 介绍几篇EMNLP'22的语言模型训练方法优化工作
介绍几篇EMNLP'22的语言模型训练方法优化工作

来自:圆圆的算法笔记
今天给大家介绍3篇EMNLP 2022中语言模型训练方法优化的工作,这3篇工作分别是:
针对检索优化语言模型:优化语言模型训练过程,使能够生成更合适的句子表示用于检索——RetroMAE: Pre-training Retrieval-oriented Transformers via Masked Auto-Encoder;
针对事实知识提取优化语言模型:在语言模型训练过程中引入知识库,提升语言模型对事实知识的抽取能力——Pre-training Language Models with Deterministic Factual Knowledge;
针对目标域效果优化语言模型:将语言模型在目标domain继续训练,在不遗忘原始知识的情况下学到目标doman新知识——Continual Training of Language Models for Few-Shot Learning。
后台回复【语言模型】,可以获取14种深度学习语言模型的梳理资料。
1 针对检索优化语言模型
在query-document检索任务中,核心是获取到query和document的句子表征,然后利用向量检索的方式完成检索任务。BERT已经成为提取句子表示向量的主流方法。然而,BERT在预训练阶段的主要任务是MLM,缺少对句子整体表示提取的优化目标,导致句子表示提取能力不足。
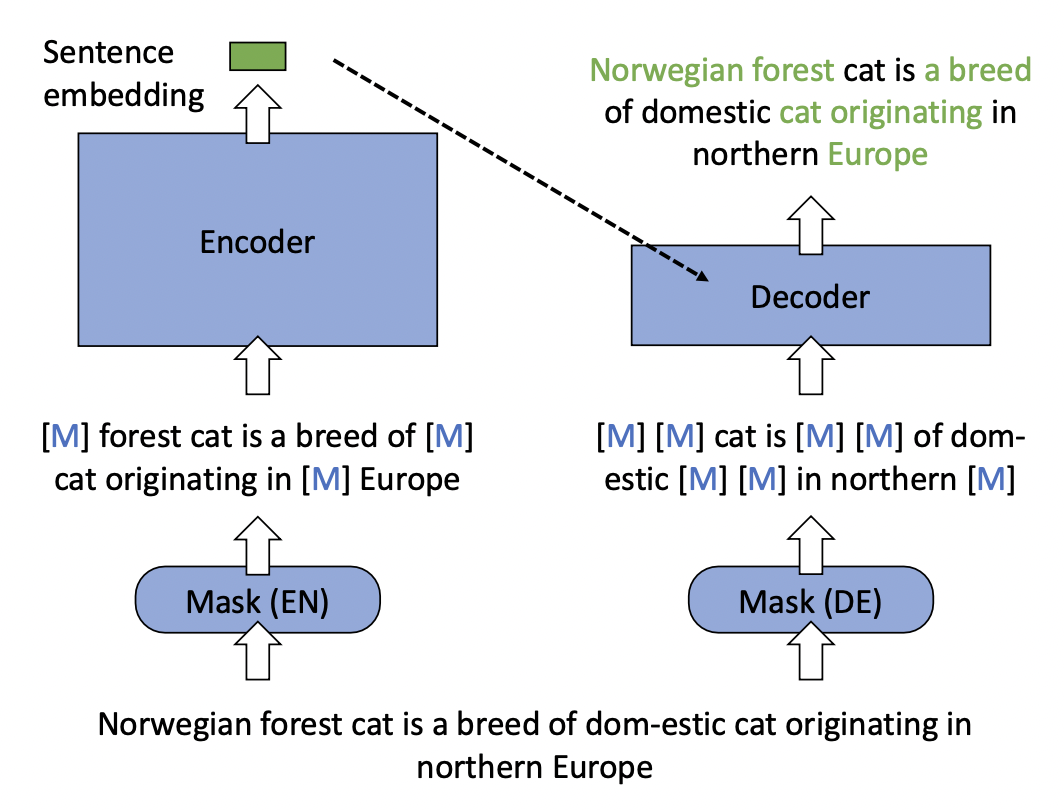
RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder这篇文章对BERT的训练方式进行了优化,使得BERT能提取更高质量的句子表示,进而提升检索效果。RetroMAE的整体结构如下图所示,包括一个Encoder和一个Decoder。对于每一个样本,Encoder的输入随机mask掉15%的token,和原始BERT类似,利用Encoder得到整体的句子表示。在Decoder侧,输入Encoder的句子表示,以及mask掉70%的token的样本,让Decoder还原整个句子。Encoder是一个比较复杂的BERT模型,Decoder则使用一个比较简单的单层Transformer模型。
本文的模型设计思路是,Decoder提供的信息尽可能少、模型的复杂度尽可能低,这样可以迫使Encoder生成的句子表示包含更完整的句子信息,保障了Encoder生成的句子embedding的质量。相比对比学习学习句子表示的方法,RetroMAE的优势是效果不依赖于数据增强方法和正负样本构造方法的选择。
2 针对事实知识提取优化语言模型
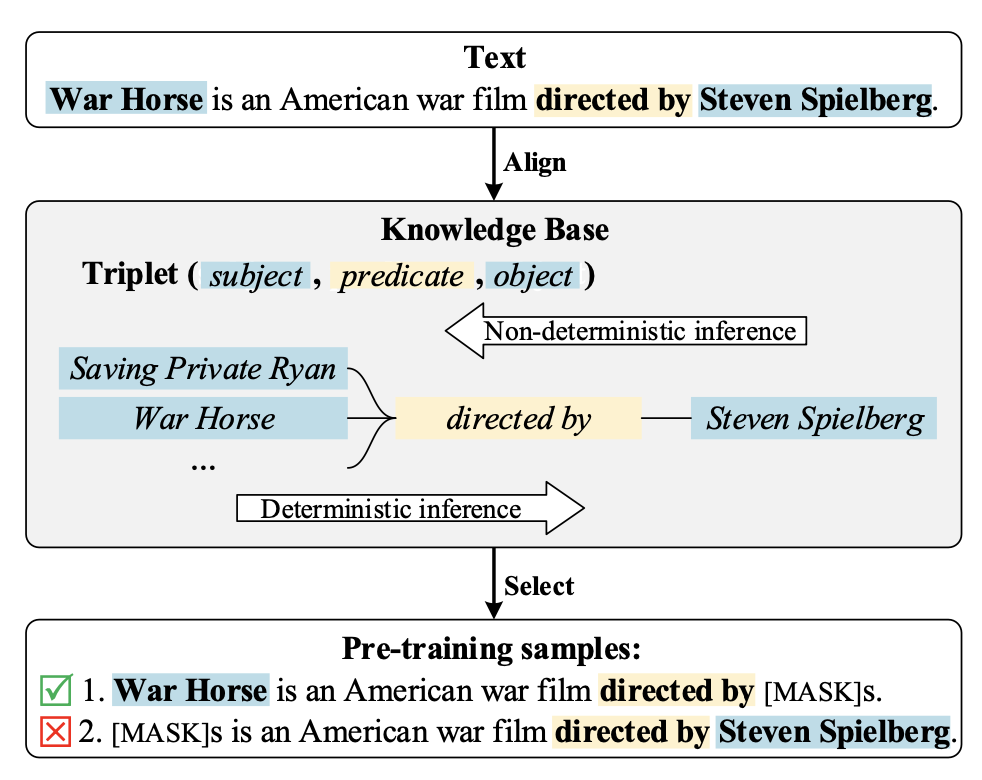
随着prompt的兴起,预训练语言模型经常被用于进行知识抽取。构造一个prompt模板,以完形填空的形式让模型预测空缺位置的token,实现知识抽取。然而,预训练语言模型的抽取结果有时会很大程度上受到prompt选择的影响,如下表所示,鲁棒性较差。一个核心原因是,在训练语言模型的过程中,有些被mask掉的部分并不一定只有唯一一个正确答案。当被mask部分存在多个正确答案,而模型在训练过程中被要求只预测一个正确答案时,就会导致其他本来正确的答案被强行设置成为负样本,进而影响了模型效果。

