 百度智算峰会精彩回顾:应用驱动的数据中心计算架构演进
百度智算峰会精彩回顾:应用驱动的数据中心计算架构演进

在今日举行的“2022 百度云智峰会·智算峰会”上,NVIDIA 解决方案工程中心高级技术经理路川分享了以“应用驱动的数据中心计算架构演进”为题的演讲,探讨 GPU 数据中心的发展趋势,以及介绍 NVIDIA 在构建以 GPU 为基础的数据中心架构方面的实践经验。以下为内容概要。
应用对算力需求的不断增长
以 GPU 为核心的分布式计算系统已经成为大模型应用重要的一环
数据中心的发展是由应用驱动的。随着 AI 的兴起、普及,AI 大模型训练在各领域的逐步应用,人们对数据中心的 GPU 算力、GPU 集群的需求在飞速增长。传统的以 CPU 为基础的数据中心架构,已很难满足 AI 应用的发展需求,NVIDIA 也一直在探索如何构建一个高效的以 GPU 为基础的数据中心架构。
今天我将从三个方面跟大家一起探讨这个话题:一,应用驱动;二,NVIDIA 最新一代 GPU SuperPOD 的架构设计;三,未来 GPU 数据中心、GPU 集群的发展趋势 。
我们首先看下近几年 AI 应用的发展趋势。总体上来讲,应用业务对计算的需求是不断飞速增长。我们以目前最流行的三个业务方向为例说明。

第一个应用场景,AI 应用。我们可以从最左边的图表中可以看到,近 10 年 CV 和 NLP 模型的变化,这两类业务场景是 AI 领域最流行、最成功,也是应用范围最为广泛的场景。在图表中我们可以看到,CV 从 2012 年的 AlexNet 到最新的 wav2vec,模型对计算的需求增长了 1,000 倍。
NLP 模型在引入 Transformer 结构后,模型规模呈指数级增长,Transformer 已成为大模型、大算力的代名词。目前 CV 类的应用也逐步引入 Transformer 结构来构建相关的 AI 模型,不断提升应用性能。数据显示在最近两年内关于 Transformer AI 模型的论文增长了 150 倍,而非 Transformer 结构的 AI 模型相关论文增长了大概 8 倍。
我们可以看到人们越来越意识到大模型在 AI 领域的重要性,和对应用带来的收益。同时大模型也意味着算力的需求的增长,以及对数据中心计算集群需求的增长。
第二个应用场景,数字孪生、虚拟人等模拟场景与 AI 的结合也是最近两年的应用热点。人们通过数字孪生、虚拟人可以更好地对企业生产流程进行管控,线上虚拟交互有更好的体验,这背后都需要要巨大的算力资源来满足渲染、实时交互等功能。
第三个应用场景,量子计算,也是最近几年我们计算热点的技术。量子计算是利用量子力学,可以比传统的计算机更快地解决复杂的问题。量子计算机的发展还处在非常前期的阶段,相关的量子算法的研究和应用也需要大量的算力做模拟支撑。
前面我们提到了 AI 大模型的业务应用,为什么要用到大模型,大模型可以给我们带来什么样的收益?
