 聚焦“源1.0”背后的计算挑战以及我们采取的训练方法
聚焦“源1.0”背后的计算挑战以及我们采取的训练方法

从2018年的BERT到2020年的GPT-3,NLP语言模型经历了爆发式的发展过程,其中BERT模型的参数量为3.4亿,而GPT-3的模型参数量达到了1750亿。2021年9月,浪潮发布了“源1.0”,它是目前规模最大的中文AI单体模型,参数规模高达2457亿,训练采用的中文数据集达5TB。“源1.0”在语言智能方面表现优异,获得中文语言理解评测基准CLUE榜单的零样本学习和小样本学习两类总榜冠军。测试结果显示,人群能够准确分辨人与“源1.0”作品差别的成功率低于50%。
海量的参数带来了模型训练和部署上的巨大挑战。本文将聚焦“源1.0”背后的计算挑战以及我们采取的训练方法。
“源1.0”的模型结构
“源1.0”是一个典型的语言模型。语言模型通俗来讲就是能够完成自然语言理解或者生成文本的神经网络模型。对于“源1.0”,我们考虑语言模型(Language Model,LM)和前缀语言模型(Prefix Language Model,PLM)两种模型结构。如下图所示:
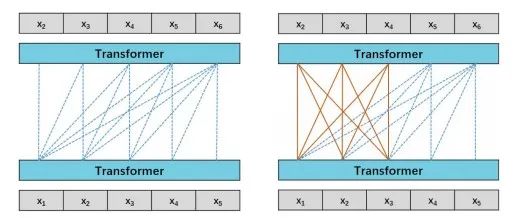
图1 模型结构示意图(左图为LM,右图为PLM)
我们比较了130亿参数的LM和PLM在不同下游任务上的结果,注意到LM在Zero-Shot和Few-Shot上表现更好,而PLM在微调方面表现出色。微调通常会在大多数任务中带来更好的准确性,然而微调会消耗大量的计算资源,这是不经济的。所以我们选择LM作为“源 1.0”模型的基础模型结构。
►
如何训练“源1.0”
| 源1.0训练面对的挑战
“源1.0”的训练需要面对的第一个挑战就是数据和计算量的挑战。
数据方面,如果把训练一个巨量模型的训练过程比作上异常战役的话,那么数据就是我们的弹药。数据量的多少,决定了我们可以训练模型的规模,以及最后的效果。针对这一方面,我们构建了一个全新的中文语料库,清洗后的高质量数据规模达到了5TB,是目前规模最大的中文语料库。
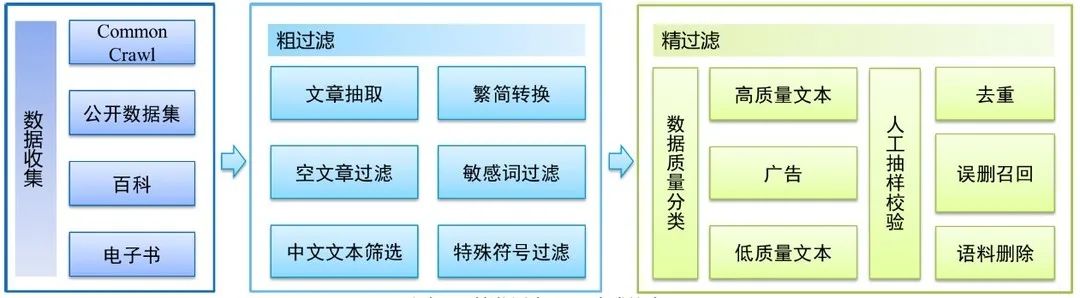
图2 数据预处理流程图
