 微软在ICML 2019上提出了一个全新的通用预训练方法MASS
微软在ICML 2019上提出了一个全新的通用预训练方法MASS

微软亚洲研究院的研究员在 ICML 2019 上提出了一个全新的通用预训练方法 MASS,在序列到序列的自然语言生成任务中全面超越 BERT 和 GPT。本文带来论文作者的技术解读。
从 2018 年开始,预训练(pre-train) 毫无疑问成为 NLP 领域最热的研究方向。
借助于 BERT 和 GPT 等预训练模型,人类在多个自然语言理解任务中取得了重大突破。然而,在序列到序列的自然语言生成任务中,目前主流预训练模型并没有取得显著效果。
为此,微软亚洲研究院的研究员在 ICML 2019 上提出了一个全新的通用预训练方法 MASS,在序列到序列的自然语言生成任务中全面超越 BERT 和 GPT。在微软参加的 WMT19 机器翻译比赛中,MASS 帮助中 - 英、英 - 立陶宛两个语言对取得了第一名的成绩。
BERT 在自然语言理解(比如情感分类、自然语言推理、命名实体识别、SQuAD 阅读理解等)任务中取得了很好的结果,受到了越来越多的关注。然而,在自然语言处理领域,除了自然语言理解任务,还有很多序列到序列的自然语言生成任务,比如机器翻译、文本摘要生成、对话生成、问答、文本风格转换等。在这类任务中,目前主流的方法是编码器 - 注意力 - 解码器框架,如下图所示。

编码器 - 注意力 - 解码器框架
编码器(Encoder)将源序列文本 X 编码成隐藏向量序列,然后解码器(Decoder)通过注意力机制(Attention)抽取编码的隐藏向量序列信息,自回归地生成目标序列文本 Y。
BERT 通常只训练一个编码器用于自然语言理解,而 GPT 的语言模型通常是训练一个解码器。如果要将 BERT 或者 GPT 用于序列到序列的自然语言生成任务,通常只有分开预训练编码器和解码器,因此编码器 - 注意力 - 解码器结构没有被联合训练,记忆力机制也不会被预训练,而解码器对编码器的注意力机制在这类任务中非常重要,因此 BERT 和 GPT 在这类任务中只能达到次优效果。
新的预训练方法 ——MASS
专门针对序列到序列的自然语言生成任务,微软亚洲研究院提出了新的预训练方法:屏蔽序列到序列预训练(MASS: Masked Sequence to Sequence Pre-training)。MASS 对句子随机屏蔽一个长度为 k 的连续片段,然后通过编码器 - 注意力 - 解码器模型预测生成该片段。

屏蔽序列到序列预训练 MASS 模型框架
如上图所示,编码器端的第 3-6 个词被屏蔽掉,然后解码器端只预测这几个连续的词,而屏蔽掉其它词,图中 “_” 代表被屏蔽的词。
MASS 预训练有以下几大优势:
(1)解码器端其它词(在编码器端未被屏蔽掉的词)都被屏蔽掉,以鼓励解码器从编码器端提取信息来帮助连续片段的预测,这样能促进编码器 - 注意力 - 解码器结构的联合训练;
(2)为了给解码器提供更有用的信息,编码器被强制去抽取未被屏蔽掉词的语义,以提升编码器理解源序列文本的能力;
(3)让解码器预测连续的序列片段,以提升解码器的语言建模能力。
统一的预训练框架
MASS 有一个重要的超参数 k(屏蔽的连续片段长度),通过调整 k 的大小,MASS 能包含 BERT 中的屏蔽语言模型训练方法以及 GPT 中标准的语言模型预训练方法,使 MASS 成为一个通用的预训练框架。
当 k=1 时,根据 MASS 的设定,编码器端屏蔽一个单词,解码器端预测一个单词,如下图所示。解码器端没有任何输入信息,这时 MASS 和 BERT 中的屏蔽语言模型的预训练方法等价。

当 k=m(m 为序列长度)时,根据 MASS 的设定,编码器屏蔽所有的单词,解码器预测所有单词,如下图所示,由于编码器端所有词都被屏蔽掉,解码器的注意力机制相当于没有获取到信息,在这种情况下 MASS 等价于 GPT 中的标准语言模型。

MASS 在不同 K 下的概率形式如下表所示,其中 m 为序列长度,u 和 v 为屏蔽序列的开始和结束位置,x^u:v 表示从位置 u 到 v 的序列片段,x^\u:v 表示该序列从位置 u 到 v 被屏蔽掉。可以看到,当K=1 或者 m 时,MASS 的概率形式分别和 BERT 中的屏蔽语言模型以及 GPT 中的标准语言模型一致。