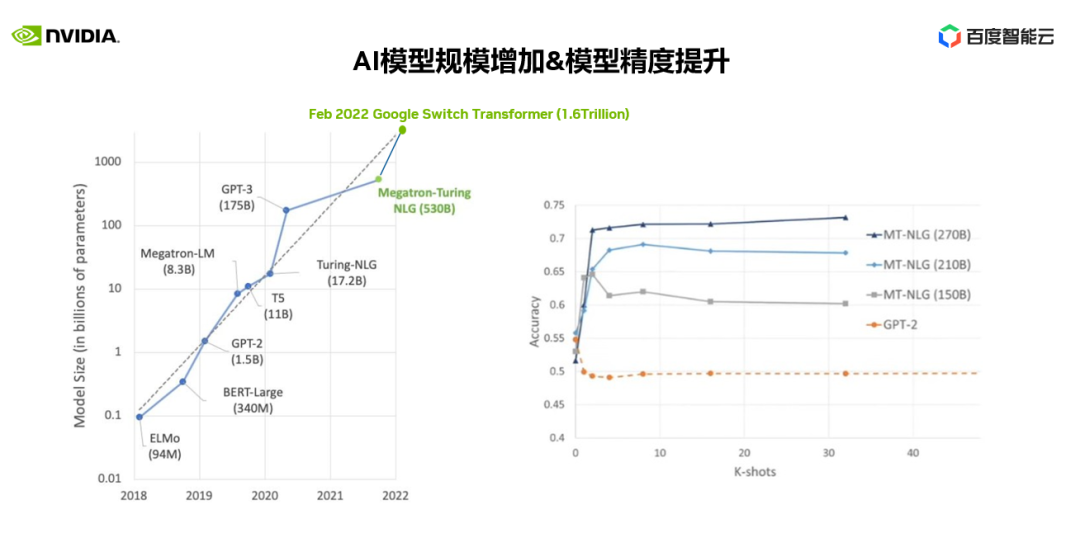
在右图中我们可以看到 1.5B GPT-2 和 MT-NLG 在 150B-270B 不同参数规模下对应用精度的影响。
我们可以清楚地看到大模型对应用精度的效果,尤其是对复杂、泛化的业务场景的表现尤为突出。同时大模型在预测(inference)端正在快速发展,优化特定场景、特定行业的性能,优化预测端计算资源使用等,相信在不久的将来会有更多像 ChatGPT 一样令人惊叹的应用在行业落地。这都将会推动大模型基础研究,推动对训练大模型所需算力的建设。一个以 GPU 为基础的分布式计算系统也是大模型应用所必须的。
AI 大模型训练为什么要用到 GPU 集群,用到更大规模的 GPU?它能给我们的训练带来什么样的收益?这边我们用两个实际的例子作为参考。
一个应用是 BERT 340M 参数规模,使用 Selene A100 SuperPOD 集群,训练完成则需要 0.2 分钟,在使用 1/2 个集群规模,训练完成需要 0.4 分钟,使用 1/4 个集群规模下训练完成则需要 0.7 分钟。我们可以看到在小参数规模下,使用几十台 DGX A100 也可以快速完成整个训练任务,对于整个训练的迭代影响并不大。
另一个是 Megatron 530B 参数规模的 NLP 大模型,训练这个 530B 参数的大模型,使用整个 Selene SuperPOD 集群资源则需要 3.5 周、近一个月的时间才能完成,而使用 1/2、1/4 集群节点规模的情况下,则需要数月的训练时间才能完成整个训练,这对于大模型研发人员来说是不可接受的。另外研发人员的时间成本是非常宝贵的,研究到产品化的时间也是非常关键的,我们不可能把时间浪费在训练等待上。
在管理层面,构建一个 GPU 集群,通过集群的作业调度和管理系统,可以优化调度各种类型、各种需求的 GPU 任务,使用集群的 GPU 资源,以最大化利用 GPU 集群。在 Facebook 的一篇论文中提到,通过作业调度管理系统,Facebook AI 超级计算系统上每天可以承载 3.5 万个独立的训练任务。
因此,GPU 规模和集群管理对于提升分布式任务的运行效率非常关键。
集群的最关键的地方就是通信,集群任务的调试优化重点也是在使用各种并行方式优化通信策略。在 GPU 集群中,通信主要分为两个部分,一个是节点内通信,一个是节点间通信。
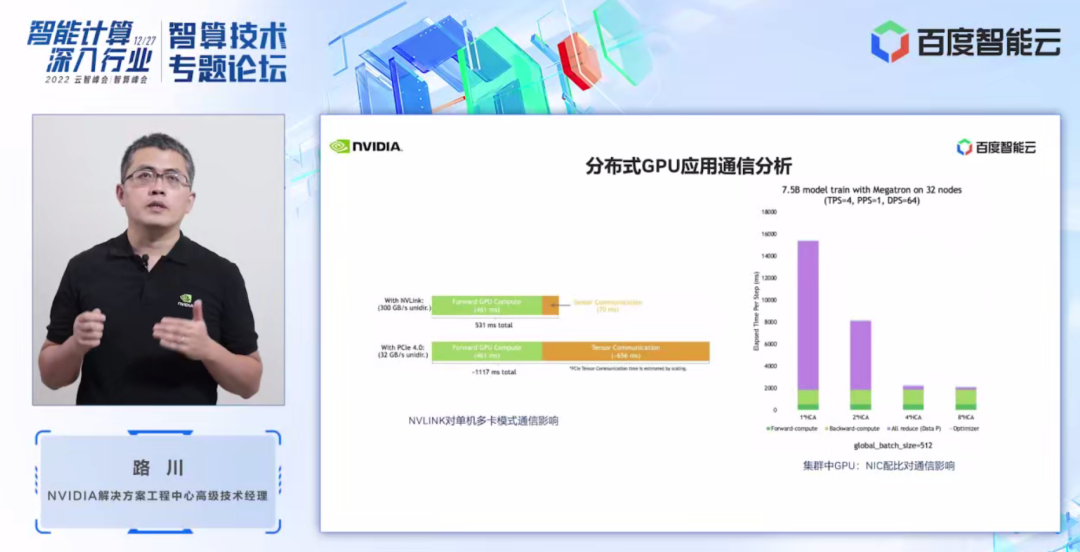