Pre-training Language Models with Deterministic Factual Knowledge针对这个问题,提出了在构造预训练样本时,引入知识库对数据进行过滤。核心是在KG中查找知识信息,看样本中被mask掉的实体是否这段文本的描述中唯一确定的正确答案。如果是,那么这个样本不会给语言模型带来歧义,正常参与训练;否则就是一个多答案样本,从训练数据中去除掉。通过这种数据过滤的方式,让模型在训练阶段见到的预测任务都是只有一个确定答案的,解决了多答案mask token预测的影响。
为了进一步提升模型能力,文中提出了Clue Contrastive Learning和Clue Classification两个任务。Clue Contrastive Learning的目标是让模型具备一种能力:当上下文指向的答案是确定性的时候,就预测一个更有信心一些。通过构造确定性样本和非确定性样本,以这对样本的对比关系进行学习。Clue Classification让语言模型知道上下文信息中存在什么样的线索。通过保留决定性线索、删除决定性线索、删除其他非决定性线性构造三种样本用于分类。
3 针对目标域效果优化语言模型
在使用预训练语言模型解决下游NLP任务时,如果目标任务的有label数据较少,一种能提升效果的方法是先将语言模型在目标任务domain上无监督语料上继续训练,让语言模型适应目标任务的文本分布。在面对下游各类、持续增加的任务时,我们需要不断的使用新任务domain的语言训练语言模型。这样做的风险可能会破坏原来语言模型学到的知识,导致信息遗忘等问题,带来老任务上效果的下降。
Continual Training of Language Models for Few-Shot Learning提出了一种语言模型连续学习的方法解决上述问题。核心思路是借鉴了Adapter,在语言模型中插入多个CL组件(全连接层),模型在目标domain语言上继续学习的过程中,只更新这些CL组件,原始的语言模型保持参数不变。在具体任务上finetune时,语言模型和CL组件一起更新。
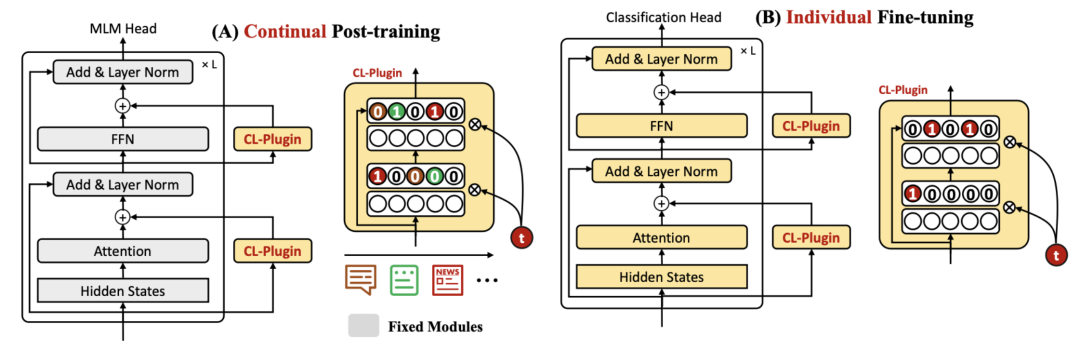
这里面的一个关键模块是使用task id生成CL组件中的mask,每个任务的mask代表了哪些神经元对于当前任务最重要,这些神经元会在后续新任务的训练中被mask掉,不进行梯度更新,防止新任务对老任务已经学到的信息造成影响。每次训练一个新任务时,会把老任务的mask汇总起来控制住不更新的神经元,并且对新的task也学习一套mask。
4 总结
本文主要介绍了3篇EMNLP 2022中和语言模型优化相关的工作,涉及检索、知识提取、持续学习等方面。语言模型在很多场景有各种各样的应用,学术界对于语言模型的优化方向,逐渐从原来的大规模预训练方式、模型结构优化,转向到细领域的针对性优化。
-
算法
+关注
关注
23文章
4810浏览量
98610 -
nlp
+关注
关注
1文章
491浏览量
23346
原文标题:介绍几篇EMNLP'22的语言模型训练方法优化工作
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【大语言模型:原理与工程实践】大语言模型的预训练
Pytorch模型训练实用PDF教程【中文】
基于粒子群优化的条件概率神经网络的训练方法
微软在ICML 2019上提出了一个全新的通用预训练方法MASS

新的预训练方法——MASS!MASS预训练几大优势!

关于语言模型和对抗训练的工作


Multilingual多语言预训练语言模型的套路

混合专家模型 (MoE)核心组件和训练方法介绍



评论