍。
早几年前,特斯拉就已经建立了自己的AI计算中心——Dojo,总计使用了1.4万个英伟达的GPU来训练AI模型。为了进一步提升效率,特斯拉在2021年发布了自研的AI加速芯片D1,25个D1封装在一起组成一个训练模块(Training tile),然后再将训练模块组成一个机柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI计算中心的最新进展,用自研的D1芯片打造的计算设备能够提升30%的模型训练效率。
可以看到,车企和自动驾驶公司自建智算中心,能够在性能上进行多方面的优化,提升效率。此外在成本上也会更有利,何小鹏此前谈到,对于智能汽车公司来说,算力成本将会从今天的亿元级别上升到将来的十亿元级别。因此,如果持续使用公有云服务,边际成本将会不断上涨。如果自行组建智算中心,一次性投资约在数千万到1亿元以内,长期来看性价比更高。
不仅仅是自动驾驶车自身算力,智算中心也成为车企和自动驾驶公司竞争的焦点。众所周知,自动驾驶行业的领军企业特斯拉在几年前就已经建立自己的智算中心,并且还自研芯片以提升效率。国内除了毫末智行,小鹏汽车在今年8月也宣布已经建成自动驾驶智算中心。
多方面优化,MANA OASIS训练效率提升100倍
结合自动驾驶近十年的发展历史,毫末智行认为,可以将近十年的自动驾驶技术发展分成三个阶段:最早的硬件驱动方式,可以称为自动驾驶的1.0时代;最近几年的软件驱动方式,可称之为自动驾驶的2.0时代;即将发生,并将持续发展的数据驱动方式,是自动驾驶的3.0时代。数据驱动也是自动驾驶发展公认的方向,而它对智算中心的要求很高。
因此毫末和火山引擎共同定制了一个属于自动驾驶的智算中心。具体来看,在系统架构方面,如下图,左边是高性能存储,基于高性能并行文件系统VePFS,可以提供高达2T/s的读取速度,并且支持百亿级小文件高速读写。右边是计算平台,提供了充沛的算力,每台服务器配置8个GPU卡,通过600G/s的双向NVSwitch高速互联,进行通信。服务器之间通过4张200G带宽的RDMA网络互联,提供高达800G/s的网络带宽。
在数据管理上,为了充分发挥智算中心的价值,让GPU持续饱和运行,毫末经过2年多研发,建立了全套面向大规模AI训练的毫末文件系统。在采集端,把数据按照训练的要求,以4D Clip为单位组织文件形态;在传输端,基于毫末场景库,对数据进行场景化分析,打上各类Tag,方便模型基于Tag从不同维度对数据进行采样、分布统计、语料提取;在训练端,基于分级存储理念,把对象存储、高性能、显存充分整合,实现高容量与高性能并存。
最终实现了百P数据筛选速度提升10倍、百亿小文件随机读写延迟小于500us。在毫末文件系统的加持下,消除数据瓶颈,GPU利用率从60%提升到接近80%。
在MANA OASIS的训练加速上也做了大量优化。大家都知道,transformer大模型的训练成本非常高,训练一个大模型有时成本高达几千万。毫末在此方向深入研究,借鉴了学术界最新的研究成果,基于Sparse MoE,可以根据计算特点,进行稀疏激活,提高计算效率,实现单机8卡就能训练百亿参数大模型的效果。
毫末智算中心也实现了跨机共享expert的方法,完成千亿参数规模大模型的训练,而且训练成本降低到百卡周级别。在此基础上,毫末基于自己的业务特点,设计并实现了业界领先的多任务并行训练系统,能同时处理图片、点云、结构化文本等多种模态的信息,既保证了模型的稀疏性,又提升了计算效率。结合多方面的优化,毫末智算中心的训练效率提升了100倍。
为何小鹏、特斯拉等车企要建立自己的智算中心
除了毫末智行,小鹏汽车、特斯拉等车企也已建设自己的智算中心。今年8月,小鹏汽车宣布在乌兰察布建成当时中国最大的自动驾驶智算中心“扶摇”,用于自动驾驶模型训练。“扶摇”基于阿里云智能计算平台,算力可达600PFLOPS(每秒浮点运算60亿亿次),将小鹏自动驾驶核心模型的训练速度提升了近170倍。
通过与阿里云合作,“扶摇”以更低成本实现了更强算力。具体来看,对GPU资源进行细粒度切分、调度,将GPU资源虚拟化利用率提高3倍,支持更多人同时在线开发,效率提升十倍以上。在通讯层面,端对端通信延迟降低80%至2微秒。
整体计算效率上,实现了算力的线性扩展。存储吞吐比业界20GB/s的普遍水准提升了40倍,数据传输能力相当于从送快递的微型面包车,换成了20多米长的40吨集装箱重卡。此外,阿里云机器学习平台PAI提供了模型训练部署、推理优化等AI工程化工具,比开源框架训练性能提升30%以上。
“扶摇”支持小鹏自动驾驶核心模型的训练时长从7天,缩短至1小时内,大幅提速近170倍。据介绍,“扶摇”正用于小鹏城市NGP辅助驾驶系统的算法模型训练。和高速道路相比,城市路段的交通状况更为复杂,自动驾驶特殊场景的数据集规模增加了上百倍。
早几年前,特斯拉就已经建立了自己的AI计算中心——Dojo,总计使用了1.4万个英伟达的GPU来训练AI模型。为了进一步提升效率,特斯拉在2021年发布了自研的AI加速芯片D1,25个D1封装在一起组成一个训练模块(Training tile),然后再将训练模块组成一个机柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI计算中心的最新进展,用自研的D1芯片打造的计算设备能够提升30%的模型训练效率。
可以看到,车企和自动驾驶公司自建智算中心,能够在性能上进行多方面的优化,提升效率。此外在成本上也会更有利,何小鹏此前谈到,对于智能汽车公司来说,算力成本将会从今天的亿元级别上升到将来的十亿元级别。因此,如果持续使用公有云服务,边际成本将会不断上涨。如果自行组建智算中心,一次性投资约在数千万到1亿元以内,长期来看性价比更高。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
自动驾驶
+关注
关注
794文章
14988浏览量
181544 -
智算中心
+关注
关注
0文章
123浏览量
2602
发布评论请先 登录
相关推荐
热点推荐
华为星河AI高算效数据中心网络为安康智算中心注入强劲增长动能
抢抓“东数西算”战略机遇,陕西安康正以智算基础设施建设为抓手,激活数字经济发展新动能。陕西智算云谷科技有限公司成立于2023年。公司聚焦打造陕西第一、全国领先的人工智能计算中心(安康智
自动驾驶摄像头像素如何影响算力?
[首发于智驾最前沿微信公众号]之前和大家聊过一个话题,那就是激光雷达线束对算力的影响。摄像头作为自动驾驶非常关键的另一个感知硬件,其像素大小是否会影响算力消耗? 其实从早期的1.2兆像素(1.2MP