在左图中我们可以看到节点间通信 NVLink 对于它的重要性。图中示例使用 tensor 并行的方式,在节点间分别采用 NVLink 和采用 PCIe 4.0 进行通信的对比,我们可以看到,NVLink 环境下程序的通信时间仅需 70ms(毫秒),而 PCIe 环境下通信时间则需要 656ms,当用多个节点组成的集群环境下差距会更加明显。
在右图中,我们使用 7.5B 的 AI 模型,采用 TPS=4,PPS=1,数据并行 DPS=64 的情况下,在 32 个集群的节点规模下,不同网卡对分布式训练任务的影响。紫色部分代表了通信占比,绿色代表计算时间占比。我们可以清晰地看到网卡数量、网络带宽对分布式应用的性能的影响。
GPU 集群应用于 AI 训练也是最近几年才逐步在客户中开始应用。在 AI 发展的早期,模型较小,大部分采单机多卡或是多机数据并行的方式进行训练,所以对 GPU 集群的要求并不是很高。2018 年 11 月,NVIDIA 第一次推出基于 DGX-2 的 SuperPOD 架构,也是看到 AI 发展的趋势,看到了 AI 应用对 GPU 分布式集群在 AI 训练中的需求。
SuperPOD 的架构也在不断地演进和优化。通过 NVIDIA 实战经验和性能优化验证,SuperPOD 可以帮助客户迅速构建起属于自己的高性能 GPU 分布式集群。
NVIDIA 最新一代 Hopper GPU 架构下 SuperPod 的集群拓扑
下面我来简单介绍下,最新一代 Hopper GPU 架构下 SuperPOD 的集群拓扑。
计算节点采用 Hopper 最新的 GPU,相比较与 Ampere GPU 性能提升 2~3 倍。计算性能的提升需要更强的网络带宽来支撑,所以外部的网络也由原来的 200Gb 升级为 400Gb,400Gb 的网络交换机可以最多支撑到 64 个 400Gb 网口,所以每个计算 POD 由原来的 20 个变为 32 个。更高的计算密度,在一个 POD 内 GPU 直接的通信效率要更高。
NDR Infiniband 网络、AR、SHARP、SHIELD 等新的特性,在路由交换效率、聚合通信加速、网络稳定性等方面有了进一步的提升,可以更好的支持分布式大规模 GPU 集群计算性能和稳定性。在存储和管理网络方面,增加了智能网卡的支持,可以提供更多的管理功能,适应不同客户的需求。
未来数据中心 GPU 集群架构的发展趋势:
计算、互联、软件
下面,站在 NVIDIA 的角度,我们再来探讨一下,未来数据中心 GPU 集群的架构发展趋势。整个 GPU 的集群主要有三个关键因素,分别是:计算、互联和软件。

一,计算。集群的架构设计中,单节点计算性能越高,越有优势,所以在 GPU 选择上我们会采用最新的 GPU 架构,这样会带来更强的 GPU 算力。