算力方面,根据OpenAI提出的PetaFlop/s-day衡量标准,我们可以估算“源1.0”训练的计算需求情况。根据Wikipedia提供的数据(https://en.wikipedia.org/wiki/OpenAI),GPT-3的计算需求约为3640 PetaFlop/s-day,而“源1.0”的计算需求达到了4095 PetaFlop/s-day。
计算资源的巨大开销是限制研究人员研发具有数以千万计参数的NLP大模型的瓶颈。例如GPT-3是在由10000个GPU所组成的集群上训练得到的。我们在设计“源1.0”的模型结构时,考虑到了影响大规模分布式训练的关键因素,采用了专门的分布式训练策略,从而加速了模型的训练过程。
在模型训练时一般最常用的是采用数据并行分布式计算策略,但这只能满足小模型的训练需求。对于巨量模型来说,由于其模型参数量过大,远远超过常用计算设备比如GPU卡的显存容量,因此需要专门的算法设计来解决巨量模型训练的显存占用问题,同时还需要兼顾训练过程中的GPU计算性能的利用率。
| “源1.0”的训练策略
为了解决显存不足的问题,我们采用了张量并行、流水并行、数据并行相结合的并行策略,实现了在2128个GPU上部署“源1.0”,并完成了1800亿tokens的训练。
a. 张量并行
针对单个GPU设备不能完整的承载模型训练,一个解决方案就是张量并行+数据并行的2D并行策略。具体来说,使用多个GPU设备为1组,比如单个服务器内的8个GPU为1组,组内使用张量并行策略对模型进行拆分,组间(服务器间)采用数据并行。
对于张量并行部分,NVIDIA在Megatron-LM中提出了针对Transformer结构的张量并行解决方案。其思路是把每一个block的参数和计算都均匀的拆分到N个GPU设备上,从而实现每个GPU设备都承担这一block的参数量和计算量的1/N效果。图3展示了对Transformer结构中的MLP层和self-attention层进行张量并行拆分计算的过程示意图。
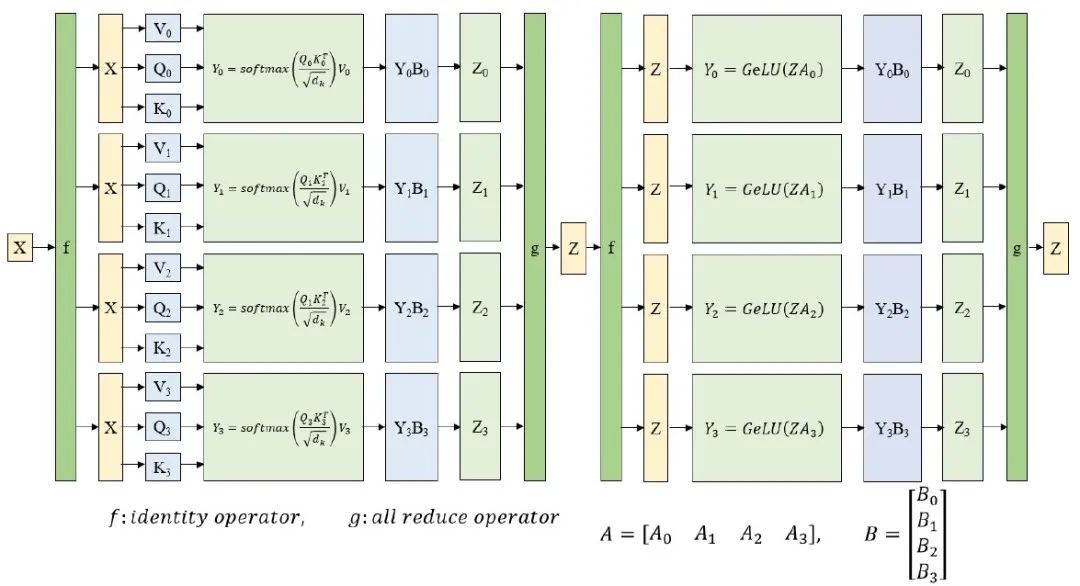
图3 张量并行示意图
在训练过程中,tensor经过每一层的时候,计算量与通信数据量之比 如下:
如下:
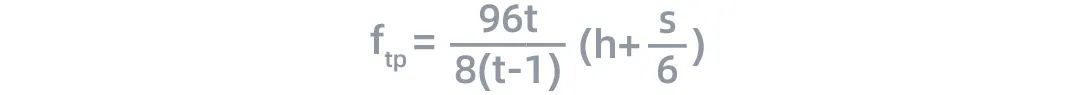
其中,S为输入序列的长度,h为隐藏层的大小(hidden size)。
b. 流水并行