贸泽电子自动驾驶汽车在线资源中心助力解决实际部署面临的各项挑战
自动驾驶技术的系统架构与设计限制。本资源中心探讨传感技术、车载网络以及车联网 (V2X) 通信如何为实时决策系统提供数据支持,并阐明为何安全防护、网络安全以及伦理边界案例,正逐渐成为定
智算中心弹性扩容与风液混合制冷架构避坑指南
随着人工智能技术的爆发式增长,智算中心作为支撑AI模型训练与推理的核心基础设施,其建设逻辑正在发生深刻变革。维谛技术(Vertiv)作为全球领先的数字基础设施保障专家,致力于为全球智算中心
算力越高,自动驾驶汽车就会越聪明?
在自动驾驶行业,说起算力,很多人第一反应是“更强就是更好”,更快的芯片、更大的算力池,感觉就可以让汽车能看得更清楚、做决定更快、更安全。但事实并非如此。对于自动驾驶汽车来说,算力确实重
智能算力为何必须先进存力
作为东数西算战略的关键枢纽,中国移动呼和浩特数据中心不仅是中国移动“4+N+31+X”算力网络中规模最大、技术最先进、保障最完备的中心节点,
车与车之间的群体智能会成为自动驾驶的未来吗?
在自动驾驶的发展过程中,人们最常提到的是“单车智能”。意思就是,车辆依靠自己的摄像头、雷达、算法和算力去感知环境、做出决策、完成驾驶。但单车智能能力有限,光靠一辆车“单打独斗”,必然会
算力赋能未来:自动驾驶如何从科幻驶入现实?
当一辆汽车以120km/h飞驰时,每0.1秒的决策延迟就意味着3.3米的“生死距离”。而现在,自动驾驶车辆能在毫秒间完成刹车、变道甚至紧急避障——这背后,是算力在无声地重塑人类出行方式。感知系统

为什么自动驾驶企业认准它做 “算力心脏”?智锐通 MM3080Ti MXM 显卡用实力说话
智锐通 MM3080TIB6-16G MXM 显卡凭借 “高性能、小尺寸、高可靠” 的核心优势,为该自动驾驶企业解决了嵌入式场景下的算力适配难题,也为行业提供了 “场景化算力硬件” 的参考方向。

自动驾驶系统的算力越高就越好吗?
[首发于智驾最前沿微信公众号]自动驾驶系统的“算力”是指车载计算平台中用于执行感知、决策、规划和控制等算法的硬件性能指标。之前给大家分享了算力的概念及作用,从概念上看,算力越强大,就意
施耐德电气Galaxy VXL UPS助力智算中心发展
随着智算中心处理数据的规模不断攀升,其物理基础关键设施所经受的考验也日益严峻,空间之困、功率之压、散热之危、可用之艰、AI之难、运维之繁......,面对智算中心发展中的重重难关,基础
华为数据中心自动驾驶网络通过EANTC欧洲高级网络测试中心L4级自智网络测评
Networking Test Center,简称“EANTC”)发布华为数据中心自动驾驶网络的自智网络(Autonomous Network,简称“AN”)分级测评结果。此次测评结果显示,华为

新能源车软件单元测试深度解析:自动驾驶系统视角
的潜在风险增加,尤其是在自动驾驶等安全关键系统中。根据ISO 26262标准,自动驾驶系统的安全完整性等级(ASIL-D)要求单点故障率必须低于10^-8/小时,这意味着每小时的故障概率需控制在亿
发表于 05-12 15:59
AI将如何改变自动驾驶?
[首发于智驾最前沿微信公众号]五一假期继续闲聊一下,还欢迎大家随意留言,随着人工智能(AI)的发展,很多车企及自动驾驶供应商正尝试将AI融入自动驾驶系统,为何大家都在积极推动这一技术?



评论