在未来两年,Hopper 将成为 GPU 分布式计算集群的主力 GPU。Hopper GPU 我相信大家已经很了解,相关特性我在这就不在赘述。我只强调一个功能,Transformer 引擎。
在上文应用的发展趋势里,我们也提到了以 Transformer 为基础的 AI 大模型的研究。Transformer 也是大模型分布式计算的代名词,在 Hopper 架构里新增加了 Transformer 引擎,就是专门为 Transformer 结构而设计的 GPU 加速单元,这会极大地加速基于 Transformer 结构的大模型训练效率。
二,互联。GPU 是 CPU 的加速器,集群计算的另外一个重要组成部分是 CPU。NVIDIA 会在 2023 年发布基于 Arm 72 核、专为高性能设计的 Grace CPU,配置 500GB/s LPDDR5X 内存,900GB/s NVLink, 可以跟 GPU 更好地配合,输出强大的计算性能。
基于 Grace CPU,会有两种形态的超级芯片,一是 Grace+Hopper,二是 Grace+Grace。
Grace+Hopper,我们知道 GPU 作为 CPU 加速器,并不是所有应用任务都适用于 GPU 来加速,其中很关键的一个点就是 GPU 和 CPU 之间的存储带宽的瓶颈,Grace+Hopper 超级芯片就是解决此类问题。
在 Grace Hopper 超级芯片架构下,GPU 可以通过高速的 NVLink 直接访问到 CPU 显存。对于大模型计算,更多应用迁移到GPU上加速都有极大的帮助。
Grace+Grace ,是在一个模组上可以提供高达 144 CPU 核,1 TB/s LPDDR5X 的高速存储,给集群节点提供了强劲的单节点的 CPU 计算性能,从而提升整个集群效率。
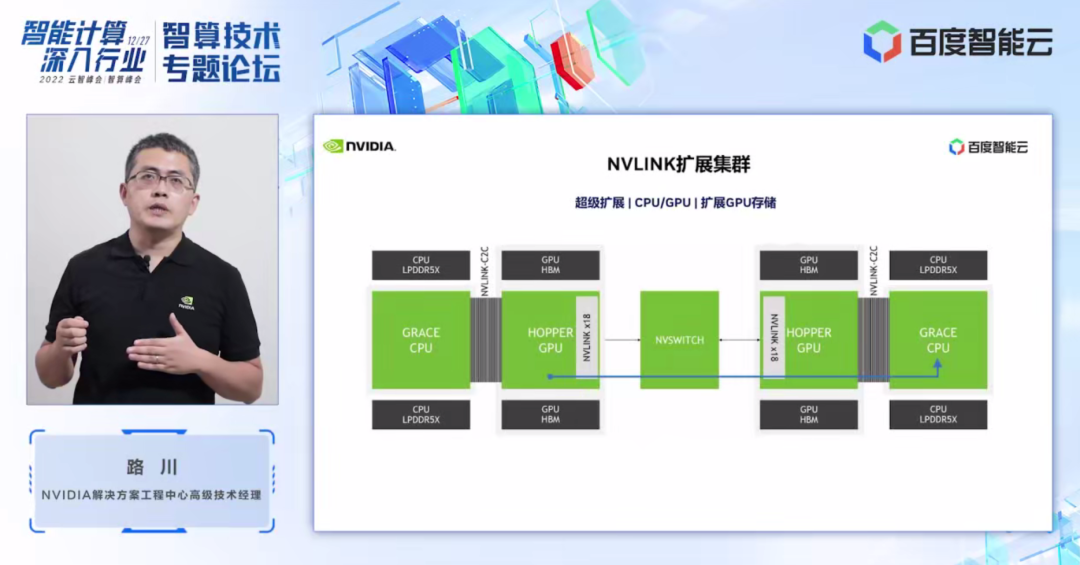
之前我们所熟知的 NVLink,都是应用在节点内 GPU 和 GPU 之间的互联。在 Grace Hopper 集群下,NVLink 可以做到节点之间互联,这样节点之间 GPU-GPU,或 GPU-CPU,或 CPU-CPU 之间,都可以通过高速的 NVLink 进行互联,可以更高效地完成大模型的分布式计算。
在未来也许我们可以看到更多业务应用迁移到 Grace+Hopper 架构下,节点之间的 NVLlink 高速互联也许会成为一个趋势,更好地支持 GPU 分布式计算。