图4 流水线并行示意图
对于具有数千亿参数的语言模型,这些参数很难被存放在单个节点中。流水线并行将LM的层序列在多个节点之间进行分割,以解决存储空间不足的问题,如图5所示。每个节点都是流水线中的一个阶段,它接受前一阶段的输出并将结果过发送到下一阶段。如果前一个相邻节点的输出尚未就绪,则当前节点将处于空闲状态。节点的空闲时间被称为流水线气泡(pipline bubble)。为了提高流水行并行的性能,我们必须尽可能减少在气泡上花费的时间。定义流水线中气泡的理想时间占比为如下形式:
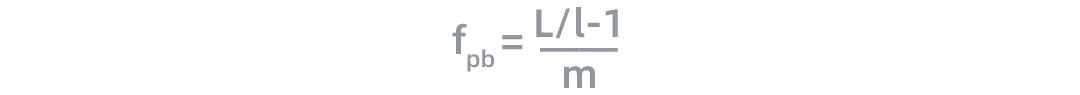
根据这一公式,流水线气泡的耗时随着层数L的增加而增加,随着微批次大小(micro-batch-size)的增加而减小。当m≫L/l的时候,流水并行过程中的流水线气泡对训练性能的影响几乎可以忽略。
与此同时,在流水并行过程中,节点间的计算量与通信数据量之比为:
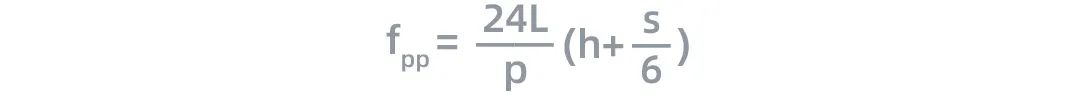
根据上面的公式,流水线中节点的计算效率与h和S呈线性关系,这与张量并行类似。
c. 数据并行
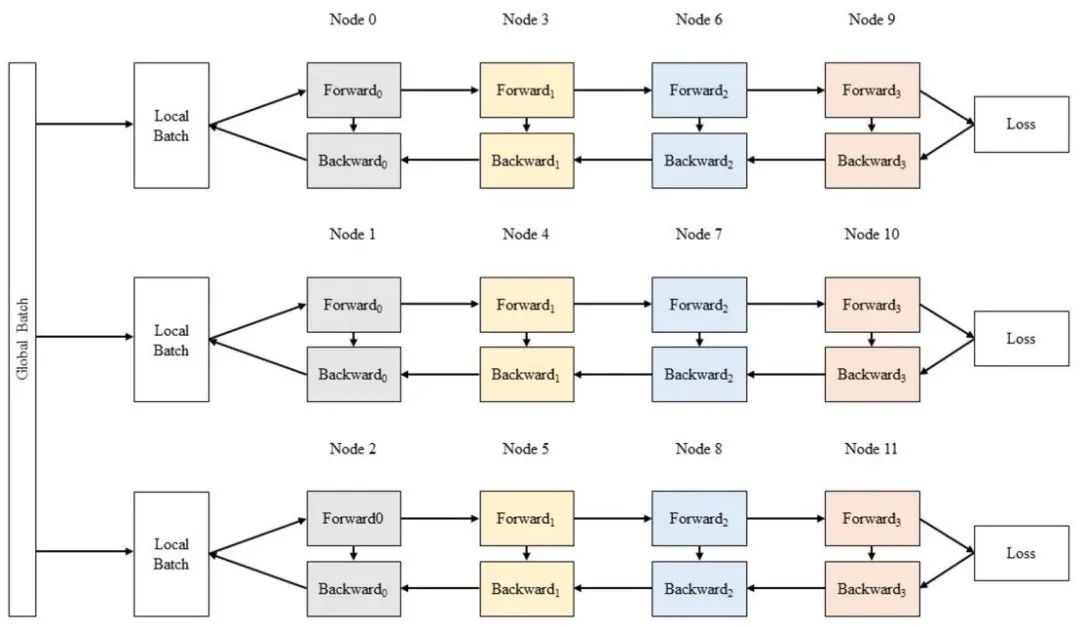
图6 数据并行示意图
采用数据并行时,全局批次大小(global batch size)按照流水线分组进行分割。每个流水线组都包含模型的一个副本,数据在组内按照局部批次规模送入模型副本。数据并行时的计算量与通信数据量的比值可用如下公式近似:
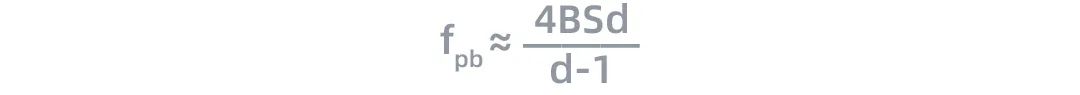
当d≫ 1时,上面公式可以进一步简化成:

根据这一公式,我们可以看出数据并行的计算效率与全局批次大小B和序列长度S呈正比关系。由于模型对内存的需求与S的平方成正比,与B成线性关系,因此增加全局批次大小可以更有效的提升数据并行的效率。
当全局批次大小过大的时候,模型很容易出现不收敛的问题,为了保证模型训练过程的稳定性,我们将全局批次大小限制在了10^7个token内。
根据以上的理论分析,我们确定了设计“源1.0”巨量模型结构的基本原则:
尽可能增加序列长度,因为它有利于张量并行、流水线并行和数据并行。由于内存占用与序列长度的平方成正比,因此有必要在反向传播时重新计算激活函数,以节省内存开销;
语言模型中层数太多会对性能产生负面影响,因为这会增加在流水线气泡上的时间消耗;
增加隐藏层大小可以提高张量并行和流水线并行的性能;
增加节点中的微批次大小可以提高流水线并行效率,增加全局批次大小可以提升数据并行的效率;
在这一设计原则的基础上,我们设计的“源1.0”的模型结构以及分布式策略的设置如下表所示:

结合模型结构的特性以及我们使用集群的硬件特性,我们如下的节点配置和分布式策略选择:
“源1.0”模型在训练过程中共使用了2128个GPU;
模型分成了7组,每组38台AI服务器,里面放置一个完整的“源1.0”模型,7组之间采用数据并行;
每组的38个服务器,采用流水并行每个服务器放置1/38的模型(2个Transformer Layer),一共76层;
在每台服务器内采用张量并行,按照Transformer结构的每一层进行均匀切分;
模型收敛曲线如下图:
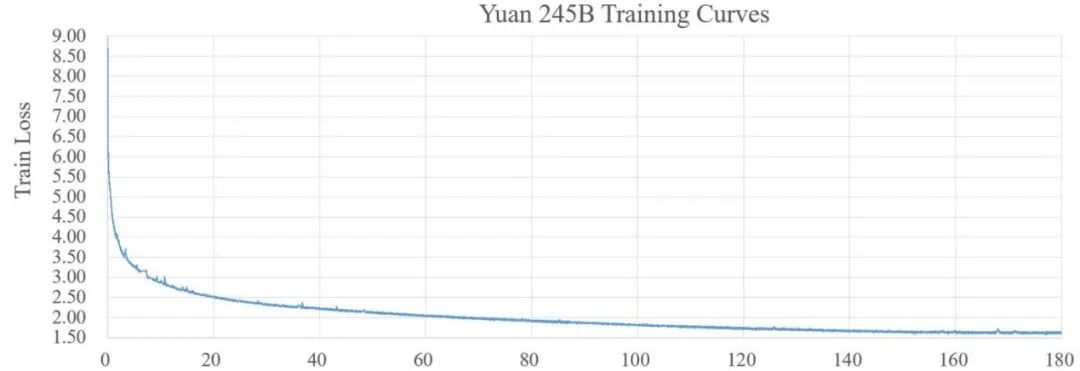
关于“源1.0”的更多信息,大家可以参照浪潮发布在arxiv上的论文:https://arxiv.org/abs/2110.04725
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4846浏览量
108383 -
模型
+关注
关注
1文章
3874浏览量
52341 -
语言模型
+关注
关注
0文章
575浏览量
11372
原文标题:如何训练2457亿参数量的中文巨量模型“源1.0”
文章出处:【微信号:浪潮AIHPC,微信公众号:浪潮AIHPC】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
惠伦晶体创新打造1.0×0.8mm超小型无源晶体
[GLAD] GLAD应用:高斯光束的吸收和自聚焦效应
线性偏振光纤模式
泰克专家探讨类脑计算背后的器件逻辑与现实挑战
摩尔线程发布SimuMax v1.1:从仿真工具升级为全栈工作流平台,助力大模型训练提效
亚太地区AI数据中心可持续发展面临重重挑战

重要通知 | Splashtop 即将停止支持 TLS 1.0/1.1

摩尔线程发布大模型训练仿真工具SimuMax v1.0

【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
大模型推理显存和计算量估计方法研究
GLAD应用:高斯光束的吸收和自聚焦效应
华为发布天才少年挑战课题发布 五大主题方向课题放榜
OCR识别训练完成后给的是空压缩包,为什么?
高性能计算面临的芯片挑战




评论