我们通过实验分析了屏蔽 MASS 模型中不同的片段长度(k)进行预训练的效果,如下图所示。
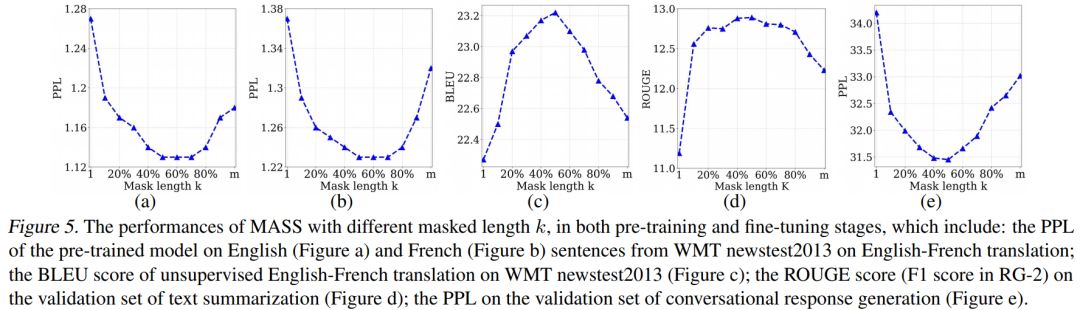
当 k 取大约句子长度一半时(50% m),下游任务能达到最优性能。屏蔽句子中一半的词可以很好地平衡编码器和解码器的预训练,过度偏向编码器(k=1,即 BERT)或者过度偏向解码器(k=m,即 LM/GPT)都不能在该任务中取得最优的效果,由此可以看出 MASS 在序列到序列的自然语言生成任务中的优势。
序列到序列自然语言生成任务实验
预训练流程
MASS 只需要无监督的单语数据(比如 WMT News Crawl Data、Wikipedia Data 等)进行预训练。MASS 支持跨语言的序列到序列生成(比如机器翻译),也支持单语言的序列到序列生成(比如文本摘要生成、对话生成)。当预训练 MASS 支持跨语言任务时(比如英语 - 法语机器翻译),我们在一个模型里同时进行英语到英语以及法语到法语的预训练。需要单独给每个语言加上相应的语言嵌入向量,用来区分不同的语言。我们选取了无监督机器翻译、低资源机器翻译、文本摘要生成以及对话生成四个任务,将 MASS 预训练模型针对各个任务进行精调,以验证 MASS 的效果。
无监督机器翻译
在无监督翻译任务上,我们和当前最强的 Facebook XLM 作比较(XLM 用 BERT 中的屏蔽预训练模型,以及标准语言模型来分别预训练编码器和解码器),对比结果如下表所示。
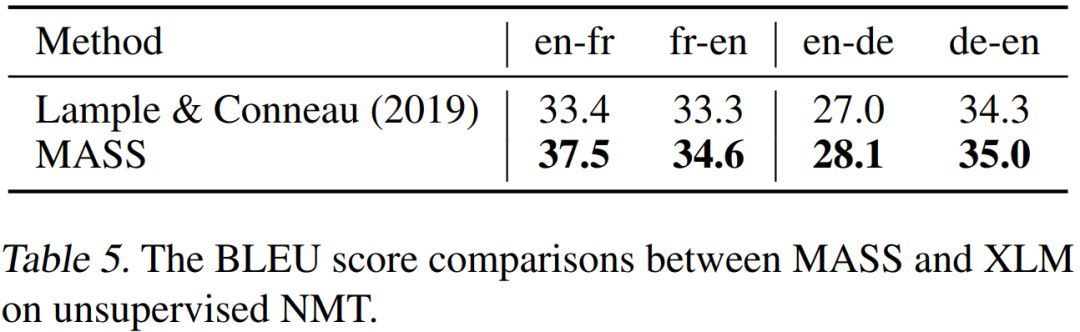
可以看到,MASS 的预训练方法在 WMT14 英语 - 法语、WMT16 英语 - 德语一共 4 个翻译方向上的表现都优于 XLM。MASS 在英语 - 法语无监督翻译上的效果已经远超早期有监督的编码器 - 注意力 - 解码器模型,同时极大缩小了和当前最好的有监督模型之间的差距。
低资源机器翻译
低资源机器翻译指的是监督数据有限情况下的机器翻译。我们在 WMT14 英语 - 法语、WMT16 英语 - 德语上的不同低资源场景上(分别只有 10K、100K、1M 的监督数据)验证我们方法的有效性,结果如下所示。
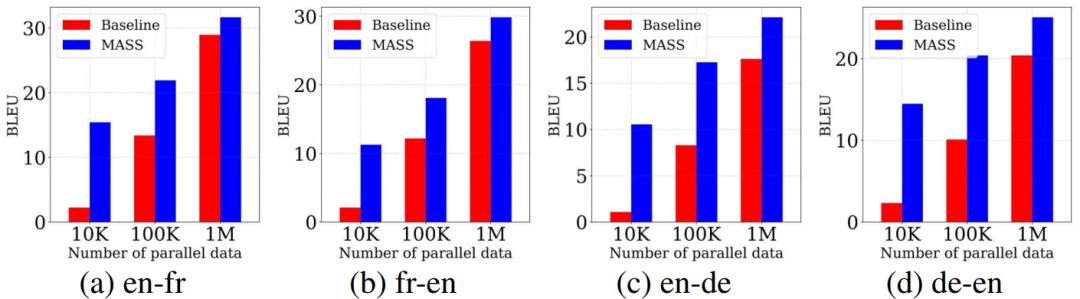
在不同的数据规模下,我们的预训练方法的表现均比不用预训练的基线模型有不同程度的提升,监督数据越少,提升效果越显著。
文本摘要生成
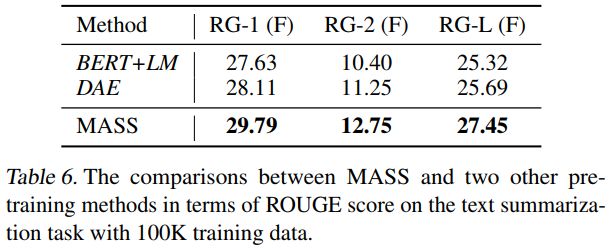