智能网卡在集群中的应用,首先智能网卡技术并不是一个新的技术,各家也有各家的方案,传统上我们可以利用智能网卡把云业务场景下的 Hypervisor 管理、网络功能、存储功能等卸载到智能网卡上进行处理,这样可以给云客户提供一个云生的计算资源环境。NVIDIA 智能网卡跟百度也有很深的合作,包括 GPU 集群裸金属方案也都配置了 NVIDIA 智能网卡进行管理。
在非 GPU 的业务场景下,我们看到智能网卡对 HPC 应用业务的加速,主要是在分子动力学,气象和信号处理应用上,通过对集群中聚合通信的卸载,我们可以看到应用可以获得 20% 以上的收益。智能网卡技术也在不断更新、升级,业务场景也在不断探索。相信在未来的 GPU 集群上会有更多的业务或优化加速可以使用到智能网卡技术。
三,软件。数据中心基础设施是基础底座,如何能够更高效、快速、方便地应用到基础架构变革所带来的优势,软件生态的不断完善和优化是关键。
针对不同的业务场景,NVIDIA 提供了 SuperPOD、OVX 等数据中心基础设施的参考架构,可以帮助用户构建最优的数据中心基础设施架构。
上层提供了各种软件加速库,如 cuQuantum 可以帮助客户直接在 GPU 集群上模拟量子算法计算,Magnum IO 用来加速数据中心 GPU 集群和存储系统的访存 IO 效率,提升整个集群计算效率。
在未来会有更多的软件工具、行业 SDK,来支撑数据中心架构的使用,让各领域的研发人员不需要了解底层细节,更加方便、快速地使用到数据中心 GPU 集群的的最优性能。
原文标题:百度智算峰会精彩回顾:应用驱动的数据中心计算架构演进
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4047浏览量
97762
原文标题:百度智算峰会精彩回顾:应用驱动的数据中心计算架构演进
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Arm架构计算平台驱动融合型AI数据中心变革
48V电压在数据中心计算平台中至关重要
华为数字能源2025中东中亚数据中心创新峰会圆满召开
大冲能源亮相2025国际数据中心及云计算产业展览会
格灵深瞳精彩亮相百度世界2025大会
2025百度世界大会精彩回顾
华为数字能源亮相2025开放数据中心大会
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
华为面向拉美地区发布全新星河AI数据中心网络方案
明晚开播 | 数据智能系列讲座第6期:大模型革命背后的算力架构创新

适用于数据中心和AI时代的800G网络
优化800G数据中心:高速线缆、有源光缆和光纤跳线解决方案
数据中心发展与改造
智算中心会取代通用算力中心吗?






 工商网监
工商网监
评论