在文本摘要生成(Gigaword Corpus)任务上,我们将 MASS 同 BERT+LM(编码器用 BERT 预训练,解码器用标准语言模型 LM 预训练)以及 DAE(去噪自编码器)进行了比较。从下表可以看到,MASS 的效果明显优于 BERT+LM 以及 DAE。
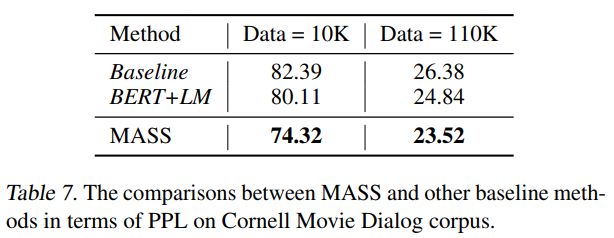
对话生成
在对话生成(Cornell Movie Dialog Corpus)任务上,我们将 MASS 同 BERT+LM 进行了比较,结果如下表所示。MASS 的 PPL 低于 BERT+LM。
在不同的序列到序列自然语言生成任务中,MASS 均取得了非常不错的效果。接下来,我们还将测试 MASS 在自然语言理解任务上的性能,并为该模型增加支持监督数据预训练的功能,以期望在更多自然语言任务中取得提升。未来,我们还希望将 MASS 的应用领域扩展到包含语音、视频等其它序列到序列的生成任务中。
-
微软
+关注
关注
4文章
6766浏览量
108178 -
编码器
+关注
关注
45文章
4028浏览量
143791 -
自然语言
+关注
关注
1文章
293浏览量
14049
原文标题:【ICML 2019】微软最新通用预训练模型MASS,超越BERT、GPT!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
后摩智能三篇论文入选ACL和ICML两大人工智能顶会

百度发布文心5.1:预训练成本降至行业6%
VirtualLab Fusion:基于微软专利的蝴蝶型出瞳扩展光导
川土微电子推出CA-IS1200C系列全新一代通用隔离式运放

无法启动预安装的 Ubuntu 23.10 服务器映像怎么解决?
在deepin 25上安装OpenClaw的步骤及飞书接入方法

是否可以将 Vision Five 2 配置为 SuperSpeed 上的 USB 3.0 mass_storage小工具?
微软全新AI超级工厂Fairwater在亚特兰大落成
喜报|华微软件AI研发持续推进,再添一项核心专利

在Ubuntu20.04系统中训练神经网络模型的一些经验
微软Visual Studio 2026 发布!AI 深度融合、性能提升

基于大规模人类操作数据预训练的VLA模型H-RDT

【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
树莓派5上的Gemma 2:如何打造高效的边缘AI解决方案?




评论